

In brief
- OpenAI launched GPT-5.4 Mini and Nano, two faster and cheaper models designed for high-volume AI workloads.
- The models trade a bit of accuracy for speed and cost, targeting tasks repetitive and easy tasks like customer support, and automated workflows.
- Developers can now run hybrid AI systems where a flagship model plans tasks while smaller models handle the bulk of the work.
OpenAI isn't slowing down. Less than two weeks after launching GPT-5.4—itself released just two days after GPT-5.3—the company dropped two more models on Tuesday: GPT-5.4 Mini and GPT-5.4 Nano.
These aren't stripped-down versions of the flagship model—they're purpose-built machines designed for the kind of work where waiting half a minute for an answer is not an option.
OpenAI calls them its “most capable small models yet,” saying that GPT-5.4 Mini is more than two times faster than GPT-5 Mini. If you've ever watched a coding assistant think for 45 seconds before editing three lines of code, then you understand the appeal of a fast model.
We’re introducing GPT-5.4 mini and nano, our most capable small models yet.
GPT-5.4 mini is more than 2x faster than GPT-5 mini. Optimized for coding, computer use, multimodal understanding, and subagents.
For lighter-weight tasks, GPT-5.4 nano is our smallest and cheapest… pic.twitter.com/cdp5HWtM2M
— OpenAI Developers (@OpenAIDevs) March 17, 2026
So why would anyone release a less accurate model on purpose? The short answer: because accuracy isn't always the bottleneck. If you're running a customer service chatbot that answers the same 200 questions all day, then you don't need the model that scored best on PhD-level chemistry exams. You need the one that responds in under a second and costs a fraction of a cent per reply. That's the space these models are built for.
But it doesn’t mean these models are dumb or unreliable. On coding benchmarks, GPT-5.4 Mini scored 54.4% on SWE-Bench Pro—a test that measures a model's ability to fix real GitHub issues—compared to 45.7% for the old GPT-5 Mini and 57.7% for the full GPT-5.4.
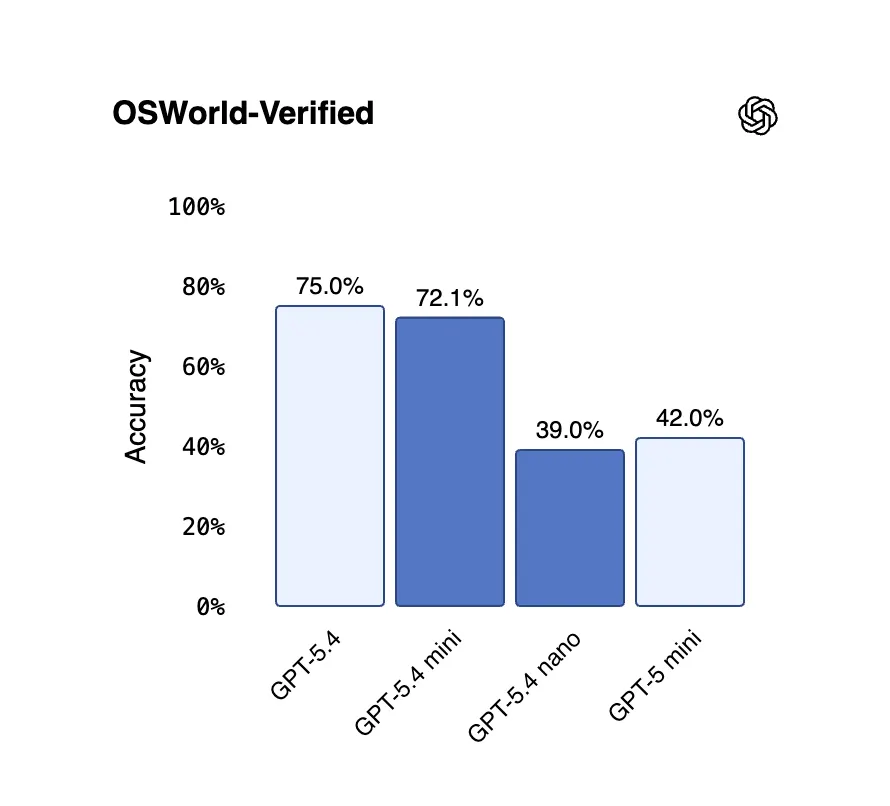
On OSWorld-Verified, which tests how well a model can actually operate a desktop computer by reading screenshots, Mini hit 72.1%, just shy of the flagship's 75.0%—and both clear the human baseline of 72.4%. GPT-5.4 Nano, meanwhile, scores 52.4% on SWE-Bench Pro and 39.0% on OSWorld—lower than Mini, but still a major leap over previous Nano-class models.
"GPT-5.4 marks a step forward for both Mini and Nano models in our internal evaluations,” Perplexity Deputy CTO Jerry Ma said after testing both. “Mini delivers strong reasoning, while Nano is responsive and efficient for live conversational workflows."
Instead of routing every single task through an expensive flagship model, you can now build systems where the big model plans and coordinates while smaller models handle the actual grunt work in parallel—searching a codebase here, reading a document there, or processing a form somewhere else. As we saw in our GPT-5.4 vs. Grok 4.20 comparison, where the model sits in the workflow matters as much as which model you pick.
GPT-5.4 Mini runs at a rate of $0.75 per million input tokens and $4.50 per million output tokens via the API. GPT-5.4 Nano is even cheaper: $0.20 per million input tokens and $1.25 per million output tokens—a price point that makes running a huge amount of queries per day financially realistic for startups. For context, Nano is roughly four times cheaper than Mini on inputs.
For regular ChatGPT users, GPT-5.4 Mini is available today to Free and Go users via the "Thinking" option in the plus menu. Paid subscribers who hit their GPT-5.4 rate limits will automatically fall back to Mini. GPT-5.4 Nano, however, is API-only for now—OpenAI is clearly positioning it as a developer tool, not a consumer one.