

En Resumen
- Z.ai lanzó GLM-5.2, un modelo de 744B parámetros entrenado con chips Huawei Ascend por aproximadamente $25 millones.
- El modelo alcanzó 74,4 en FrontierSWE, casi igualando el 75,1 de Claude Opus 4.8 y superando a GPT-5.5.
- Las acciones de Z.ai subieron 90% en una semana, impulsadas por el lanzamiento y la prohibición de Claude Fable.
Z.ai lanzó GLM-5.2 el 16 de junio, prometiendo rendimiento de primer nivel, superando a su ya avanzado GLM 5.1.
El laboratorio con sede en Pekín, que ha estado en la Lista de Entidades de EE.UU. desde enero de 2025, parece estar beneficiándose de las crecientes preocupaciones sobre el enfoque de Estados Unidos hacia la IA. Durante la última semana, la prohibición de Anthropic Fable y el lanzamiento de este nuevo modelo han ayudado a impulsar las acciones de zAI un 90%, llevándolas a un nuevo máximo histórico.
GLM 5.2 tiene los números para respaldar las expectativas.
En FrontierSWE—un benchmark que evalúa si un agente de IA puede completar proyectos técnicos abiertos medidos en horas, cubriendo optimización de sistemas, construcción de código a gran escala e investigación aplicada de ML, puntuado por tasa de dominancia—GLM-5.2 alcanzó 74,4 frente al 75,1 de Claude Opus 4.8. Superó al GPT-5.5 con 72,6. En SWE-bench Pro, que evalúa la resolución autónoma de issues reales de GitHub puntuada como tasa de aprobación, GLM-5.2 obtuvo 62,1 frente al 58,6 de GPT-5.5—y superó por un amplio margen el 58,4 de su predecesor GLM-5.1.
El salto de calidad lo convierte en el mejor modelo de código abierto hasta la fecha en el Artificial Analysis Intelligence Index, que agrega los resultados de 9 puntuaciones diferentes para evaluar la calidad general de un modelo de IA. Los benchmarks de OpenRouter lo colocan en la misma categoría que el ahora prohibido Claude Fable 5.
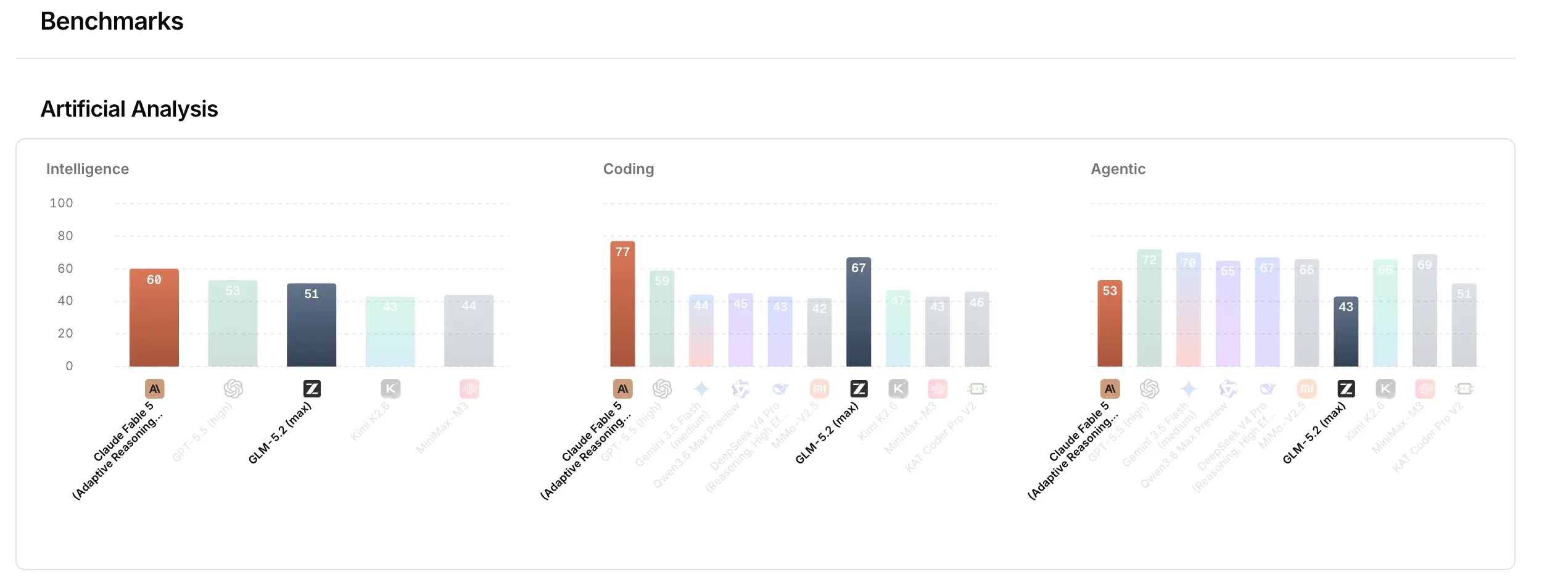
El hardware utilizado para lograr esta hazaña es otra parte interesante de la historia. GLM-5.2 fue entrenado con chips Huawei Ascend—sin Nvidia en ninguna parte del proceso. Emad Mostaque, fundador de Stability AI, estimó que los costos totales de entrenamiento rondaron los $25 millones, el 80% de eso en post-entrenamiento, lo que lo haría extremadamente barato en comparación con sus pares.
Como reportó Decrypt a principios de este año, Z.ai ya estaba entrenando modelos de imagen en servidores Huawei Ascend Atlas sin un solo chip estadounidense. GLM-5.2 lleva esa infraestructura más allá—un modelo de mezcla de expertos de 744.000 millones de parámetros con una ventana de contexto genuina de 1 millón de tokens, cinco veces el límite de 200K de GLM-5.1, y una licencia MIT que significa que ninguna directiva gubernamental puede cortar el acceso.
Los tokens son los fragmentos de texto que un modelo puede leer y generar, mientras que los parámetros son el número de configuraciones y valores internos que determinan cómo un modelo procesa información y genera respuestas.
Para quién es y cuánto cuesta
Para los desarrolladores, la ventana de contexto es el cambio operativo. Navegación de repositorios completos, refactorizaciones de múltiples archivos y pipelines agénticos largos que anteriormente requerían fragmentación se convierten en flujos de trabajo de una sola llamada. El precio de la API es de $1,40 por millón de tokens de entrada y $4,40 por millón de salida—frente a los $5 de entrada y $25 de salida de Claude Opus 4.8. El Coding Plan comienza en alrededor de $18 al mes y funciona directamente dentro de Claude Code, Cline, Kilo Code y la mayoría de los entornos agénticos populares.
El despliegue local también es técnicamente posible. Unsloth AI publicó cuantizaciones GGUF de 2 bits que comprimen el modelo de 1,51 TB a 238 GB manteniendo ~82% de precisión.
Sin embargo, no hay que emocionarse demasiado. Eso sigue significando que demanda 256 GB de memoria unificada o una combinación equivalente de RAM/VRAM—un Mac Studio M4 Ultra al máximo o una estación de trabajo con una GPU de gama media y 256 GB de RAM del sistema con offloading de mezcla de expertos. Sigue siendo mucho dinero, pero al menos es algo que puedes comprar y ejecutar en tu casa si realmente quieres.
Realizamos una prueba rápida, pidiéndole a GLM-5.2 que construyera nuestro juego estándar que mezcla mecánicas de escritura con un shooter. La interfaz no fue la más bonita—otros modelos generaron interfaces más pulidas, pero la experiencia fue la más variada: diferentes escenarios a lo largo de las oleadas, tipos de enemigos que cambiaban, jefes apareciendo más adelante en la partida.
Generó estados de juego más diversos que cualquier otra cosa que probamos para la misma tarea en una configuración de zero shot.
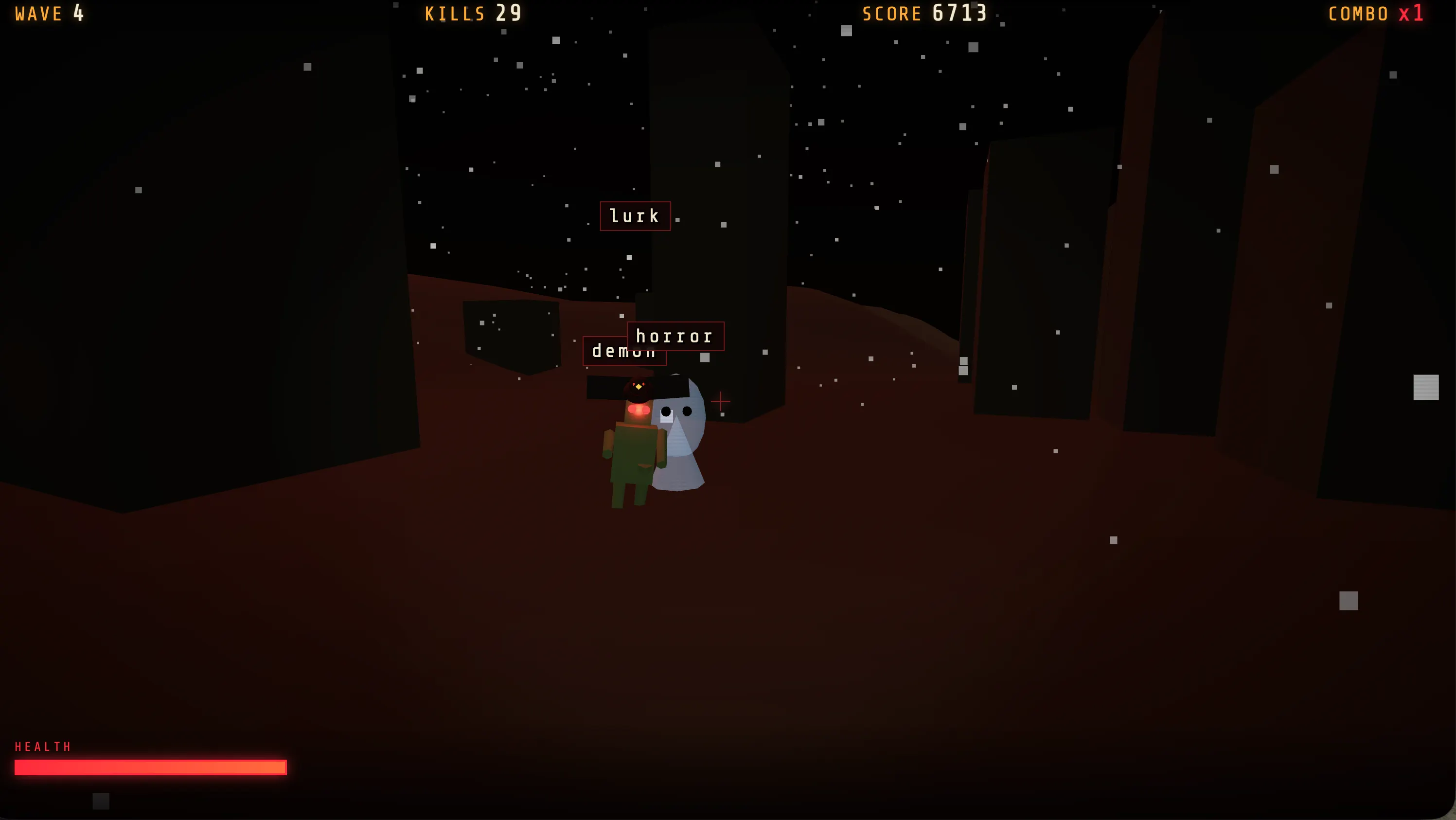
Si quieres jugarlo, está disponible en nuestro perfil de Itch.io.
Esa variedad apunta hacia donde GLM-5.2 tiene más sentido económico. Para flujos de trabajo de generación multi-shot y pipelines agénticos donde la diversidad de salida importa más que el pulido, las cuentas a precios de código abierto son difíciles de rebatir. Para las tareas sostenidas más difíciles—SWE-Marathon, donde obtiene 13,0 frente al 26,0 de Opus 4.8—la brecha con la frontera cerrada sigue siendo real, y de 13 puntos.
Los pesos de código abierto están disponibles en HuggingFace bajo la licencia MIT. Los pesos cuantizados también están disponibles en HuggingFace. Los suscriptores del GLM Coding Plan pueden cambiar ahora con el model string GLM-5.2, y también está disponible para pruebas gratuitas en z.AI con algunas restricciones de uso.