

En Resumen
- Investigadores de Nvidia, Carnegie Mellon y UC Berkeley presentaron ENPIRE, un marco que permite a agentes de IA entrenar robots sin supervisión humana.
- El sistema redujo el tiempo de dominio de tareas como Push-T de cinco horas a dos al escalar de uno a ocho robots simultáneos.
- Jim Fan de Nvidia señaló que el proyecto habilita "AutoResearch" en el mundo físico, con una tasa de éxito del 99% en pruebas reales.
Un grupo de ocho brazos robóticos en el laboratorio GEAR de Nvidia pasó las últimas semanas enseñándose a sí mismos a insertar pines, colocar tarjetas gráficas y cortar bridas. Los únicos humanos involucrados fueron aquellos que escribieron el artículo posteriormente.
La habilidad provino de ENPIRE, un marco detallado en un artículo publicado el martes por investigadores de Nvidia, la Universidad Carnegie Mellon y UC Berkeley. ENPIRE delega toda la tarea de entrenar a un robot a agentes de codificación de IA, el mismo software que ya escribe y prueba su propio código, y les permite ejecutar ese proceso directamente en hardware físico.
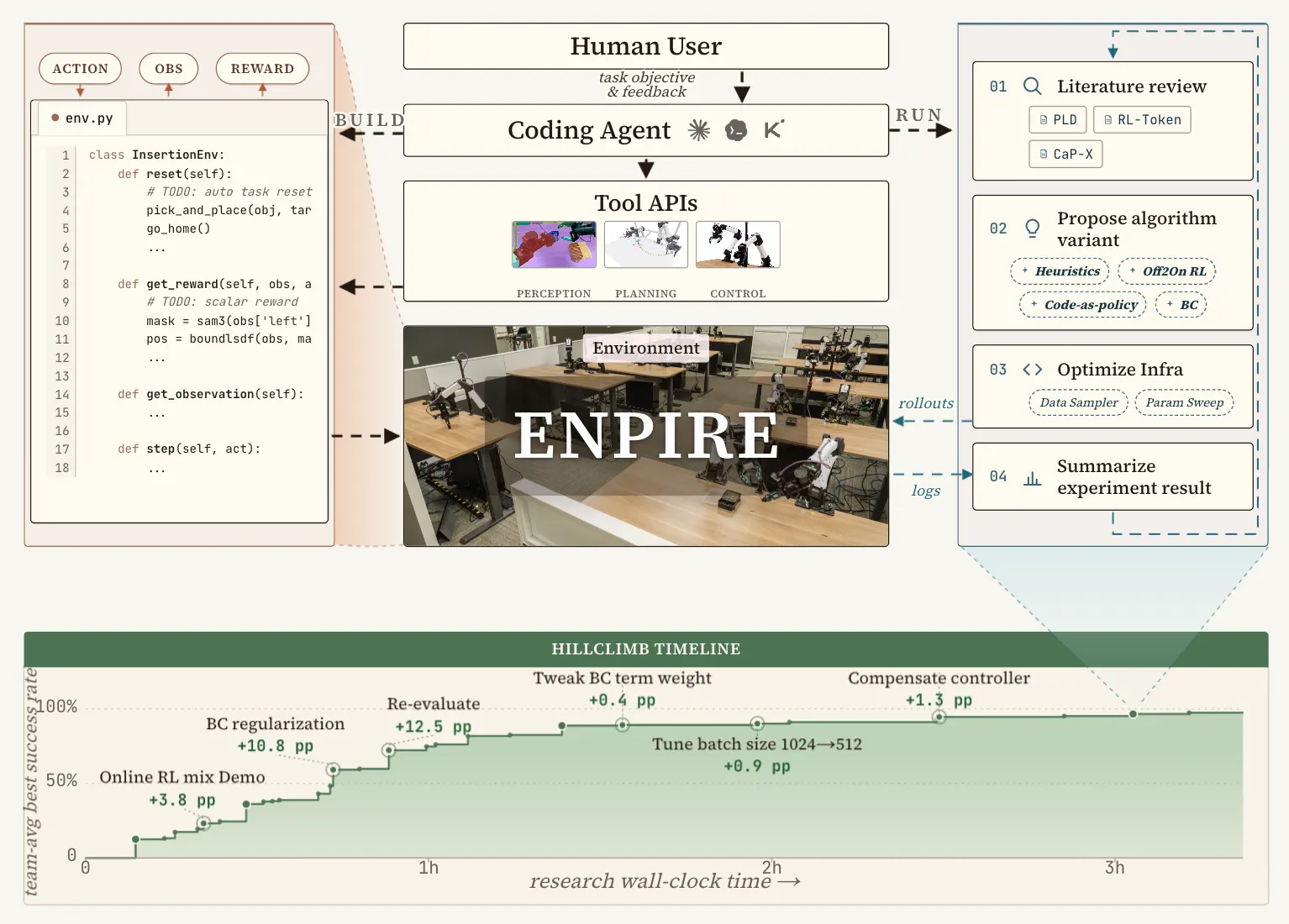
Agentes de codificación como Codex de OpenAI, Claude Code de Anthropic y Kimi Code de Moonshot han pasado el último año realizando lo que los investigadores llaman autoinvestigación: escribir código, probarlo y volver a escribirlo sin intervención humana. Ese ciclo ha permanecido principalmente en una pantalla, donde reiniciar un experimento fallido no cuesta nada. ENPIRE lo lleva al mundo físico, donde reiniciar un experimento implica mover un brazo de robot real.
Construyendo el 'Enpire'
El sistema divide el trabajo en dos etapas. En la primera, un humano guía al agente a través de la construcción de dos herramientas permanentes: una rutina de reinicio que devuelve el espacio de trabajo a una posición de inicio fresca, y una función de recompensa que observa las imágenes de la cámara para puntuar el éxito, básicamente un árbitro que nunca parpadea y nunca se toma un descanso para almorzar. Esa configuración ocurre una vez, y luego se reutiliza para cada intento que sigue.
Una vez que existen esas herramientas, el agente toma el control por completo. Busca investigaciones publicadas para obtener ideas, elige entre métodos de entrenamiento como el aprendizaje por imitación, el aprendizaje por refuerzo o reglas escritas a mano, luego reescribe su propio código y prueba el resultado en el robot. Nada en ese ciclo requiere que una persona observe, lo cual es liberador o ligeramente inquietante dependiendo de cómo te sientas acerca de un robot sosteniendo tijeras sin supervisión.
Nvidia realizó el experimento en ocho estaciones de robots bimanuales, cada una con su propio hardware, computadora y agente de codificación. Las estaciones intercambian progreso a través de Git, la misma herramienta que usan los programadores para fusionar código, por lo que una idea ganadora se propaga por toda la flota en cuestión de minutos.
Investigadores midieron la recompensa en “Push-T”, una tarea donde un robot desliza un bloque en forma de T en una zona objetivo usando solo empujes, y la inserción de clavijas, donde enrosca clavijas en agujeros de 4 milímetros. Escalar de un robot a ocho redujo el tiempo para dominar Push-T de aproximadamente cinco horas a dos, y la inserción de clavijas de más de 90 minutos a unos 40.

En las cuatro tareas del mundo real probadas, los agentes llevaron sus políticas a una tasa de éxito del 99%, según el documento. Para la inserción de clavijas, los agentes alcanzaron una confiabilidad casi perfecta más rápido que un método comparable con humanos en el ciclo, el tipo que aún necesita que alguien se presente todas las mañanas.
Jim Fan de Nvidia, el co-líder del GEAR Lab que dirige la investigación de IA de la empresa, calificó el proyecto como un esfuerzo para habilitar AutoResearch en el mundo físico por primera vez. Fan dijo que el equipo entregó a los agentes una flota de robots, una asignación de GPU y un presupuesto de tokens, luego se retiró y dejó que los robots se hicieran cargo.
Today, we enable AutoResearch in the physical world for the first time! Introducing ENPIRE: we give 8 Codex agents a fleet of robots, an allocation of GPUs, and generous token budget. We set them free with a simple goal: solve the task as quickly as possible, keep the robots busy… pic.twitter.com/zC0OQNzDBs
— Jim Fan (@DrJimFan) June 16, 2026
La brecha entre la simulación y la realidad se mostró casi de inmediato. Los tres agentes de codificación resolvieron Push-T dentro de un simulador, pero dos de los tres fallaron una vez que la misma tarea se trasladó a un robot físico, señala el documento.
Los simuladores no tienen problemas de fricción. Las mesas reales sí.
Nvidia también probó ENPIRE dentro de RoboCasa, un banco de pruebas de cocina simulado que califica a los robots en tareas como abrir armarios o apagar estufas por tasa de éxito, afortunadamente sin riesgo de incendiar el lugar. Allí, ENPIRE superó tanto al modelo de extremo a extremo GR00T de Nvidia como a CaP-X, un agente que utiliza herramientas que omite por completo el bucle de autopesquisa.
ENPIRE amplía una idea que Nvidia propuso por primera vez con Eureka, un sistema de 2023 que utilizaba un modelo de lenguaje para escribir funciones de recompensa para robots dentro de un simulador en lugar de que los ingenieros humanos lo hicieran manualmente. ENPIRE traslada ese bucle de auto-mejora del simulador al hardware real, con el agente diseñando sus propias pruebas en lugar de solo sus propias recompensas.
La publicación llega la misma semana en que Alibaba presentó su propio impulso de IA incorporada, la Suite de Robots Qwen, un trío de modelos fundamentales para la navegación, manipulación y simulación física de robots. Alibaba está construyendo cerebros de software para cuerpos de robots que no fabrica; Nvidia está probando si los agentes pueden ejecutar todo el ciclo de investigación en hardware que posee de principio a fin. Ambos apuntan a la misma tendencia: los robots físicos se están convirtiendo en la próxima arena para que los agentes de codificación compitan.