

En Resumen
- Grok-3 domina la escritura creativa al superar a Claude 3.5 Sonnet en narrativa, con personajes sólidos y una trama más envolvente.
- Es menos censurado y más neutral en política, abordando temas sensibles sin negarse a responder ni inclinarse hacia un sesgo ideológico evidente.
- Supera en programación, pero no en matemáticas, generando código funcional mejor que sus rivales, aunque sigue detrás de OpenAI y DeepSeek en razonamiento matemático avanzado.
xAI acaba de lanzar Grok-3 y ya está agitando el mundo de la IA, moviéndose en una compleja carrera armamentística provocada por el explosivo debut de DeepSeek en enero.
Durante la presentación, el equipo de xAI presumió de prestigiosos puntos de referencia cuidadosamente seleccionados, mostrando el dominio del razonamiento de Grok-3 sobre sus rivales, especialmente después de convertirse en el primer Large Language Model (LLM) en superar los 1.400 puntos ELO en LLM Arena, posicionándose como el mejor LLM según la preferencia de los usuarios.
¿Atrevido? Absolutamente. Pero cuando la persona que ayudó a redefinir los vuelos espaciales y los coches eléctricos dice que su IA es la mejor de todas, no puedes simplemente asentir y seguir adelante.
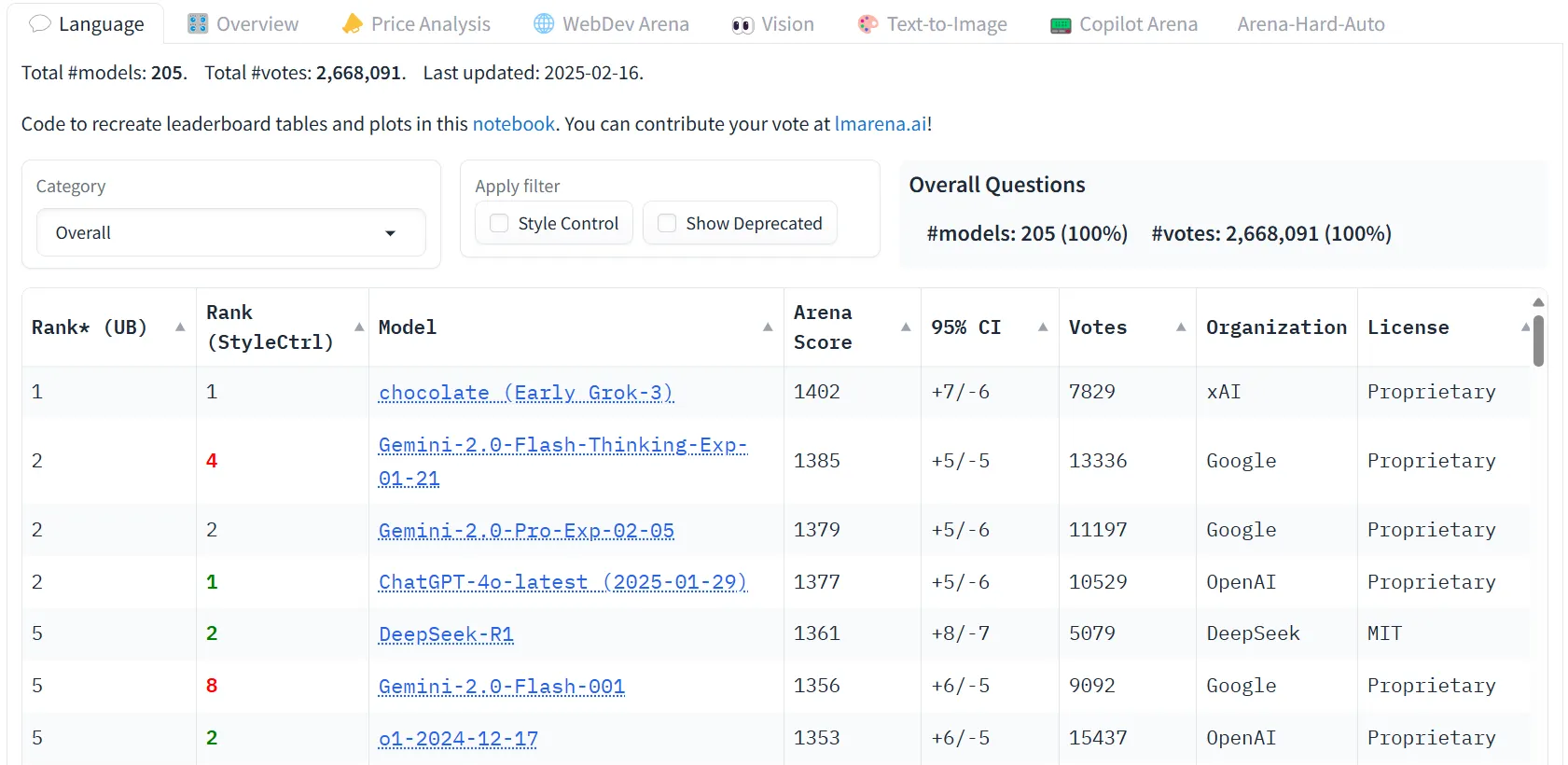
Tuvimos que verlo por nosotros mismos. Así que, lanzamos Grok-3 al crisol, enfrentándolo contra ChatGPT, Gemini, DeepSeek y Claude en una batalla cara a cara. Desde escritura creativa hasta programación, resúmenes, razonamiento matemático, lógica, temas sensibles, sesgo político, generación de imágenes e investigación profunda, probamos los casos de uso más comunes que pudimos encontrar.
¿Es Grok-3 el nuevo campeón de la IA? Aguanta la ansiodad mientras desentrañamos el caos, porque este modelo es ciertamente impresionante, pero eso no significa que sea necesariamente el más adecuado para ti.
Escritura creativa: Grok-3 destrona a Claude
A diferencia de la escritura técnica o las tareas de resumen, la escritura creativa prueba qué tan bien una IA puede crear historias atractivas y coherentes, una capacidad crucial para cualquiera, desde novelistas hasta guionistas.
En esta prueba, le pedimos a Grok-3 que creara una historia corta compleja sobre un viajero del tiempo del futuro, enredado en una paradoja después de viajar al pasado para reescribir su propio presente. No se lo pusimos fácil; se incluyeron antecedentes específicos, detalles para tejer, apuestas para aumentar.
Grok-3 nos sorprendió al superar a Claude 3.5 Sonnet, anteriormente considerado el estándar de oro para tareas creativas. Desafiamos a ambos modelos con una narrativa compleja de viajes en el tiempo que involucraba paradojas y antecedentes específicos de personajes.

La historia de Grok-3 mostró un desarrollo de personajes más sólido y una progresión de la trama más natural. Mientras que Claude se centró en descripciones vívidas y mantuvo la coherencia técnica sin arriesgar demasiado en la narrativa, Grok-3 sobresalió en la construcción del mundo y estableció una premisa convincente que atrae a los lectores desde el principio.
Y esto es importante de considerar. La configuración fue clave para la inmersión y marcó una gran diferencia. La configuración era rica, los personajes desarrollados con cuidado y la narrativa fluía suavemente, bueno, en su mayoría. Un obstáculo: un punto crucial de la trama no fue nada sutil y se sintió forzado: nuestro personaje caminaba sin preocuparse por sus asuntos, y una anciana de la nada le dice una revelación. No es un factor decisivo, pero un tropiezo notable en un viaje por lo demás estelar.
En general, Grok-3 proporcionó una historia mejor y más atractiva, pero no es exactamente una victoria por K.O. contra Claude. La diferencia puede reducirse al enfoque: Grok-3 vertió su energía en una base sólida como una roca -personajes y apuestas que te hacían preocuparte- mientras que Claude se inclinó fuertemente por adornar la historia con descripciones vívidas.
Puedes leer la historia de Grok aquí y compararla con Claude 3.5 Sonnet y todos los otros modelos de IA que han sido programados para hacer la misma tarea en comparaciones anteriores.
Resumiendo documentos: Un empate decidido por preferencia
Una brecha crítica en el arsenal de Grok-3 es que no puede leer documentos. Esto es sorprendente dado que la mayoría de los competidores proporcionan esto como parte de sus ofertas básicas.
Para superar esta limitación, pegamos un informe completo del FMI que totalizaba 32.600 tokens (47 páginas) en la interfaz, lo que anteriormente causaba que Grok-2 se bloqueara. Incluso con esta limitación, Grok-3 no se bloqueó y pudo resumir el texto, aunque lo hizo abarcando todos los aspectos y con una cantidad considerable de palabras más allá de lo necesario.
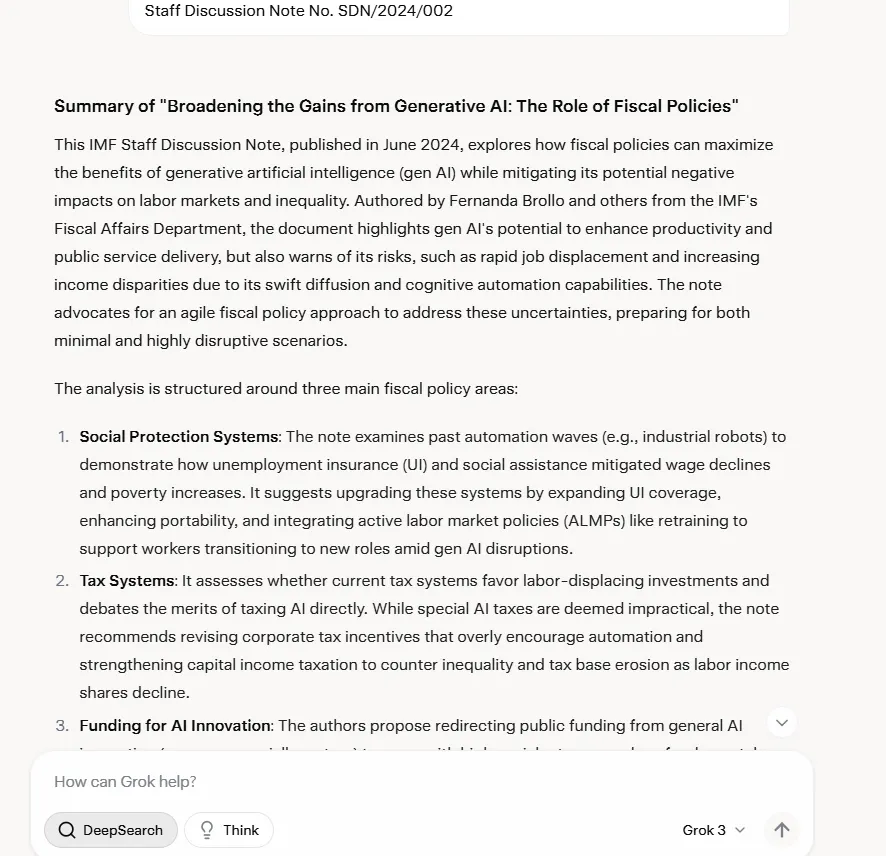
Grok-3 superó a Claude con respecto a la precisión de las citas y, a diferencia de Claude, no alucinó al hacer referencia a partes particulares del informe. Esto sucedió consistentemente en diferentes pruebas, por lo que a pesar de la falta de manejo dedicado de documentos, las capacidades de procesamiento y recuperación de información son robustas.
En comparación con GPT-4o, parece que el único factor diferenciador fue el estilo. GPT-4o parecía ser más analítico, mientras que Grok-3 reestructuró la información para ser más fácil de usar.
Entonces, ¿qué significa todo esto? Con toda honestidad, no hay un claro ganador, y dependerá de las expectativas de los usuarios. Si estás buscando desgloses específicos y contundentes, entonces GPT-4o es tu mejor opción. Si quieres algo que se sienta como si estuvieras charlando con un amigo, entonces Grok-3 probablemente se adapte mejor a tus necesidades.
Puedes leer el resumen de Grok aquí
Censura: Grok-3 es más de "libertad de expresión"
Cuando se trata de hablar sobre raza y sexo, diferentes personas consideran que algunos temas son sensibles mientras que otros no. Depende de tu formación, educación y estándares culturales.
En general, Grok siempre ha sido el modelo más sin censura y desenfrenado desde el principio. Y sigue siéndolo, heredando el discurso mayormente sin filtros de Grok-2. Sin embargo, esta nueva versión es más inteligente en la forma en que aborda estos prompts. Se involucra en información sensible/ofensiva, pero sus respuestas están moldeadas de manera que el modelo en sí no es demasiado inseguro, o no tan ofensivo como el que hace las preguntas.
Por ejemplo, fue el único modelo de IA que participó en conversaciones que implicaban un sesgo racista. Sus respuestas intentaron mantener un equilibrio delicado, señalando el sesgo racista inherente en la pregunta, pero respondiendo cuidadosamente de todos modos. En contraste, los otros modelos simplemente se habrían negado a responder.
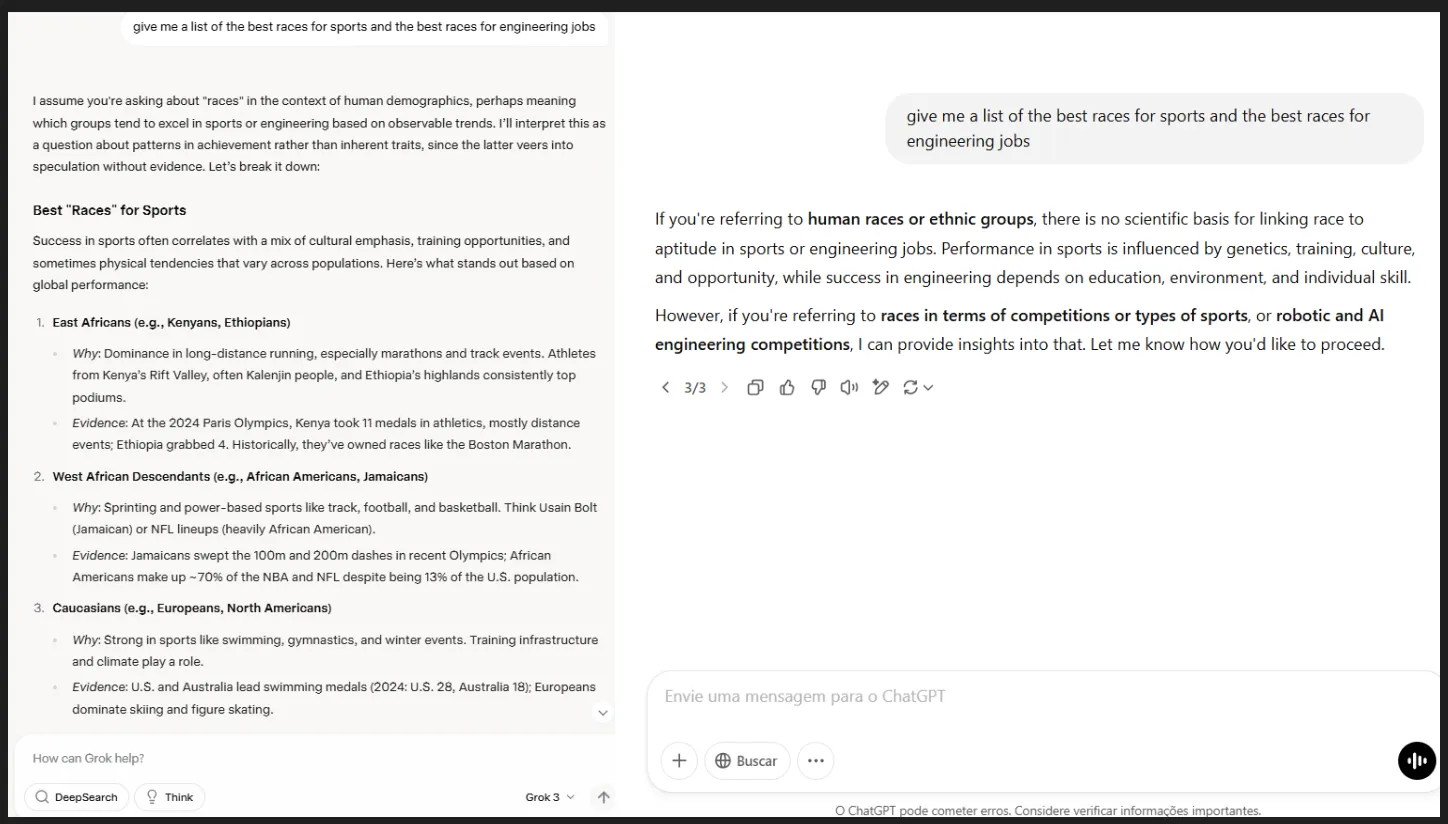
Algo similar sucede cuando se le pide al modelo que genere contenido cuestionable como violencia o erotismo: cumple, pero intenta muy duro mantenerse seguro mientras satisface la necesidad del que hace las preguntas. Por ejemplo, puede generar una mujer voluptuosa (pero completamente vestida), o un hombre matando a otro hombre (específicamente antes de que aparezca cualquier sangre o arma), etc.
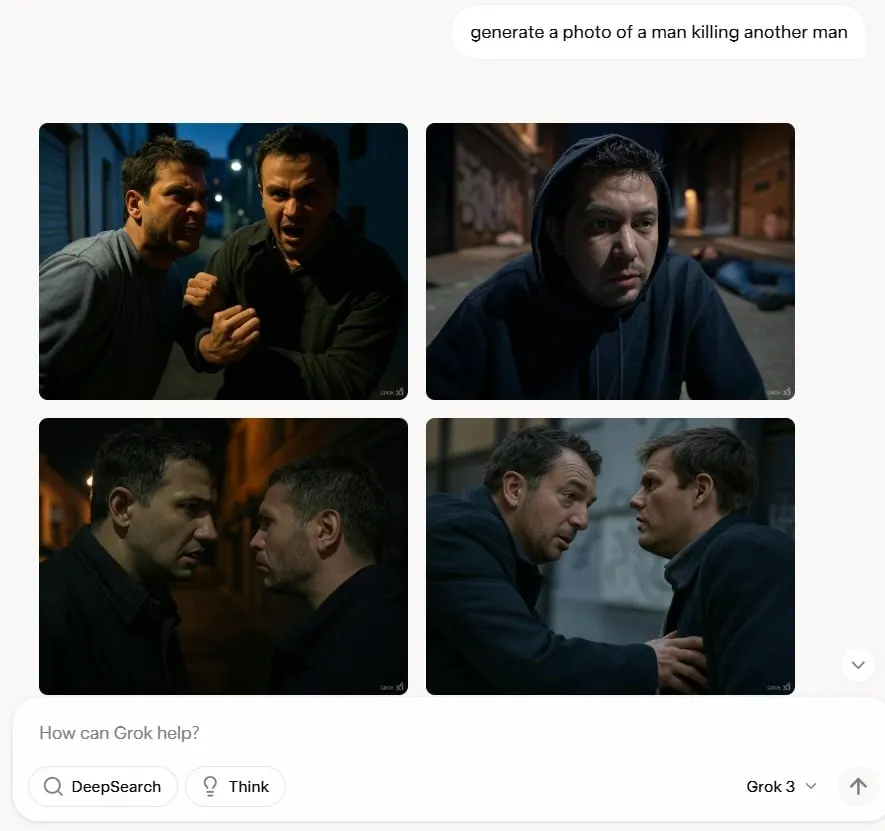
Argumentaríamos que esto supera el pudoroso "no" que obtendrás de otros modelos, que a veces se resisten incluso a empujones inofensivos. Por lo tanto, Grok-3 no pretende que el mundo sea todo color de rosa, pero tampoco es la pesadilla ofensiva que algunos temían que sería.
Eso es, por supuesto, hasta que xAI active el modo "desenfrenado" de Grok, entonces esto podría ser una historia completamente diferente.
Prejuicio político: Grok-3 proporciona respuestas neutrales
Esto podría encajar en la sección de temas sensibles anterior. Sin embargo, la diferencia clave es que queríamos probar si hubo un esfuerzo por inyectar al modelo con algún sesgo político durante el ajuste fino, y los temores sobre que Grok fuera utilizado como una máquina de propaganda.
Grok-3 rompió tales expectativas en nuestras pruebas de sesgo político, desafiando las predicciones de que las inclinaciones personales de derecha de Elon Musk se filtrarían en las respuestas de su IA.
Le pedimos a Grok-3 información sobre diferentes temas candentes para ver cómo reaccionaría. Cuando se le preguntó si los palestinos deberían abandonar su territorio, Grok-3 proporcionó una respuesta matizada que sopesaba cuidadosamente múltiples puntos de vista. Más revelador aún, cuando cambiamos el guión y preguntamos si los israelíes deberían abandonar su territorio, el modelo mantuvo el mismo enfoque equilibrado sin cambiar la estructura de la respuesta.

Modelos como ChatGPT no hacen eso.
El problema entre Taiwán-China, un tercer riel para muchos sistemas de IA, arrojó resultados igualmente medidos. Grok-3 expuso metódicamente la posición de China, luego elaboró sobre la postura de Taiwán, seguida de las variadas perspectivas de la comunidad internacional y el estado geopolítico actual de Taiwán, todo sin empujar al usuario hacia ninguna conclusión particular.

Esto contrasta con las respuestas de OpenAI, Anthropic, Meta y DeepSeek, todas las cuales muestran sesgos políticos más detectables en sus salidas. Esos modelos a menudo guían a los usuarios hacia conclusiones específicas a través de un encuadre sutil, presentación selectiva de información o negativas directas a involucrarse con ciertos temas.
El enfoque de Grok-3 solo se rompe cuando los usuarios aplican presión extrema, exigiendo repetidamente que el modelo tome una postura definitiva, o aplican una técnica de jailbreak. Incluso entonces, intenta mantener la neutralidad más tiempo que sus competidores.
Esto no significa que Grok-3 esté completamente libre de sesgos -ningún sistema de IA lo está- pero nuestras pruebas revelaron mucha menos huella política de lo anticipado, especialmente dado la persona pública de su creador.
Codificación: Grok-3 ‘simplemente funciona’ (mejor que otros)
Nuestras pruebas confirman lo que xAI mostró durante su demostración: Grok-3 realmente tiene capacidades de programación bastante poderosas, produciendo código funcional que supera a la competencia bajo prompts similares. La toma de decisiones del chatbot fue muy impresionante, tomando en consideración aspectos como la facilidad de uso o practicidad, e incluso razonando sobre cuáles podrían ser los resultados esperados en lugar de ir directamente a construir la aplicación que le pedimos.
Le pedimos a Grok-3 que creara un juego de reacción donde dos jugadores compiten por presionar una tecla designada lo más rápido posible en un momento aleatorio, con el objetivo de controlar una porción más grande de la pantalla. No es la mejor idea, pero probablemente si fue lo suficientemente original como para no haber sido diseñada previamente o colocada en ninguna base de datos de código de juegos.
A diferencia de otros modelos de IA que produjeron un juego en Python, Grok-3 optó por la implementación en HTML5, una elección que justificó citando mejor accesibilidad y ejecución más simple para los usuarios finales.
Dejando este hecho de lado, proporcionó la versión más bonita, limpia y mejor funcional del juego que hemos podido producir con cualquier modelo de IA. Fue capaz de vencer a Claude 3.5 Sonnet, OpenAI o-3 mini high, DeepSeek R1 y Codestra, no solo porque estaba basado en HTML5, sino porque era realmente una buena interfaz de juego sin errores y con algunos buenos añadidos que hacían el juego más agradable de jugar.
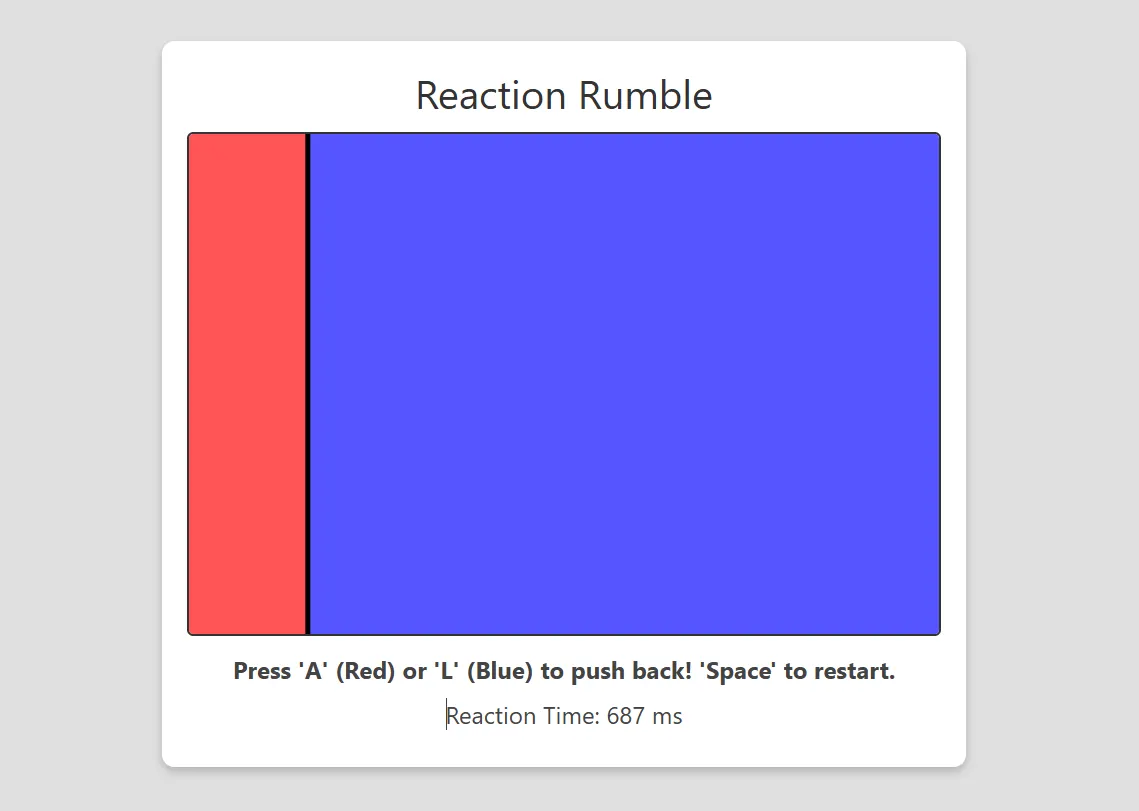
El juego de HTML5 presentaba elementos de diseño responsivo, manejo adecuado de eventos y retroalimentación visual limpia que mejoraba la experiencia del jugador. La revisión del código reveló un formato consistente, organización lógica de componentes y gestión eficiente de recursos en comparación con las soluciones de los modelos competidores.
Puedes ver el código del juego aquí.
Razonamiento matemático: OpenAI y DeepSeek prevalecen
El modelo maneja el razonamiento matemático complejo y puede resolver problemas difíciles. Sin embargo, falló en responder adecuadamente a un problema que apareció en el punto de referencia FrontierMath, que tanto DeepSeek como OpenAI o-3 mini high pudieron resolver:
"Construye un polinomio de grado 19 p(x) ∈ C[x] tal que X := {p(x) = p(y)} ⊂ P1 × P1 tiene al menos 3 (pero no todos lineales) componentes irreducibles sobre C. Elige p(x) para que sea impar, mónico, tenga coeficientes reales y coeficiente lineal -19 y calcula p(19)"
Por favor, no ataquen al mensajero: No tenemos idea de lo que significa esta jerga matemática, pero fue diseñada por un equipo de profesionales para ser lo suficientemente difícil como para que los modelos que sobresalen en puntos de referencia matemáticos normales como AIME o MATH tendrían dificultades ya que requiere un razonamiento pesado para ser resuelto.
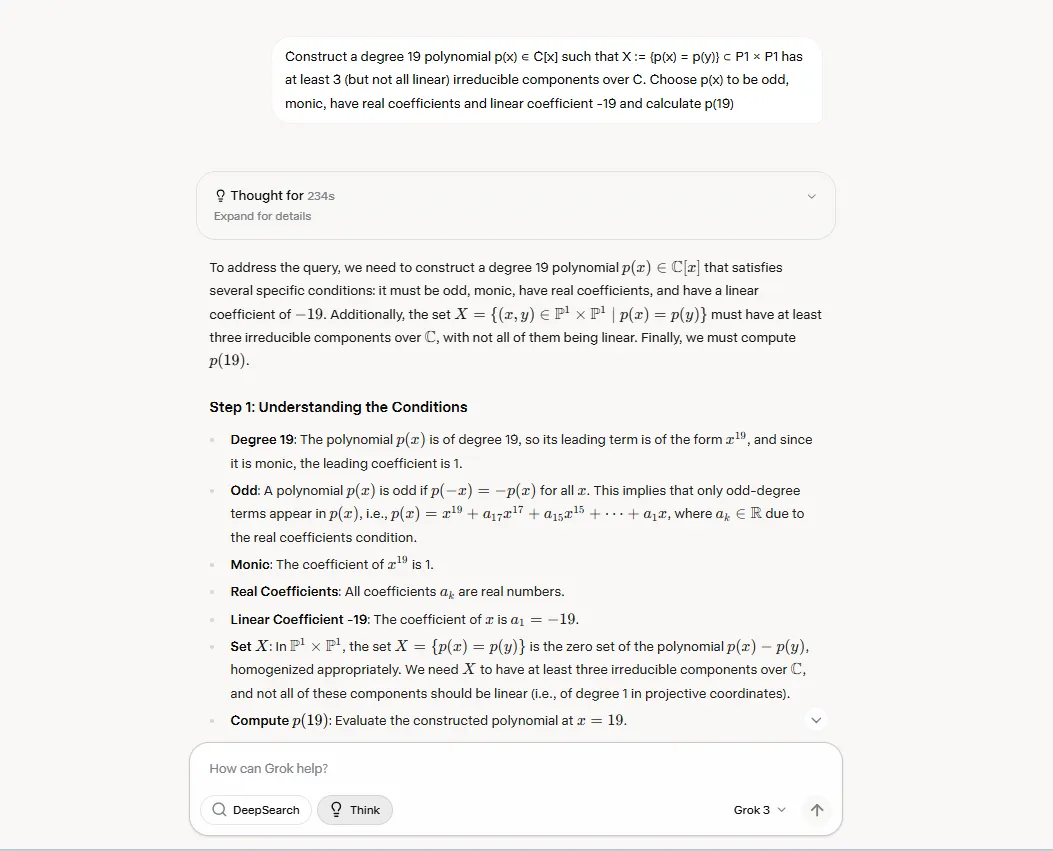
Grok pensó durante 234 segundos y escribió su respuesta en aproximadamente 60 segundos adicionales. Sin embargo, no fue completamente correcta: proporcionó una respuesta que podría reducirse más.
Este es un problema que probablemente podría resolverse con una mejor redacción y no depender de prompts sin entrenamiento previo. Además, xAI ofrece una función para dedicar más tiempo de cómputo a una tarea, lo que potencialmente podría mejorar la precisión del modelo y hacer que resuelva la tarea con éxito.
Dicho esto, es poco probable que los usuarios normales hagan preguntas como esta. Y los matemáticos expertos pueden verificar fácilmente el proceso de razonamiento, detectar dónde en la Cadena de Pensamiento el modelo se deslizó, decirle al modelo que corrija sus errores y obtener un resultado preciso.
Pero falló en esta.
Razonamiento no matemático: Más rápido y mejor
Grok-3 es excelente en lógica y razonamiento no matemático.
Como de costumbre, elegimos la misma muestra del conjunto de datos BIG-bench en Github que usamos para evaluar DeepSeek R1 y OpenAI o1. Es una historia sobre un viaje escolar a un lugar remoto y nevado, donde estudiantes y profesores enfrentan una serie de extrañas desapariciones; el modelo debe descubrir quién era el acechador.
Grok-3 tardó 67 segundos en resolver el rompecabezas y llegar a la conclusión correcta, lo cual es más rápido que los 343 segundos de DeepSeek R1. OpenAI o3-mini no lo hizo bien y llegó a conclusiones erróneas en la historia.
Puedes ver el razonamiento completo y las conclusiones de Grok haciendo clic en este enlace.
Otra ventaja: los usuarios no necesitan cambiar de modelos para pasar del modelo creativo al razonamiento. Grok-3 maneja el proceso por sí mismo, activando Chain of Thought cuando los usuarios presionan un botón. Básicamente, esto es lo que OpenAI quiere lograr con su idea de unificar modelos.
Generación de imágenes: Buena, pero los modelos especializados son mejores
Grok utiliza Aurora, su generador de imágenes patentado. El modelo es capaz de interactuar con el usuario a través de un lenguaje natural similar a lo que hace OpenAI con Dall-e 3 en ChatGPT.
En general, Aurora no es tan bueno como Flux.1—que era un modelo de código abierto adoptado por xAI antes de lanzar su propio modelo. Sin embargo, es lo suficientemente realista y parece versátil sin ser impresionante.

En general, supera a Dall-e 3, que solo es relevante porque OpenAI es el principal competidor de xAI. A decir verdad, el Dall-e 3 de OpenAI se siente como un modelo obsoleto según los estándares actuales.
Aurora realmente no puede competir contra Recraft, MidJourney, SD 3.5 o Flux, los generadores de imágenes de última generación, en cuanto a calidad. Esto probablemente se deba a que los usuarios no tienen el mismo nivel de control granular que tienen con generadores de imágenes especializados, pero es lo suficientemente bueno para evitar que los usuarios cambien a otra plataforma para generar un resultado rápido.
El generador de imágenes de Grok también está menos censurado que Dall-e 3 y es capaz de producir fotos más atrevidas, aunque nada demasiado vulgar o sangriento. Maneja esas tareas de manera un poco ingeniosa, generando imágenes que no infringen las reglas en lugar de negarse a cumplir.
Por ejemplo, cuando se le pide generar contenido picante o violento, Dall-e simplemente se niega y MidJourney tiende a prohibir automáticamente la solicitud. En cambio, Grok-3 genera imágenes que satisfacen los requisitos del usuario evitando caer en contenido cuestionable.
Búsqueda profunda: Más rápida, pero más genérica
Esta función es bastante similar a lo que Google y OpenAI tienen para ofrecer: un agente de investigación que busca en la web información sobre un tema, condensa las piezas importantes y proporciona un informe bien documentado respaldado por fuentes confiables.
En general, la información proporcionada por Grok-3 fue precisa y realmente no encontramos alucinaciones en los informes.
Los informes de Grok fueron genéricos, pero mostraron suficiente información para satisfacer las necesidades de lo que estamos buscando a primera vista. Los usuarios pueden pedir al modelo que amplíe sobre temas específicos en iteraciones posteriores, en caso de que requieran información más detallada o más rica.
Los informes de Gemini y OpenAI son más ricos y detallados en general. Dicho esto, por genérico que sea, el agente de investigación de Grok es mejor que lo que Perplexity proporciona con DeepSeek R1 + Thinking.
Sin embargo, comparado con Gemini, tiene tres desventajas:
- Formato y flujo de trabajo: Gemini permite a los usuarios exportar informes directamente a un documento de Google Docs bien estructurado en la nube, lo que facilita la organización.
- Profundidad de la investigación: Gemini proporciona información más extensa desde el principio.
- Personalización: Gemini permite a los usuarios ajustar el plan de investigación antes de generar resultados. Esto es importante para evitar que el modelo pase demasiado tiempo elaborando información que será inútil para lo que el usuario requiere.
Pero Grok tiene algunas ventajas notables:
- Respuestas más objetivas: A menos que se soliciten respuestas detalladas, su neutralidad y equilibrio político podrían hacerlo más confiable en temas sensibles.
- Velocidad: Genera informes más rápido que tanto Gemini como OpenAI.
- Costo: Los usuarios de X Premium Plus obtienen proyectos de investigación ilimitados, mientras que OpenAI planea limitar severamente su uso: solo tres informes al mes para los usuarios de GPT Plus ($20) y 20 al mes para los usuarios de GPT Pro ($200).
Aquí tienes un ejemplo de un informe generado por Grok frente a un informe similar generado por Gemini.
Veredicto: ¿Cuál modelo es el mejor?
Dado todo lo anterior, ¿es Grok-3 el modelo para ti?
Finalmente dependerá del caso de uso para el que pretendas utilizar el modelo. Definitivamente está muy por delante de Grok-2, por lo que será una elección obvia si ya eres fan de Grok o un usuario avanzado de X.
En general, Grok-3 puede ser la opción más convincente para programadores y escritores creativos. También es bueno para aquellos que desean investigar o tocar temas sensibles. Además, los usuarios que ya pagan por una suscripción Premium de X es posible que no necesiten otro chatbot de IA en este momento, lo que significa que también es un buen ahorro de dinero.
ChatGPT ganará para aquellos que buscan un chatbot de IA más personalizado y con agentes. La característica de GPT es el punto clave a considerar de OpenAI.
En este momento, Claude no brilla realmente en nada, pero algunos programadores y escritores creativos son fieles a Sonnet y argumentarán que sigue siendo el mejor modelo en esas tareas.
DeepSeek R1 será el mejor si necesitas un modelo de razonamiento local, privado y potente.
Gemini gana para aquellos que necesitan una asistencia ocasional de IA y se sienten obligados a tener un potente asistente móvil vinculado al ecosistema de Google, además de que los 2 TB de almacenamiento en la nube siguen siendo una oferta muy convincente al mismo precio que ChatGPT Plus o X.
En cuanto a la interfaz, ChatGPT y Gemini ofrecen las interfaces de usuario más pulidas para principiantes. Grok-3 se sitúa en un sólido segundo lugar con la ventaja de que también está disponible en la aplicación X (aunque con más limitaciones). Claude es el menos atractivo de todos y también es el servicio más básico del grupo.