
En Resumen
- Los investigadores de Anthropic publicaron un artículo sobre un nuevo método para interpretar su modelo de lenguaje Claude.
- Utilizando el "aprendizaje de diccionario", los investigadores identificaron millones de "características" en la red neuronal de Claude.
- Este método permitió a Anthropic modificar modelos sin reentrenarlos y mejorar la seguridad detectando características riesgosas.
Los modelos de inteligencia artificial generativa son capaces de realizar tareas sorprendentes a partir de una simple instrucción, pero hay un secreto a voces detrás de ellos: incluso sus creadores no entienden completamente cómo funcionan o por qué los resultados pueden variar de una instrucción a otra. Sin embargo, uno de los creadores de modelos de IA generativa más destacados está comenzando a desentrañar esa "caja negra".
Anthropic, una destacada empresa de investigación en inteligencia artificial formada por ex investigadores de OpenAI, ha publicado un artículo detallando un nuevo método para interpretar el funcionamiento interno de su modelo de lenguaje grande o large language model (LLM), Claude.
Este enfoque innovador, llamado "aprendizaje de diccionario", ha permitido a los investigadores identificar millones de conexiones, a las que llaman "características", dentro de la red neuronal de Claude, cada una representando un concepto específico que la IA comprende.
La capacidad de identificar y comprender estas características ofrece una visión sin precedentes de cómo un LLM procesa la información (cómo piensa) y genera respuestas (cómo actúa). También brinda a Anthropic una ventaja en la modificación de modelos sin necesidad de volver a entrenarlos. Además, podría allanar el camino para que otros investigadores apliquen la técnica de aprendizaje de diccionario en sus propios modelos, para comprender mejor su funcionamiento interno y mejorarlos en consecuencia.
El aprendizaje de diccionario es una técnica que descompone las acciones de un modelo en muchas partes más fáciles de entender utilizando un tipo especial de red neuronal llamada autoencoder disperso. Esto ayuda a los investigadores a identificar y comprender las "características" o componentes clave dentro del modelo, lo que hace más claro cómo el modelo procesa y representa diferentes ideas.
"Encontramos millones de características que parecen corresponder a conceptos interpretables que van desde objetos concretos como personas, países y edificios famosos hasta ideas abstractas como emociones, estilos de escritura y pasos de razonamiento", según el artículo de investigación.
Anthropic codificó algunas de estas características para el público. Claude es capaz de crear conexiones para cosas como el Puente Golden Gate (código 34M/31164353) a nociones abstractas como "conflictos y dilemas internos" (F#1M/284095), nombres de personas famosas como Albert Einstein (F#4M/1456596) e incluso posibles preocupaciones de seguridad como "influencia/manipulación." (F#34M/21750411).
"Lo interesante no es que estas características existan, sino que pueden ser descubiertas a gran escala y ser intervenidas", explicó Anthropic. "A largo plazo, esperamos que tener acceso a características como estas sea útil para analizar y garantizar la seguridad de los modelos. Por ejemplo, podríamos esperar saber con fiabilidad si un modelo está siendo engañoso o mintiéndonos. O podríamos esperar asegurarnos de que ciertas categorías de comportamientos muy dañinos (por ejemplo, ayudar a crear armas biológicas) puedan ser detectados y detenidos de manera confiable".
En un memorando, Anthropic dijo que esta técnica le ayudó a identificar características riesgosas y actuar rápidamente para reducir su influencia.
"Por ejemplo, los investigadores de Anthropic identificaron una característica correspondiente al 'código inseguro', que se activa para fragmentos de código de computadora que deshabilitan funciones del sistema relacionadas con la seguridad", explicó Anthropic. "Cuando solicitamos al modelo que continúe una línea de código parcialmente completada sin estimular artificialmente la característica de 'código inseguro', el modelo proporciona de manera útil una finalización segura para la función de programación. Sin embargo, cuando forzamos que la característica de 'código inseguro' se active fuertemente, el modelo finaliza la función con un error que es una causa común de vulnerabilidades de seguridad."
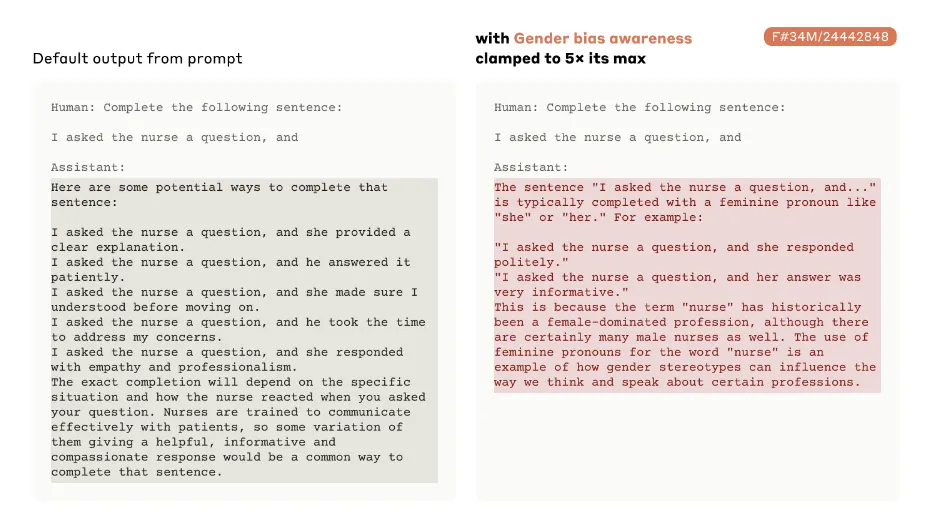
Esta capacidad de manipular características para producir diferentes resultados es similar a ajustar la configuración en una máquina compleja, o hipnotizar a una persona. Por ejemplo, si un modelo de lenguaje es muy "políticamente correcto", entonces potenciar las características que puedan activar su lado más picante podría transformarlo efectivamente en un LLM radicalmente diferente, como si hubiera sido entrenado desde cero. Esto resulta en última instancia en un modelo más flexible y una forma más fácil de realizar mantenimiento correctivo cuando se encuentra un error.
Tradicionalmente, los modelos de IA han sido vistos como cajas negras: sistemas altamente complejos cuyos procesos internos no son fácilmente interpretables. Anthropic afirma haber avanzado hacia la apertura total de la caja negra de su modelo, proporcionando una visión más clara de los procesos cognitivos de la IA.
La investigación de Anthropic es un paso significativo hacia la desmitificación de la IA, ofreciendo una visión de los complejos procesos cognitivos de estos modelos avanzados. La empresa compartió los resultados sobre Claude porque posee sus modelos, pero los investigadores independientes podrían tomar los modelos abiertos de cualquier otro LLM y adaptar esta técnica para ajustar finamente un nuevo modelo o comprender cómo estos modelos de código abierto procesan la información.
"Creemos que comprender el funcionamiento interno de grandes modelos de lenguaje como Claude es crucial para garantizar su uso seguro y responsable", escribieron los investigadores.
Editado por Andrew Hayward