

En Resumen
- La startup parisina Mistral AI lanzó Mixtral, un modelo de lenguaje grande (LLM) abierto que afirma superar a GPT 3.5 de OpenAI en varios puntos.
- Mixtral utiliza la técnica de mezcla dispersa de expertos (MoE), que hace que el modelo sea más potente y eficiente que su predecesor, Mistral 7b, y competir con modelos más grandes utilizando un tamaño 10 veces más pequeño.
- Mistral AI recibió una importante inversión de la Serie A de Andreessen Horowitz y otros gigantes tecnológicos.
La startup con sede en París, Mistral AI, que recientemente afirmó tener una valoración de $2.000 millones, ha lanzado Mixtral, un modelo de lenguaje grande (LLM) abierto que, según afirma, supera a GPT 3.5 de OpenAI en varios puntos de referencia y es mucho más eficiente.
Mistral recibió una importante inversión de la Serie A de Andreessen Horowitz (a16z), una firma de capital de riesgo reconocida por sus inversiones estratégicas en sectores tecnológicos transformadores, especialmente en IA. Otros gigantes tecnológicos como Nvidia y Salesforce también participaron en la ronda de financiación.
"Mistral está en el centro de una pequeña, pero apasionada comunidad de desarrolladores que se está formando en torno a la IA de código abierto", dijo Andreessen Horowitz en su anuncio de financiamiento. "Los modelos ajustados por la comunidad ahora dominan rutinariamente las clasificaciones de código abierto (e incluso superan a los modelos de código cerrado en algunas tareas)".
Mixtral utiliza una técnica llamada mezcla dispersa de expertos (MoE), que según la compañía hace que el modelo sea más potente y eficiente que su predecesor, Mistral 7b—e incluso sus competidores más poderosos.
Una mezcla de expertos (MoE) es una técnica de aprendizaje automático en la que los desarrolladores entrenan o configuran múltiples modelos virtuales de expertos para resolver problemas complejos. Cada modelo experto se entrena en un tema o campo específico. Cuando se le presenta un problema, el modelo selecciona un grupo de expertos de un conjunto de agentes, y esos expertos utilizan su entrenamiento para decidir qué salida se adapta mejor a su experiencia.
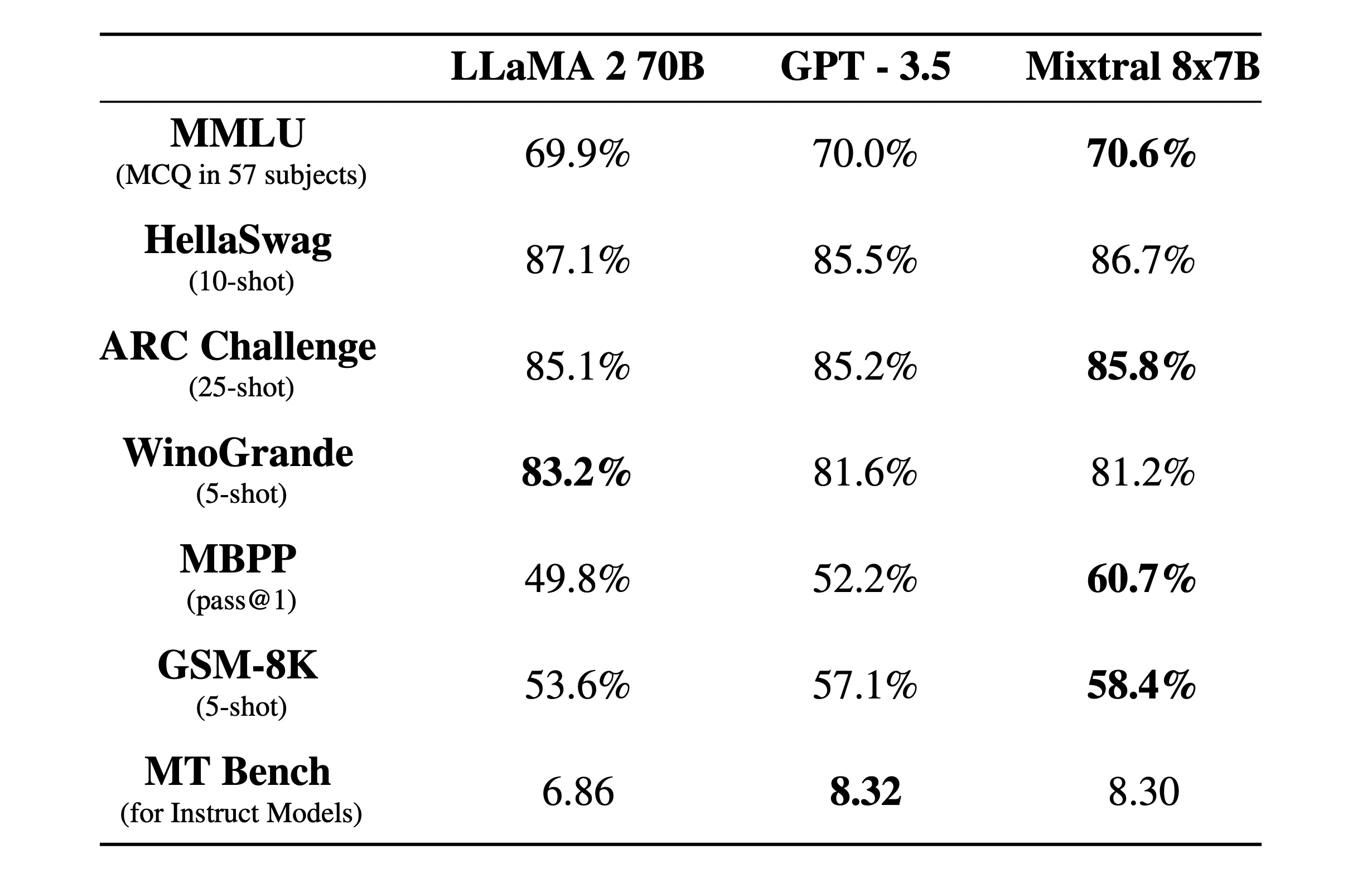
MoE puede mejorar la capacidad, eficiencia y precisión del modelo para modelos de aprendizaje profundo, el ingrediente secreto que distingue a Mixtral del resto, es que es capaz de competir contra un modelo entrenado en 70 mil millones de parámetros utilizando un modelo 10 veces más pequeño.
"Mixtral tiene un total de 46.7B de parámetros, pero solo utiliza 12.9B de parámetros por token", dijo Mistral AI. "Por lo tanto, procesa la entrada y genera la salida a la misma velocidad y al mismo costo que un modelo de 12.9B".
"Mistral supera a Llama 2 70B en la mayoría de las pruebas con una inferencia 6 veces más rápida y coincide o supera a GPT 3.5 en la mayoría de las pruebas estándar", dijo Mistral AI en una publicación oficial de blog.
Mixtral también está licenciado bajo la licencia permisiva Apache 2.0. Esto permite a los desarrolladores inspeccionar, ejecutar, modificar e incluso crear soluciones personalizadas sobre el modelo.
Sin embargo, hay un debate, sobre si Mixtral es 100% de código abierto o no, ya que Mistral dice que solo lanzó "pesos abiertos" y la licencia del modelo central impide su uso para competir contra Mistral AI. La startup tampoco ha proporcionado el conjunto de datos de entrenamiento y el código utilizado para crear el modelo, lo cual sería el caso en un proyecto de código abierto.
La compañía dice que Mixtral ha sido ajustado para funcionar excepcionalmente bien en idiomas extranjeros, además del inglés. "Mixtral 8x7B domina el francés, alemán, español, italiano e inglés", obteniendo altas puntuaciones en pruebas multilingües estandarizadas, informó Mistral AI.
También se lanzó una versión instruida llamada Mixtral 8x7B Instruct para una instrucción cuidadosa, logrando una puntuación máxima de 8.3 en el benchmark MT-Bench. Esto lo convierte en el mejor modelo de código abierto actual en el benchmark.
El nuevo modelo de Mistral promete una revolucionaria arquitectura de mezcla de expertos dispersos, buenas capacidades multilingües y acceso abierto completo. Y considerando que esto sucedió solo meses después de su creación, la comunidad de código abierto está viviendo una era emocionante e interesante.
Mixtral está disponible para ser descargado a través de Hugging Face, pero los usuarios también pueden utilizar la versión instructiva en línea.
Editado por Ryan Ozawa.