

En Resumen
- OpenAI lanza el rastreador web GPTBot, recopilando datos para entrenar GPT-5, su próxima generación de sistemas IA.
- El sistema recopila información pública, excluyendo contenido pago y sensible, pero plantea problemas éticos de consentimiento.
- La compañía registra la marca "GPT-5", indicando un próximo lanzamiento, mientras compite en el espacio de IA con gigantes tecnológicos como Meta.
OpenAI ha lanzado un nuevo bot de rastreo web, GPTBot, para ampliar su conjunto de datos con la finalidad de entrenar su próxima generación de sistemas de IA, y al parecer la próxima iteración ya tiene un nombre oficial. La compañía ha registrado la marca "GPT-5", insinuando un próximo lanzamiento, al tiempo que advierte a los editores web cómo mantener su contenido fuera de su enorme alcance.
Según OpenAI, el rastreador web recopilará datos de acceso público de sitios web, evitando contenido pago, sensible y prohibido. Sin embargo, al igual que otros motores de búsqueda como Google, Bing y Yandex, el sistema es de exclusión voluntaria: por defecto, GPTBot asumirá que la información accesible es válida. Para evitar que el rastreador web de OpenAI analice un sitio web, el propietario debe agregar una regla de "no permitir" a un archivo estándar en el servidor.
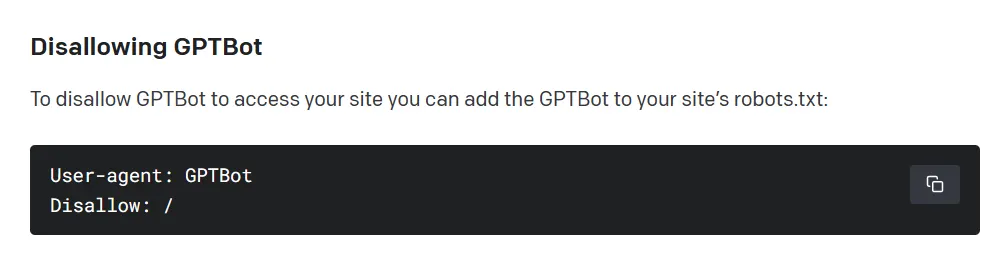
OpenAI también dice que GPTBot escaneará de manera preventiva los datos recopilados para eliminar información de identificación personal (PII) y texto que viole sus políticas.
Sin embargo, según algunos éticos de la tecnología, el enfoque de exclusión voluntaria aún plantea problemas de consentimiento.
En Hacker News, algunos usuarios justificaron la decisión de OpenAI diciendo que debe recopilar todo lo que pueda si las personas quieren tener una herramienta de IA generativa capaz en el futuro. "Todavía necesitan datos actuales o sus modelos GPT quedarán atrapados en septiembre de 2021 para siempre", dijo un usuario. Otro usuario más consciente de la privacidad argumentó que "OpenAI ni siquiera está citando en la moderación. Está creando una obra derivada sin citar, por lo tanto, la está oscureciendo".
El lanzamiento de GPTBot sigue las críticas recientes a OpenAI por recopilar datos sin permiso para entrenar Modelos de Lenguaje Grandes o Large Language Models (LLMs) como ChatGPT. Para abordar estas preocupaciones, la compañía actualizó sus políticas de privacidad en abril.
Mientras tanto, una reciente solicitud de marca registrada para GPT-5 parece confirmar que OpenAI está entrenando su próximo modelo para un lanzamiento futuro. Es muy probable que el nuevo sistema involucre la extracción masiva de datos web para actualizar y expandir sus datos de entrenamiento.
Esto podría representar un cambio en el énfasis inicial de OpenAI en la transparencia y la seguridad de la IA, pero no es sorprendente considerando que ChatGPT es el LLM más utilizado en el mundo, a pesar de un mercado cada vez más saturado y potente. El producto estrella de OpenAI, al igual que cualquier LLM, solo es tan bueno como la calidad de los datos utilizados para entrenarlo.
OpenAI necesita recopilar nuevos y mejores datos. Y necesita muchos de ellos.
Por otro lado, hay un LLM de código abierto, creado por el gigante de las redes sociales, Meta. El gigante tecnológico ha ofrecido su modelo de forma gratuita, siempre y cuando no seas un competidor ni una empresa demasiado grande. Meta no ha revelado qué conjuntos de datos utilizó para entrenar su modelo y qué información ha recopilado. Sin embargo, este enfoque permite a los usuarios ajustar el modelo utilizando sus propios conjuntos de datos.
Mientras que OpenAI se basa en todos sus datos recopilados para entrenar sus modelos y construir un ecosistema rentable en torno a sus herramientas de IA, Meta está tratando de construir un negocio rentable en torno a sus datos. Por lo tanto, Meta no solo los utiliza para crear mejores modelos, sino que también los comparte con terceros para que los utilicen.
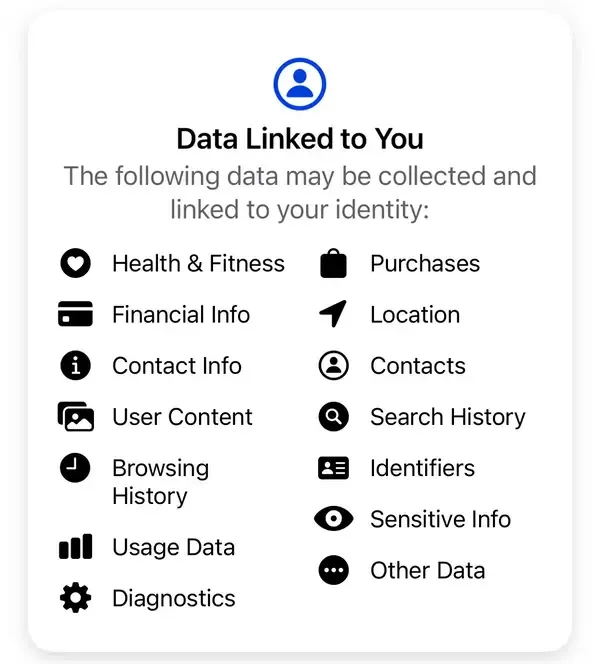
"No vendemos tu información. En cambio, según la información que tenemos, los anunciantes y otros socios nos pagan para mostrarte anuncios personalizados", explica Meta. Según las divulgaciones de privacidad estándar de Meta, algunos de los datos que la empresa recopila incluyen compras, historial de navegación, identificadores, información financiera, contactos y otra información sensible no revelada, entre otros.
ChatGPT ahora cuenta con más de 1,5 mil millones de usuarios activos mensuales. Y la inversión de $10 mil millones de Microsoft en OpenAI parece previsora, ya que la integración de ChatGPT ha mejorado las capacidades de Bing.
Por ahora, OpenAI lidera el candente espacio de la IA, con los gigantes tecnológicos corriendo para intentar alcanzarlo. El nuevo rastreador web de la compañía puede mejorar aún más las habilidades de sus modelos. Pero la expansión de la recopilación de datos de internet también plantea preguntas éticas sobre los derechos de autor y el consentimiento.
A medida que los sistemas de IA se vuelven más sofisticados, equilibrar la transparencia, la ética y las capacidades seguirá siendo un acto de equilibrio complejo.