

En Resumen
- DeepReinforce lanzó Ornith-1.0, familia de cuatro modelos open-source bajo licencia MIT para codificación agéntica.
- El modelo insignia de 397.000 millones de parámetros obtuvo 82,4 en SWE-bench, superando a Claude Opus 4.7.
- El modelo de 9.000 millones logró 69,4 en SWE-bench, compitiendo con rivales 3-4 veces más grandes.
DeepReinforce, un laboratorio de investigación en IA anteriormente conocido por CUDA-L1 y el ciclo de optimización de agentes de código IterX, lanzó Ornith-1.0 a finales de la semana pasada—una familia de modelos de código open-source disponibles en Hugging Face en cuatro tamaños basados en el número de parámetros: 9.000 millones, 31.000 millones, 35.000 millones en mixture of experts, y un modelo insignia de 397.000 millones en mixture-of-experts, todos bajo licencia MIT sin restricciones regionales.
Los parámetros son básicamente la cantidad de ajustes y configuraciones que un modelo puede manejar durante su entrenamiento. Cuantos más parámetros, más capaz es un modelo. Un modelo de 9.000 millones de parámetros se considera pequeño, suficiente para funcionar en un buen smartphone, pero no capaz de realizar tareas de razonamiento complejas de manera confiable. Un modelo de 397.000 millones es mucho más capaz, pero requiere una capacidad de cómputo considerable, del tipo que no está disponible en hardware de consumo.
El laboratorio lo describe como "una familia de modelos open-source con capacidad de auto-mejora, diseñada especialmente para tareas de codificación agéntica". Esa palabra—agéntica—tiene mucho peso.
Aloha! 🌺 Meet Ornith-1.0, a family of open-source LLMs specialized for agentic coding.
Ornith-1.0 spans the full parameter sizes including 9B Dense, 31B Dense, 35B MoE, and 397B MoE. It achieves state-of-the-art performance among open-source models of comparable size on… pic.twitter.com/7g1rmacLps
— Ornith (@ornith_) June 25, 2026
La mayoría de la IA con la que las personas interactúan es conversacional: escribes, responde, y el intercambio termina. La IA agéntica es diferente—recibe una tarea y ejecuta acciones para completarla sin que un humano guíe cada paso. En un contexto de programación, eso significa una IA que lee archivos, ejecuta pruebas, identifica qué falló, corrige el código y repite el ciclo hasta terminar.
La IA agéntica significa que nadie necesita estar frente al teclado durante la mayor parte del proceso. Ese es el punto central. Esta es también la dirección donde se está produciendo el progreso comercialmente más relevante en 2026—los modelos capaces de ejecutar flujos de trabajo de desarrollo de 20 pasos sin supervisión valen más que los que simplemente escriben una función limpia cuando se les solicita.
Sin embargo, la mayoría de los Large Language Models (LLMs) siguen diseñados con la retroalimentación humana en mente.
Cómo funciona el cerebro de Ornith
La mayoría de los agentes de código con IA se combinan con un armazón diseñado por humanos—un conjunto fijo de reglas sobre cómo el agente estructura su trabajo: cuándo llamar a una herramienta, cómo manejar un error, cómo descomponer un problema de múltiples pasos. Ornith, en cambio, "trata el armazón como un objeto aprendible que coevoluciona con la política".
En otras palabras: en lugar de heredar el manual de alguien más, desarrolla el suyo propio.
Durante el aprendizaje por refuerzo, cada paso de entrenamiento ocurre en dos etapas. El modelo primero lee la tarea y propone una estrategia refinada para abordarla. Luego utiliza esa estrategia para generar una solución.
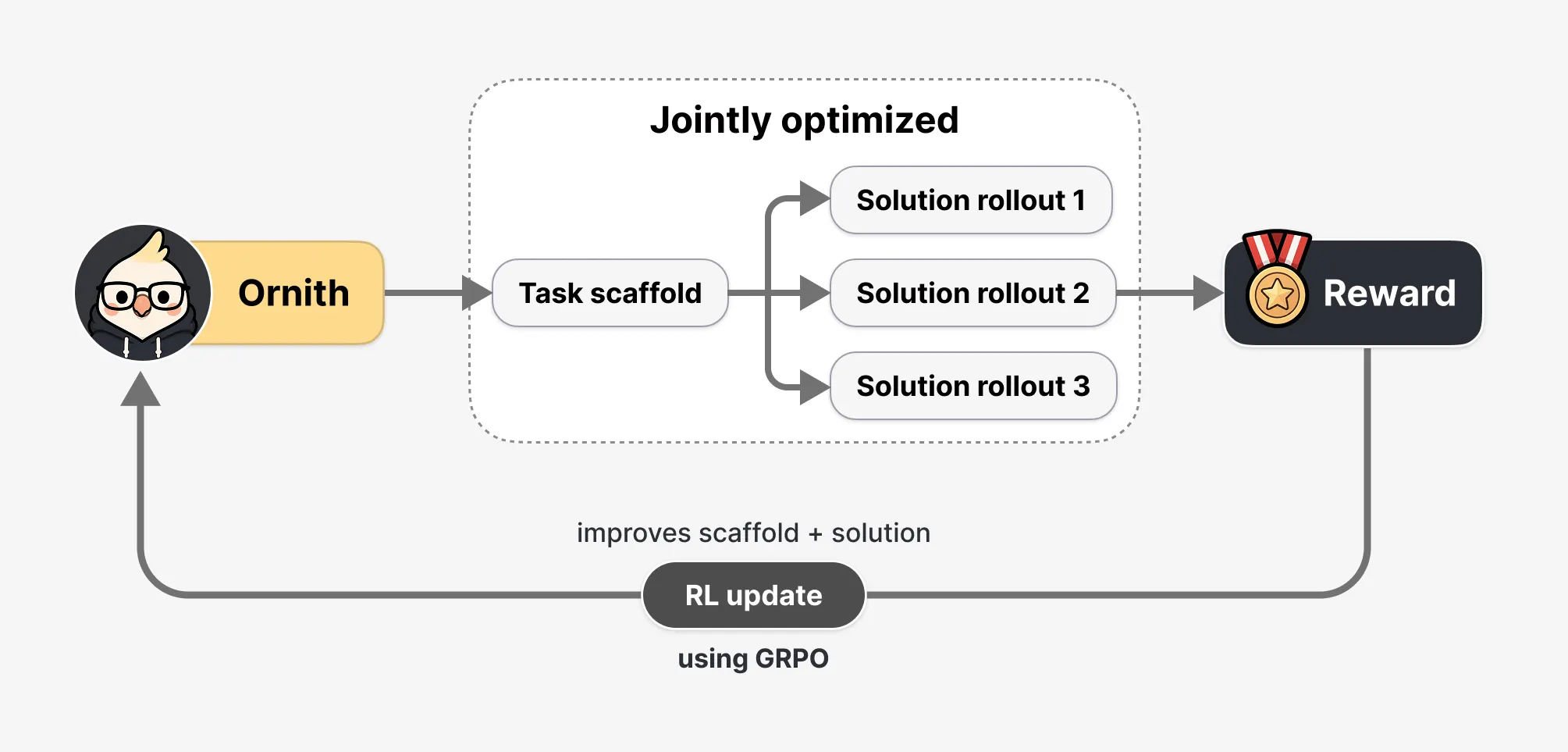
La recompensa del resultado fluye de regreso a ambas etapas—de modo que el modelo se optimiza para escribir mejores estrategias, no solo mejor código. Al repetir esto miles y millones de veces, surgen enfoques específicos para cada tarea sin que un humano los diseñe.
DeepReinforce también se toma en serio el reward hacking. Si el modelo puede escribir su propio armazón de entrenamiento, teóricamente podría escribir uno que engañe al verificador—modificando un archivo para que parezca que completó una tarea sin realmente hacerlo. Tres capas de defensa bloquean esto: el entorno y la suite de pruebas son inmutables y están fuera del alcance del modelo, un monitor determinista marca cualquier intento de acceder a rutas restringidas o alterar scripts de verificación, y un modelo juez congelado se sitúa por encima del verificador automatizado como veto.
Los números
El modelo insignia de 397.000 millones de parámetros obtuvo 82,4 en SWE-bench Verified—una prueba donde una IA recibe un bug real de un repositorio open-source de GitHub y debe corregirlo sin ver la suite de pruebas, calificado como el porcentaje de problemas que resuelve exitosamente.
Eso supera el 80,8 de Claude Opus 4.7 y el 80,6 de DeepSeek-V4-Pro en la misma prueba. En Terminal Bench 2.1—89 tareas ejecutadas dentro de entornos terminales en contenedores que van desde depurar código asíncrono hasta resolver vulnerabilidades de seguridad, calificadas por tasa de finalización—obtuvo 77,5 frente al 70,3 de Claude Opus 4.7.
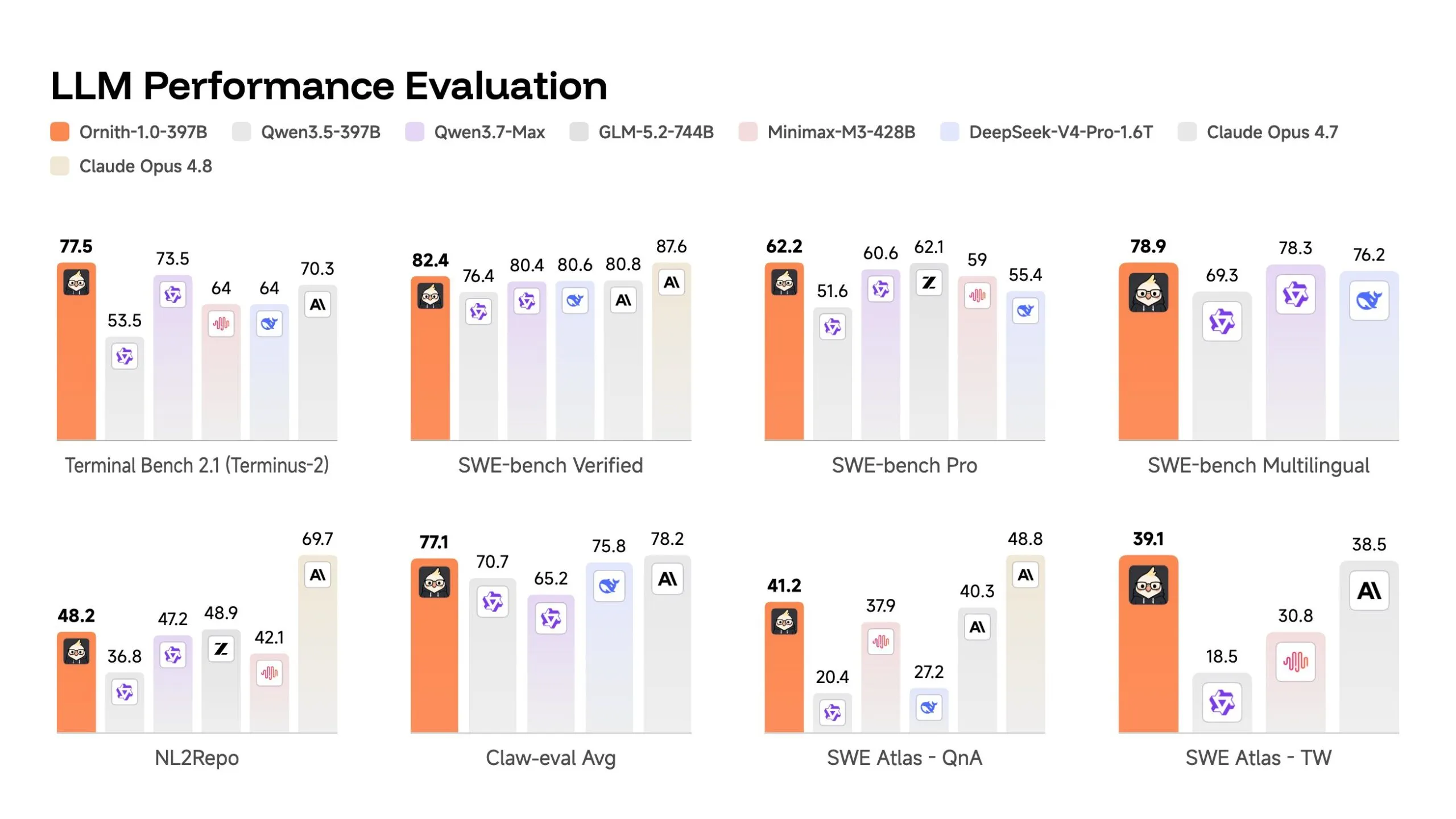
Dado que las preocupaciones sobre contaminación de SWE-bench se han planteado públicamente—OpenAI argumentó a principios de este año que los modelos estaban inflando sus puntuaciones al memorizar soluciones de benchmarks vistas durante el entrenamiento—Ornith también reporta números en SWE-bench Pro, una versión más difícil que utiliza bases de código más diversas y menos filtradas, calificada de la misma manera. El modelo de 397.000 millones obtuvo 62,2 ahí. Significativamente más bajo, pero aún competitivo con el resto del campo, y todavía mejor que Deepseek V4 Pro.
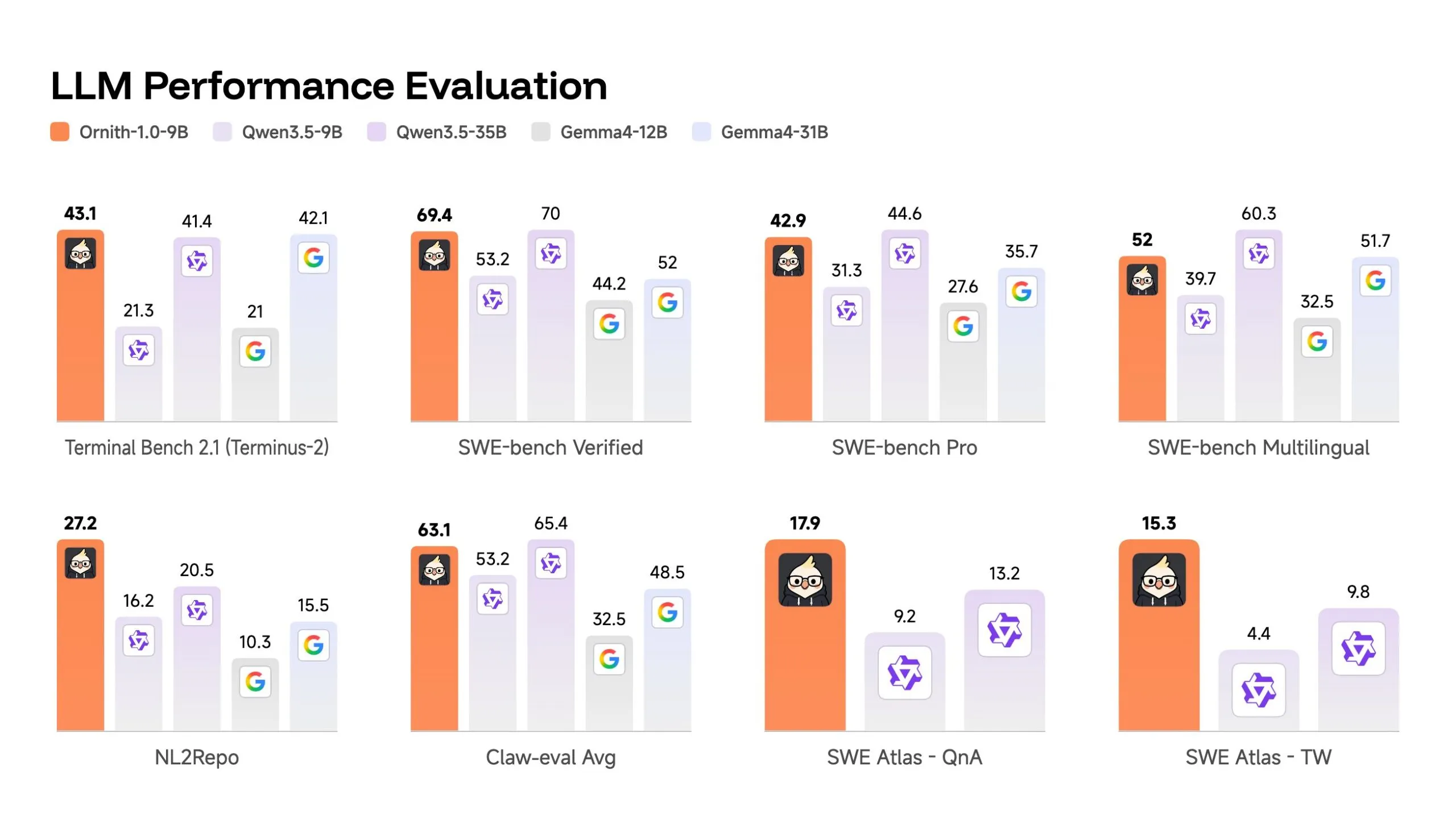
El modelo de 9.000 millones de parámetros podría ser el dato más interesante. Obtuvo 69,4 en SWE-bench Verified—más alto que el 52 de Gemma 4-31B y competitivo con el 70 de Qwen 3.5-35B, a pesar de ser 3-4 veces más pequeño.
Para quién es, y para quién no
Ornith-1.0 no es explícitamente una IA de propósito general. La propia documentación del modelo indica que puede tener un rendimiento inferior en tareas fuera de la codificación agéntica. Si quieres que una IA resuma un documento, te ayude a escribir tu tesis doctoral o redacte un correo electrónico, Ornith-1.0 no es la opción adecuada.
Está optimizado para un conjunto reducido de problemas: pipelines de desarrollo donde un agente de IA recibe la descripción de una tarea, opera dentro de un repositorio de código o sesión de terminal, y completa trabajo de múltiples pasos sin intervención. Esta es una herramienta construida para personas que ya están ejecutando infraestructura de agentes—no para personas que están decidiendo si vale la pena usar IA.
El titular de "supera a Claude" es real, pero requiere contexto. Como reportó Decrypt, todos los laboratorios ahora persiguen el rendimiento en evaluaciones de codificación agéntica, porque ahí es donde están las diferencias de rendimiento realmente útiles.
Ornith-1.0-397B sí supera a Claude Opus 4.7 en dos benchmarks de codificación diferentes, pero el modelo insignia actual de Anthropic, Claude Opus 4.8, obtiene puntuaciones más altas. La comparación que se sostiene es dentro de la categoría open-source, con cantidades de parámetros comparables, en tareas de agentes específicas de codificación.
Para desarrolladores que construyen pipelines de codificación autoalojados, infraestructura agéntica o trabajo similar enfocado en código, los modelos pequeños y medianos que funcionan en hardware edge pueden ser genuinamente útiles, pero el usuario promedio probablemente esté mejor buscando en otra parte.