

En Resumen
- Google lanzó DiffusionGemma, un modelo de texto de código abierto que genera tokens en paralelo y alcanza 1.000 por segundo en una H100.
- A diferencia de los LLMs autorregresivos, usa atención bidireccional, lo que lo hace superior en relleno de código y salidas estructuradas.
- El modelo está disponible gratis bajo licencia Apache 2.0 en Hugging Face, aunque ejecutarlo localmente aún requiere configuración manual avanzada.
Google lanzó hoy DiffusionGemma, un modelo de IA de código abierto que genera texto de la misma manera en que los generadores de imágenes crean imágenes: comienza con ruido y lo refina hasta que tenga sentido. Alcanza 1.000 tokens por segundo en una NVIDIA H100. (Los tokens son la unidad básica de información que maneja un modelo de IA.) Eso lo hace cuatro veces más rápido que el Gemma convencional. Además es gratuito, bajo licencia Apache 2.0, con pesos disponibles en Hugging Face.
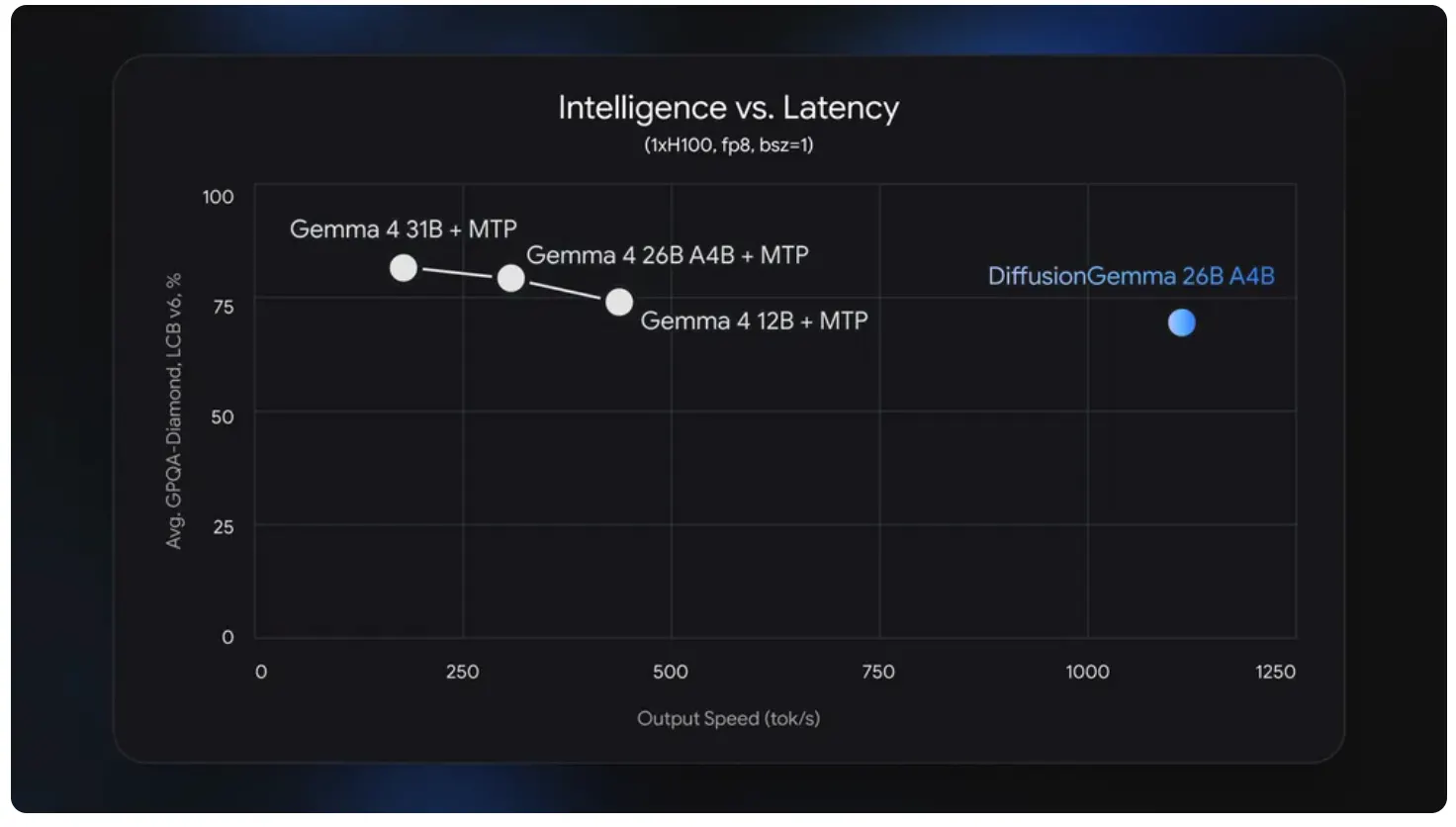
Sin embargo, como siempre, está en la letra pequeña. Según el anuncio de Google, el modelo alcanza "700+ tokens por segundo en NVIDIA GeForce RTX 5090". También queda por debajo del Gemma 4 estándar en calidad de respuesta.
El propio Google lo reconoce. Es un modelo de velocidad, no una mejora de calidad.
Qué hace realmente
Todos los LLMs que has usado funcionan como una máquina de escribir: un token a la vez, donde cada palabra depende de la anterior. Así es como funcionan las arquitecturas autorregresivas.
DiffusionGemma no opera de esa manera. En lugar de generar tokens de forma secuencial, parte de fragmentos refinados de texto desordenado en paralelo. Según la guía para desarrolladores de Google, "comienza con un lienzo de tokens marcadores de posición aleatorios" y va fijando de forma iterativa los tokens con mayor confianza hasta que el bloque completo toma forma. Doscientos cincuenta y seis tokens por pasada hacia adelante. La GPU se mantiene ocupada.

El efecto secundario es la atención bidireccional: cada token puede ver a todos los demás tokens mientras se genera, algo imposible en los modelos autorregresivos (estos no pueden anticipar lo que se codificará después). Eso lo hace especialmente bueno en tareas donde el final de la respuesta condiciona el inicio: relleno de código, salida estructurada, problemas con muchas restricciones, entre otros. Google ajustó una versión para resolver Sudokus como demostración. El modelo base resolvió aproximadamente el 0% de los rompecabezas correctamente.
La versión ajustada alcanzó el 80%.
La difusión de texto ha sido un proyecto de investigación durante años. MDLM, SEDD, LLaDA, Dream: modelos académicos que demostraron que el enfoque funcionaba a pequeña escala y que en su mayoría permanecieron como pruebas de concepto. Inception Labs lanzó Mercury 2 en febrero de 2026 como el primer modelo de razonamiento por difusión comercial, con velocidades cinco veces superiores a las de los competidores optimizados para velocidad.
Sin embargo, ninguno de ellos era de pesos abiertos, y ninguno llegó con soporte desde el primer día en vLLM, Hugging Face Transformers y Unsloth. DiffusionGemma es el primer lanzamiento abierto importante de un laboratorio de primer nivel.
También vale la pena señalar una ironía histórica. Los generadores de imágenes comenzaron como modelos de difusión (de ahí el nombre Stable Diffusion) y ahora están migrando hacia arquitecturas autorregresivas en busca de mayor calidad. Los modelos de lenguaje comenzaron como autorregresivos y ahora están experimentando con la difusión para ganar velocidad.
Por qué es difícil de ejecutar… por ahora
Ejecutar DiffusionGemma de forma eficiente requiere un "borrador" (drafter): un módulo ligero que propone bloques de tokens en paralelo, que el modelo principal verifica en una sola pasada hacia adelante. Esto se denomina decodificación especulativa. DFlash es un framework publicado a inicios de 2026 que utiliza un pequeño modelo de difusión como borrador, lo que permite una aceleración de más de 6x en algunas tareas. Es el motor que hace práctica esta clase de modelos.
El problema: DiffusionGemma necesita un borrador específico para ejecutarse localmente a través de MLX, el framework de machine learning de Apple para Apple Silicon. Ese módulo no existe en ninguna versión pública de mlx-lm, en ningún pull request abierto, ni en el runtime incluido en LM Studio.
Intentamos ejecutar DiffusionGemma con Hermes a través de NVIDIA NIM. El modelo cargó, pero luego: "agent init failed: Model google/diffusiongemma-26b-a4b-it has a context window of 8.192 tokens, which is below the minimum 64.000 required by Hermes Agent."
Para ser precisos: la ventana de contexto real de DiffusionGemma es de 256K tokens. La cifra de 8.192 fue un error de configuración por defecto de Nvidia, no una limitación arquitectónica del modelo.
En la práctica, configurarlo correctamente para uso agéntico requiere un trabajo manual que la mayoría de los usuarios aún no ha resuelto, y Hermes Agent simplemente no se inicializa sin ello. La velocidad en paralelo no sirve de nada si el agente no puede arrancar.
Se espera que en los próximos días la comunidad genere mejores recursos para ejecutar estos modelos.
Para quién es realmente
Desarrolladores con hardware NVIDIA RTX 4090 o 5090 que estén construyendo herramientas en tiempo real: editores en línea, autocompletado, relleno de código, generación estructurada. Ese es el objetivo. Como *Decrypt* informó en mayo, Google ha mantenido una línea constante de trabajo para hacer la inferencia local más rápida sin necesidad de nuevo hardware.
Para los investigadores, la generación bidireccional abre un territorio al que los modelos autorregresivos simplemente no pueden acceder: secuencias de proteínas, grafos matemáticos, cualquier caso donde la posición N dependa de la posición N+50. Eso no es un detalle menor.
Google lanzó Gemma 4 bajo Apache 2.0 en abril, y DiffusionGemma continúa esa estrategia. Ya hay un borrador de pull request para llama.cpp abierto a la fecha. Cuando las herramientas se pongan al día, este modelo llegará a una audiencia mucho más amplia.
En una máquina con una GPU discreta capaz, 1.000 tokens por segundo es real.