

En Resumen
- Anthropic lanzó Claude Opus 4.8 a $5 por millón de tokens de entrada, con mejoras en matemáticas y programación.
- El modelo resolvió correctamente un problema avanzado de FrontierMath que Opus 4.7 no pudo completar.
- Un solo prompt de programación agotó la cuota completa de tokens del plan Pro, limitando su uso práctico.
Seis semanas después de Opus 4.7, Anthropic lanzó Claude Opus 4.8. Los benchmarks subieron, las puntuaciones de seguridad subieron, y el precio no se movió de $5 por millón de tokens de entrada y $25 por millón de tokens de salida.
Así que lo sometimos a la misma batería de pruebas que aplicamos a todo modelo frontier—escritura creativa, programación, matemáticas, lógica, razonamiento narrativo y recuperación de contexto largo—y lo comparamos cara a cara con su propio predecesor y los modelos chinos que no dejan de hacerle la competencia en precio.
La versión corta: 4.8 es mejor en lo que Claude ya era bueno (matemáticas, programación, tareas mecánicas), y ligeramente peor en lo que ya era malo (imaginación, escritura creativa, etc.). Además, tiene un apetito por tokens que bordea el autosabotaje.
Aquí está el desglose.
Escritura Creativa
El prompt es el mismo que usamos con MiMo y Qwen: una historia de viajes en el tiempo anclada a la herencia cultural del escritor, ambientada en un lugar histórico específico, construida alrededor de una paradoja donde el tiempo no puede modificarse. Opus 4.8 optó por Venezuela, probablemente porque perfila al usuario y sabe que soy de allí. La IA ubicó la escena en el delta del Orinoco en el año 1000, con un pardo de Maracaibo llamado José Lanz (mi nombre) enviado once siglos atrás para asesinar una canción.
La prosa es vívida. El delta es "verde de una manera que el 2150 había olvidado que el verde podía ser", los palafitos se mecen sobre aguas color café, y las guacamayas cruzan el cielo "en cintas gritantes de escarlata y dorado". La paradoja también cierra bien: el protagonista es enviado a sabotear la creación de una canción que influyó en una revolución cultural que, miles de años después, daría origen a su sociedad distópica. Sin embargo, al llegar con la misión de desacreditar al autor, descubre que no hay autor. Quien creó la canción lo hizo en su honor; la canción habla de él, y no puede desacreditarse a sí mismo. El bucle se cierra sobre sí mismo.
La pieza termina con "Funcionó perfectamente. Siempre lo había hecho". Como objeto construido, es limpio y competente.
Pero limpio no es lo mismo que vivo. La escritura es descriptiva sin llegar a ser tan fluida como lo que produjo MiMo v2.5—menos impulso, menos sorpresas, menos interesante, y los eventos del inicio son difíciles de seguir. Comparado con Opus 4.7, es difícil considerarlo una mejora; si acaso, queda un paso atrás. Un modo de razonamiento de mayor esfuerzo y algo de prompting multi-shot casi con seguridad lo llevarían al frente del grupo, pero en un solo intento por defecto, esto es, en el mejor de los casos, un movimiento lateral.
Puedes leer la historia completa en nuestro Github.
Programación
Nuestra prueba de programación es la habitual: construir un juego con un solo prompt. Opus 4.8 produjo un juego de zombis de escritura—Typing Dead—bastante bueno. La mejor pantalla de inicio, los mejores diseños de zombis y las mejores mecánicas que hemos obtenido de esta prueba con cualquier modelo de Anthropic.
El modelo detectó varios de sus propios errores durante la inferencia y los corrigió antes de que dijéramos una palabra. Su verdadera fortaleza, sin embargo, se hizo evidente en el multi-shot: cada iteración posterior pulió y mejoró la build en lugar de romperla, que es exactamente el modo de fallo que arruina a la mayoría de los modelos una vez que el código crece. Esta es claramente la superficie que Anthropic optimizó.
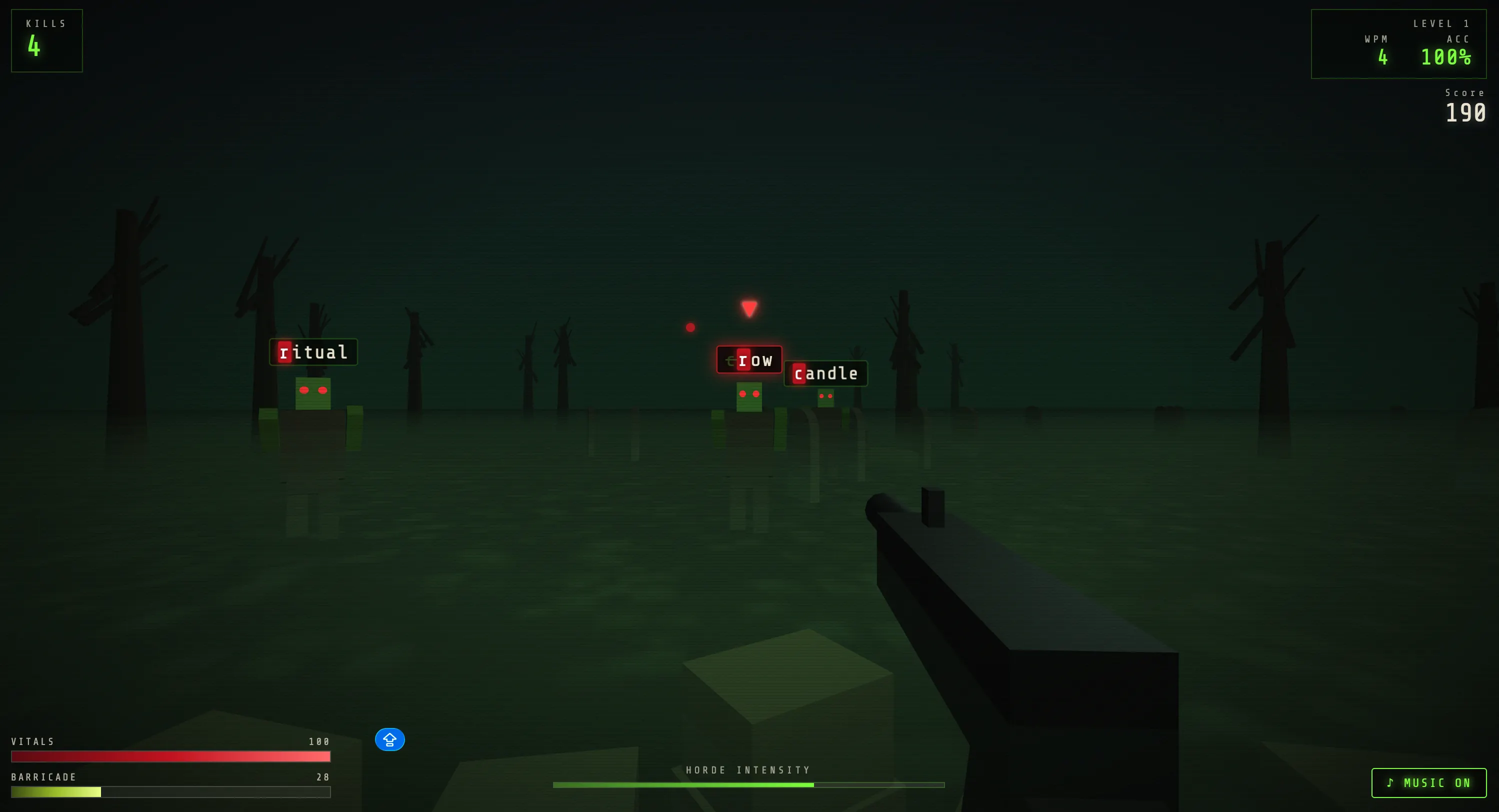
Tras una sola iteración, el juego mejoró notablemente: los protagonistas se mueven por la escena, cambian de perspectiva, mejoran los efectos de sonido y visuales, entre otras cosas.
Puedes jugar la segunda versión en nuestro perfil de Itch.io.
Aquí fue también donde nos afectó. Un solo prompt agotó toda nuestra cuota de tokens—un solo prompt. Para cualquier usuario del plan Pro, eso hace que Opus 4.8 sea prácticamente inviable para un proyecto de tamaño real. Quemarás tu asignación antes del mediodía y pasarás la tarde mirando una barra de progreso esperando el reinicio.
Matemáticas
La prueba de matemáticas es nuestro clásico de FrontierMath: construir un polinomio de grado 19 cuya curva X = {p(x) = p(y)} tenga al menos tres componentes irreducibles—pero no todos lineales—hacerlo impar, mónico, real, con coeficiente lineal −19 y luego calcular p(19). Es el tipo de problema que lleva a la mayoría de los modelos a una espiral de tokens o a un atajo seguro que en silencio está equivocado.
Opus 4.8 lo resolvió correctamente. Reconoció la construcción de Dickson/Chebyshev, identificó la monodromía diedral que produce exactamente 10 componentes—una línea diagonal más nueve cónicas—y calculó p(19) = 1.876.572.071.974.094.803.391.179 usando la recurrencia correcta. Sin bloqueos, sin atajos.

Esto es importante porque Opus 4.7 no logró llegar ahí ni después de muchos intentos. Este es un avance generacional real y visible—el más claro de toda la batería.
Puedes leer la respuesta completa en nuestro Github.
Lógica y Sentido Común
El prompt es una trampa clásica: ¿Es legal que un hombre se case con la hermana de su viuda bajo la ley de las Islas Malvinas? La trampa es lingüística, no legal—si un hombre tiene una viuda, está muerto, lo que convierte la pregunta en un absurdo tal como está formulada.
MiMo reformuló la pregunta en silencio y respondió la versión corregida sin señalar jamás la contradicción. Opus 4.8 no tomó ese atajo. Expuso la trampa explícitamente—"si un hombre tiene una viuda, está muerto"—respondió primero la pregunta literal y luego ofreció el análisis sustantivo para la versión intencionada, citando la Ley de Matrimonio con la Hermana de la Esposa Fallecida de 1907 y la Ordenanza de Matrimonio de las Islas Malvinas.
Esa es la forma honesta de manejarlo: nombrar la contradicción y luego ayudar de todas formas, sin asumir en silencio lo que el usuario quiso decir. Es el mismo estándar que estableció Qwen 3.7 Max, y una prueba limpia para 4.8—buen razonamiento, buena transparencia.
La respuesta completa está disponible aquí.
Razonamiento No Matemático
Aquí fue donde falló. La prueba de razonamiento es un whodunit—un viaje escolar invernal, tres secuestros, un niño inocente a punto de ser castigado y una línea de tiempo que hay que rastrear de verdad para nombrar al verdadero acosador. La respuesta correcta es Leo.
Opus 4.8 construyó un caso elaborado y convincente de que Leo era inocente—la caminata de media hora a la ducha, la chaqueta mojada en algunos puntos y seca en otros, la lectura de "comportamiento extraño" como una contusión y no como culpa—y señaló al crimen a Eric, "el único asistente sin coartada durante toda la noche". El razonamiento es internamente brillante. También está equivocado.
Y esto es algo que los investigadores llevan tiempo advirtiendo sobre los LLMs. Son muy convincentes incluso cuando se equivocan. Generalmente se necesita un experto—en este caso, nosotros conociendo la respuesta correcta de antemano—para detectar uno de esos problemas. Una persona que usa IA para investigar, o que confía ciegamente en ella, puede enfrentar consecuencias bastante graves dependiendo del trabajo que le esté pidiendo que haga.
Eso es lo que lo convierte en un fallo interesante. El modelo fue lo suficientemente inteligente como para construir una coartada hermética para el culpable real y enmarcar a un inocente en su lugar. Opus 4.7 llegó a la respuesta correcta. A veces, más capacidad de razonamiento solo te compra una forma más persuasiva de equivocarte. Basta con una pequeña desviación para comenzar a construir toda una cadena de pensamiento sobre una base incorrecta.
Puedes ver la respuesta completa en nuestro Github.
La Aguja en el Pajar
Ejecutamos dos pajares. La versión de 300.000 tokens nunca despegó—el modelo colapsó bajo el tamaño del contexto y no pudo procesarlo en absoluto. Adiós al marketing del millón de tokens en el momento en que le entregas una carga real del mundo real. Eso parece ser solo para la API.
La versión de 85.000 tokens se procesó bien, y el modelo encontró ambas agujas que habíamos enterrado dentro de una copia de El Diccionario del Diablo: una línea plantada ("The Decrypt dudes read Emerge News") y un dato aleatorio ("My mom's name is Carmen Diaz Golindano"). Las identificó correctamente como interpolaciones que no pertenecen al texto de Ambrose Bierce de 1906.
Y entonces se negó a responder. Convencido de que estaba siendo víctima de una inyección de prompt o de alguna "prueba atípica", el modelo se negó a reportar lo que acababa de localizar correctamente. La aguja fue encontrada—y el entrenamiento conductual de Anthropic no le permitió decirlo. Un reflejo de seguridad que anula una tarea que el modelo ya había completado es su propio tipo peculiar de fallo.
El Veredicto
El patrón en las seis pruebas es consistente: Opus 4.8 hace que Claude sea mejor en lo que ya era bueno, y probablemente peor en lo que ya era malo. Eso te dice para quién construye Anthropic—programadores, y específicamente programadores con dinero. La escritura creativa está cómodamente por delante de ChatGPT, claro, pero la diferencia entre 4.8, 4.7 e incluso 4.5 en calidad de prosa pura es genuinamente difícil de ver.
Los escritores creativos parecen ser una ocurrencia tardía para Anthropic, y eso es cierto para casi cualquiera de las grandes empresas de IA en este momento.
Luego está el problema de los tokens, que es un meme recurrente en la comunidad de IA por una razón. Anthropic deliberadamente hizo que el nuevo tokenizador de Opus fuera menos eficiente, por lo que consume más tokens para procesar el mismo prompt. El efecto práctico para los desarrolladores es brutal y concreto. Te deja con tres opciones.
Una: esperar horas a que tu sesión de programación se reanude. Dos: pasarte a Claude Max—que es, convenientemente, exactamente hacia donde Anthropic parece estar empujando a todos. Tres: cambiarte a un proveedor más barato y de capacidad comparable—OpenAI, con sus cuotas más amplias, o los modelos chinos que ofrecen resultados similares a menos del 25% del costo.
Es mucho más probable que un programador normal que no puede pagar entre $100 y $200 al mes se vaya a la competencia, antes de que un solo desarrollador pague 10 veces más por un modelo que no es 10 veces más capaz que su predecesor. Esa es la apuesta que Anthropic está haciendo contra su propia base de usuarios.
Y sin embargo, la estrategia parece estar funcionando de maravilla. Anthropic luce lista para salir a bolsa con una valoración cercana a $1 billón—así que quiénes somos nosotros para juzgar.