

In brief
- Meituan officially unveiled LongCat-2.0 on June 30, revealing it as the model behind "Owl Alpha."
- The anonymous Model had ranked first on Hermes Agent, second on Claude Code, and third on OpenClaw by call volume.
- Standard API pricing is $0.75 per million input tokens and $2.95 per million output tokens—well under GPT-5.5's $5/$30 and Claude Sonnet 5's introductory $2/$10.
Chinese tech company Meituan officially unveiled LongCat-2.0 on June 30, confirming the open-license, 1.6-trillion-parameter mixture-of-experts AI model is the same system that spent two months running anonymously on OpenRouter under the alias Owl Alpha.
Parameters are the total number of dials a model can handle during training. The model activates roughly 48 billion of its parameters per token (the smallest unit of data an AI model processes), with that figure swinging between 33 billion and 56 billion depending on how demanding the query is.
The stealth period paid off. By the time Meituan stepped forward, the model had already taken first place on the Hermes Agent workspace, second on Claude Code, and third across OpenClaw deployments, all ranked by monthly call volume.
This is the first trillion-parameter model trained and deployed end-to-end on domestic Chinese ASICs, not just served on them after training elsewhere. DeepSeek's V4-Pro, by comparison, used Huawei chips only for inference while pretraining ran on Nvidia hardware.
Meituan says the pretraining run, spanning more than 35 trillion tokens across a cluster of over 50,000 domestically produced accelerators, finished with "no rollbacks or irrecoverable loss spikes." That stability claim matters given how often large training runs on unproven hardware stacks fail midway through and how China seems to be reducing its dependence on U.S. hardware to train its models.
Price is where LongCat-2.0 makes its real case. Standard API access runs $0.75 per million input tokens and $2.95 per million output, cut to $0.30/$1.20 during the current launch promo, with cached context reads free of charge. That undercuts GPT-5.5's $5/$30 per million tokens, Claude Sonnet 5's introductory $2/$10 rate, and lands close to DeepSeek V4-Pro's permanent $0.435/$0.87 and Xiaomi's MiMo-V2.5 Pro, which matched that same rate after its own May price cuts.
Meituan also provides a token plan, which makes things even cheaper for coders and heavy users, offering packs of 1 billion tokens at around $60.
We ran LongCat-2.0 through a quick game-building test ourselves. It got the job done, and the output held up reasonably well after a few rounds of iteration. The result landed visibly behind Claude Fable and Opus 4.8, making it easier to rank near Sonnet 4.6, but the quality-per-dollar math is hard to argue with at these prices.
It made the waves of enemies come from different angles with the camera auto centering on the nearest enemy. However, the model’s logic didn’t take into consideration what happens when the number of enemies increases with difficulty. At higher speeds, the target-switching logic became erratic; the focus would jump to a closer enemy in the middle of a typing prompt, making the game frustratingly unplayable.
This is normal in vibe coding sessions, where models don’t foresee many logical consequences of a decision, and instead focus on delivering a result based on what the user prompts, literally.
This is also why a cheap model is always a good option, because it gives the user more chance to iteratively improve every result until the final product meets expectations.
If anything, without further interaction, at first glance the overall quality lands somewhere in between DeepSeel v4 Flash and Deepseek v4 Pro in our quick coding tests.
You can check out the results in our itch.io site
How Meituan built it
LongCat-2.0 uses several techniques to make the model faster and more capable without dramatically increasing its size.
Its attention system, based on DeepSeek's design, focuses only on the most relevant parts of very long conversations instead of processing everything equally, helping it respond more quickly.
Also, a new N-gram embedding system (a way of helping understand groups of words or subwords together) gives the model a much richer understanding of words and phrases—about 100 times more possible representations—without adding many more AI components. It’s basically teaching the AI to recognize common phrases instead of just individual words. Rather than seeing "New," "York," and "City" as three separate pieces, it can also treat "New York City" as a single meaningful concept. This gives the model a much richer understanding of language without making it dramatically larger.
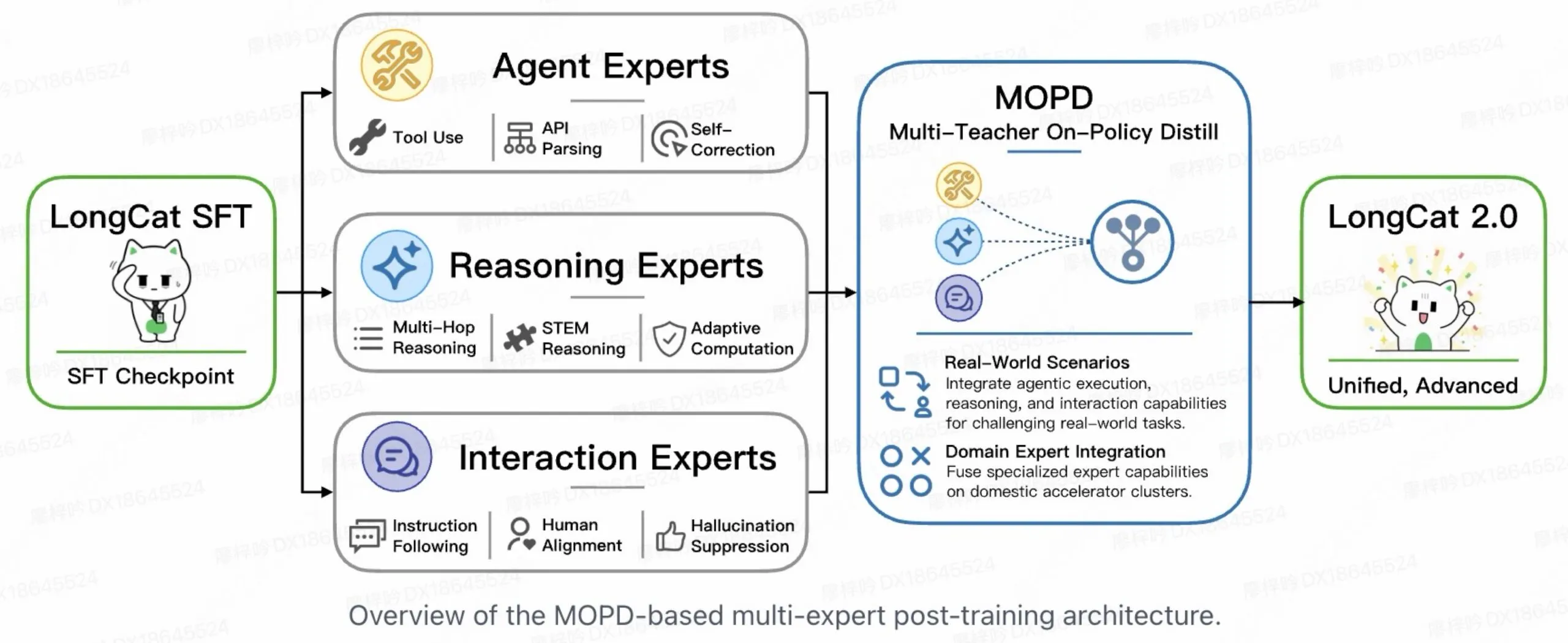
After training, Meituan also combines three specialized systems, one focused on using tools (Agent), one on solving problems (Reasoning), and one on conversations (Interaction). A routing mechanism then decides which combination of those specialists should handle each request, much like assigning the right team to the right job.
On SWE-bench Pro, a benchmark that scores how often a model resolves real GitHub issues pulled from production codebases, LongCat-2.0 hit 59.5, ahead of GPT-5.5's 58.6 and Gemini 3.1 Pro's 54.2, though still behind Claude Opus 4.7 and 4.8. On FORTE, which grades agents on day-to-day office tasks across 15 professions under a 45-minute time limit, it scored 73.2, tied with Claude Opus 4.6 but trailing GPT-5.5's 77.8.
Introducing LongCat-2.0 🐱
1.6T parameters · MoE with ~48B active · 1M context
The full model behind Owl Alpha on @OpenRouter — now available.Built for agentic coding from the ground up:
◆ LongCat Sparse Attention (LSA) — scales efficiently for 1M-context tokens
◆… pic.twitter.com/zum2SdZ0Z2— Meituan LongCat (@Meituan_LongCat) June 30, 2026
Teams building coding agents on a budget, or anyone running high-volume repository-scale work where the free context-cache reads compound, get the clearest win. The model is reachable today through Meituan's OpenAI- and Anthropic-compatible API endpoints, or through agent harnesses like Hermes, Claude Code, and OpenClaw that already integrate it.
Anyone who needs to self-host is out of luck for now. Both the GitHub and Hugging Face repositories still read "model weights coming soon," but Meituan has not set a date for when the files will ship.