

En Resumen
- Un estudio de Lenz Research halló que cinco modelos de IA discreparon en 672 de 1.000 verificaciones, con desacuerdo severo en el 34%.
- En el 34% de los casos un modelo calificó una afirmación como verdadera mientras otro la catalogó como falsa, según los investigadores.
- Los cinco modelos solo coincidieron en 328 afirmaciones, sin lograr consenso unánime en ningún caso de la categoría "mayormente verdadero".
Pregunta a cinco de los sistemas de inteligencia artificial más avanzados del mundo si una afirmación es verdadera, y en dos tercios de los casos, al menos uno te dará una respuesta diferente. Eso es lo que concluye un nuevo estudio publicado este mes por el investigador Kosta Jordanov en Lenz Research.
El estudio proporcionó a GPT-5.4, Claude Opus 4.7, Gemini 3 Pro, Gemini 3 Pro con Search y Sonar Pro las mismas 1.000 afirmaciones reales de verificación de hechos enviadas por usuarios. Los modelos debían elegir una de cuatro etiquetas: verdadero, mayormente verdadero, engañoso o falso.
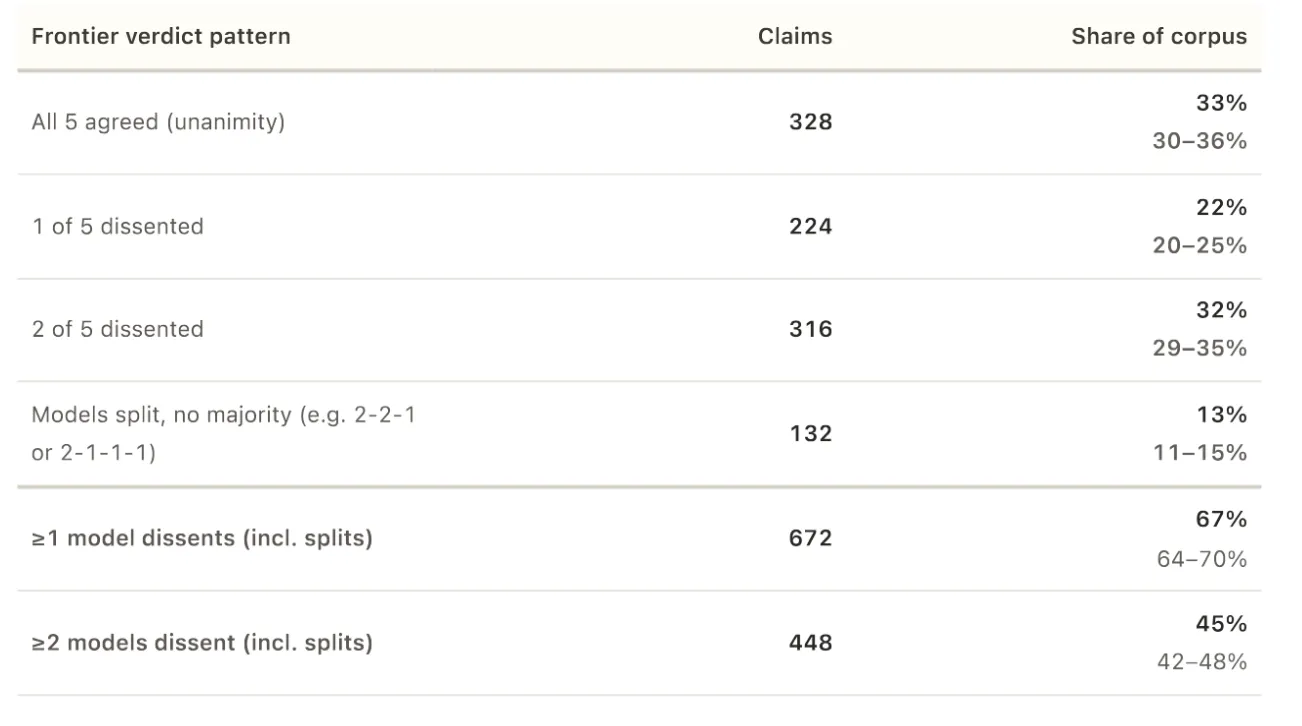
En 672 de las 1.000 afirmaciones, al menos un modelo se apartó de la mayoría. En el 34% de los casos, el desacuerdo fue severo: un modelo calificó una afirmación como verdadera mientras otro la calificó como falsa.
"Estos no son elementos de referencia con claves de respuesta públicas; son afirmaciones que usuarios reales enviaron para verificación a una plataforma de fact-checking", señala el estudio. "Solo un veredicto puede ser correcto por afirmación, por lo que cualquier desacuerdo entre el panel significa que al menos el veredicto de un modelo es inconsistente con la etiqueta bajo este esquema de 4 categorías".
Estudios anteriores sobre alucinaciones en IA han demostrado que los chatbots inventan hechos. Ese es un problema. Este es otro distinto. Los modelos no necesariamente fabrican información; simplemente no logran ponerse de acuerdo en juicios fácticos básicos sobre el mismo material.
La investigación utilizó una metodología que dificulta que las empresas de IA puedan desviar las críticas. En lugar de extraer afirmaciones de conjuntos de pruebas estándar —del tipo que suele filtrarse en los datos de entrenamiento—, los investigadores usaron afirmaciones enviadas por personas reales a la plataforma de verificación de Lenz. "La mayoría de estas afirmaciones es poco probable que aparezcan en algún corpus de entrenamiento con una etiqueta gold adjunta; no hay una clave de respuesta canónica con la que hacer coincidencias de patrones, ni una clasificación de referencia a la que anclarse", señala el artículo.
La medida estadística de acuerdo, denominada alfa de Krippendorff, fue de 0,639 en una escala donde 1,0 significa acuerdo perfecto y 0 equivale al azar. El estudio afirma que esto indica "un acuerdo no trivial pero limitado". "Los veredictos de los modelos tienen una estructura, no son aleatorios, pero no son lo suficientemente consistentes como para tratar el panel como un juez único e intercambiable", señalaron los investigadores. En general, la comunidad científica considera que cualquier valor por debajo de 0,8 es débil.
Cuando los cinco modelos sí coincidieron —lo que ocurrió en solo 328 de las 1.000 afirmaciones—, casi nunca acordaron que algo fuera engañoso o mayormente verdadero. Solo cuatro afirmaciones recibieron un veredicto unánime de "engañoso". Ninguna recibió un "mayormente verdadero" unánime.
Los investigadores proporcionaron ejemplos de afirmaciones donde los modelos mostraron mayor divergencia, como: "La cartera activa del Banco Mundial en Nigeria supera los $16.400 millones a partir de 2025". ChatGPT 5.4 la calificó como "mayormente verdadera", mientras que Gemini 3 Pro la consideró "falsa" y su modelo hermano Gemini 3 Pro + Search la clasificó como "engañosa".
En otro ejemplo, se les presentó a los modelos la siguiente afirmación: "Donald Trump dijo que un ataque contra Irán fue pospuesto a petición de los aliados del Golfo". GPT-5.4 la calificó como falsa, Claude Opus 4.7 la consideró mayormente verdadera, Gemini 3 Pro dijo que era falsa, y Gemini 3 Pro + Search la catalogó como verdadera.
"El panel converge en veredictos definitivos; es en el centro del esquema donde se fractura", concluyeron los investigadores. La unanimidad solo se dio en los extremos: la afirmación era definitivamente verdadera o definitivamente falsa.
Esto importa porque cada vez más personas recurren a sistemas de IA para verificar información. Si pegas una afirmación de un artículo en ChatGPT, Claude o Gemini, podrías obtener tres respuestas distintas. ¿A cuál le crees?
A las empresas de IA les encanta afirmar que sus modelos son cada vez más precisos. Publican puntajes de referencia que muestran mejoras constantes. Sin embargo, el estudio de Lenz puso a prueba estos modelos con el tipo de afirmaciones irregulares y ambiguas sobre las que realmente discuten los seres humanos, y descubrió que los modelos también discuten.
El artículo es cuidadoso al señalar esto. "Una mayoría de modelos de frontera no es una verdad absoluta. El veredicto mayoritario a veces está equivocado; un modelo disidente individual a veces tiene razón. Usamos la mayoría como punto de referencia estructural para medir el desacuerdo, no como sustituto de la corrección".
Hay un problema más profundo oculto en los números. Cuando los modelos no coinciden, al menos uno de ellos debe estar equivocado —el estudio califica el veredicto de un modelo como "inconsistente con la etiqueta bajo este esquema de 4 categorías"—. No existe un mecanismo de desempate, ni una instancia de apelación. Reportajes recientes sobre la confiabilidad de la IA han generado alertas similares.
De las 328 afirmaciones en que los cinco modelos coincidieron, ninguna recibió un "mayormente verdadero" unánime. La categoría de los matices se vació por completo. Si los modelos de IA solo encuentran consenso en los extremos, ¿pueden realmente confiarse como verificadores de hechos?