

En Resumen
- StepFun lanzó StepAudio 2.5 Realtime, un modelo de voz en tiempo real que obtuvo 82,18 en comprensión paralingüística frente a 80,46 de GPT.
- El modelo resuelve el problema de salida de personaje mediante RLHF específico y datos de más de 10.000 semillas escritas por humanos.
- StepFun, fundada en 2023 por un exdirector de Microsoft, ha recaudado $1.700 millones y compite directamente con OpenAI en voz en tiempo real.
El laboratorio de IA con sede en Shanghái StepFun lanzó StepAudio 2.5 Realtime esta semana. Es un modelo de voz en tiempo real de extremo a extremo: el audio entra, el audio sale, sin conversión de texto en el medio. Admite chino e inglés y, según los benchmarks, parece ser bastante bueno.
El laboratorio es mejor conocido por desarrollar LLMs de texto que superan a sistemas mucho más grandes. Step 3.5 Flash, un modelo de 196.000 millones de parámetros, encabezó cuatro benchmarks de razonamiento a principios de este año frente a rivales de un billón de parámetros. (Los parámetros son lo que le dan a un modelo de IA su amplitud de conocimiento y, en términos generales, se traduce en un mejor rendimiento.)
El trabajo de voz sigue el mismo esquema y busca hacer que el juego de roles sea atractivo, especialmente en sesiones más largas.
El problema del personaje
Los sistemas de personas de IA tienen un modo de fallo específico: OOC, o comportamiento fuera del personaje —el modelo se desvía de su personalidad asignada bajo presión adversarial. Es algo vergonzosamente común y es un defecto que existe en todos los modelos de IA por diseño. Simplemente olvidan cosas cuanto más interactúas con ellos.
StepFun afirma haber resuelto esto con RLHF específico para juego de roles —aprendizaje por refuerzo a partir de retroalimentación humana aplicado específicamente a la estabilidad del personaje, no solo a la calidad general. Los datos de entrenamiento parten de más de 10.000 semillas de personas escritas por humanos, expandidas algorítmicamente en una matriz de características a escala de un millón.
La idea: suficiente variedad en los datos de entrenamiento para que incluso las conversaciones extrañas y poco frecuentes no saquen al modelo de su personaje.
La afirmación técnicamente más interesante es la comprensión paralingüística —el modelo lee señales acústicas no verbales como la velocidad vocal, el tono emocional y la edad directamente del audio, antes de formular una respuesta.
En el benchmark de comprensión paralingüística —una prueba objetiva que mide la percepción de características acústicas como la emoción y la velocidad del habla, puntuada de 0 a 100— StepAudio obtuvo 82,18. GPT Realtime 1.5 anotó 80,46, Gemini Live llegó a 58,05 y DouBao Realtime quedó en 16,09.
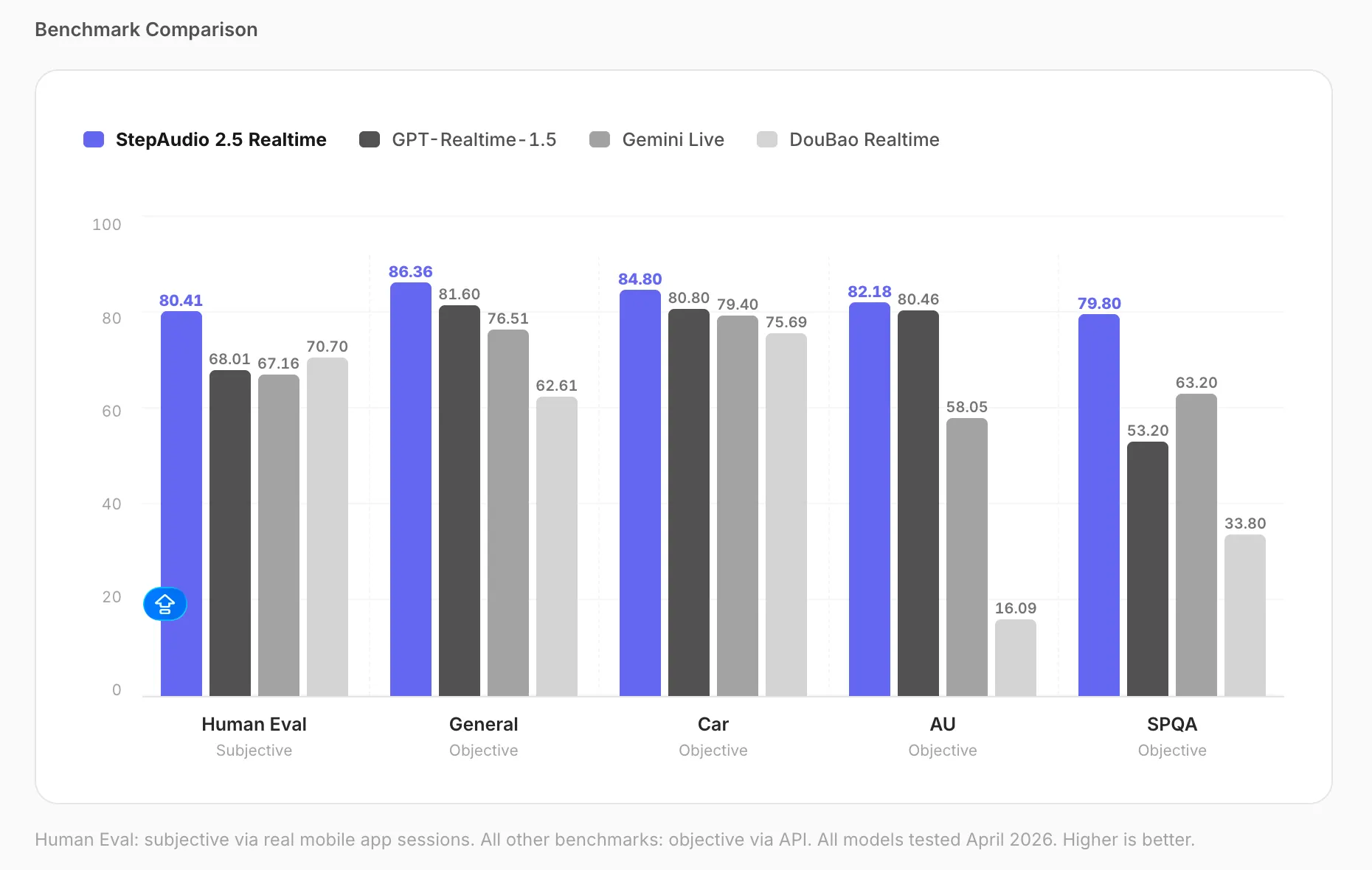
El benchmark de evaluación humana —usuarios reales conversando con el modelo a través de una app móvil, calificados por evaluadores humanos en una escala de 0 a 100— arrojó 80,41 para StepAudio, frente a 68,01 de GPT Realtime 1.5 y 67,16 de Gemini Live. La calidad general del diálogo, probada objetivamente mediante API en la misma escala de 0 a 100, llegó a 86,36 frente al 81,60 de GPT.
Estos son los propios benchmarks de StepFun. Saque sus conclusiones. Sin embargo, los márgenes en paralingüística y sesiones de preguntas y respuestas habladas son lo suficientemente amplios como para no ignorarlos.
El contexto de StepFun
StepFun fue fundada en abril de 2023 por Jiang Daxin, quien pasó 16 años en Microsoft dirigiendo proyectos como Bing, Cortana y los servicios cognitivos de Azure. Es una de las llamadas startups de IA Tiger de China y ha recaudado aproximadamente $1.700 millones hasta la fecha.
El modo de voz avanzado de OpenAI se lanzó a finales de 2024 y estableció el estándar que todos los demás persiguen. StepFun ahora se compara directamente contra él —y afirma haberlo superado.
El lanzamiento incluye una persona de IA insignia llamada Xiao Yue, que StepFun describe como una "compañera a nivel del alma" diseñada para sentirse como hablar con un amigo por mensaje, no como consultar un software. Opiniones, frases características, límites emocionales —totalmente configurables.
Los desarrolladores pueden crear sus propias personas a través de la API. La documentación completa está en platform.stepfun.com, y el modelo ya está disponible.