

En Resumen
- DeepSeek hizo permanente su descuento del 75% en V4-Pro, mientras Xiaomi recortó precios de MiMo-V2.5 hasta un 99%.
- DeepSeek V4-Pro cuesta $0,87 por millón de tokens de salida, frente a los $25 de Claude Opus 4.7 y $30 de GPT-5.5.
- La brecha entre modelos chinos y estadounidenses oscila entre 15 y 30 veces en relación precio-calidad este trimestre.
DeepSeek hizo permanente el 75% de descuento en DeepSeek V4-Pro, que estaba programado para expirar, a principios de esta semana. Y ahora el laboratorio chino de IA Xiaomi redujo los precios de la API de MiMo-V2.5 hasta en un 99% para entradas en caché. Dos de los modelos de IA más capaces del mercado acaban de volverse agresivamente más baratos, mientras que los laboratorios estadounidenses se movieron en la dirección opuesta.
Una explicación rápida para los que no son desarrolladores: cuando usas ChatGPT o Claude en un navegador, pagas una suscripción fija, o nada. Cuando una empresa construye un producto sobre un modelo de IA, paga por token, donde un token equivale aproximadamente a tres cuartas partes de una palabra. Cada mensaje enviado, cada respuesta generada, cada documento procesado: todo se acumula a una tasa medida en millones de tokens.
Una API es el canal que hace posible esto, permitiendo que una app, un agente, un sitio web, etc., utilice el modelo en su propio entorno. Por eso, el precio por token determina si un producto impulsado por IA es económicamente viable o un pozo sin fondo.
Los planes de tokens son una capa de suscripción sobre todo eso. Compras créditos por adelantado y el modelo los va consumiendo. La actualización de facturación de Xiaomi ofrece a los usuarios entre 5 y 8 veces más tokens al mismo precio. El plan Max de $100 ahora te da 82.000 millones de tokens, frente a los 1.600 millones anteriores.
Para dimensionarlo: 82.000 millones de tokens equivalen a más de 60.000 millones de palabras.
Por qué los recortes son reales y no solo marketing
Fuli Luo, director del equipo MiMo de Xiaomi y exdesarrollador clave de DeepSeek que codesarrolló DeepSeek-V2, publicó una explicación técnica en X. Los mayores ahorros provienen de una forma más inteligente de almacenar y reutilizar información que la IA ya ha procesado. En lugar de repetir el mismo trabajo, el sistema de Xiaomi puede recordar muchos más datos a la vez, aproximadamente cinco veces más que antes, lo que significa que la IA necesita mucha menos potencia de cómputo, reduciendo los costos de almacenamiento y procesamiento en cerca de un 80%.
Behind the MiMo API Price Reduction:
The deepest price cut, up to 99%, is for Input (Cache Hit). The core reason is our inference framework now supports hierarchical KV cache optimization for SWA. Production inference engine tests show this optimization increases cached token…— Fuli Luo (@_LuoFuli) May 27, 2026
"Operando a estos precios reducidos de API, nuestro motor de inferencia en producción está funcionando casi a plena capacidad, y aun así podemos básicamente cubrir costos", señaló Luo. "Si emergen más arquitecturas que ahorren cómputo y caché KV [Key-Value cache], junto con una mejor infraestructura de inferencia para reducir los costos de la API, esto formará un excelente ciclo virtuoso en la industria".
La arquitectura de DeepSeek llega al mismo lugar por un camino distinto. V4 utiliza dos tipos de atención intercalados: uno que comprime cada cuatro tokens para atención selectiva, y otro que colapsa cada 128 tokens para contexto global con un cómputo mínimo. Con un millón de tokens de contexto, la caché KV de V4-Pro representa el 10% del tamaño de su predecesor, y la inferencia de un solo token opera al 27% del costo de cómputo anterior.
El resultado es un modelo un 98% más barato que GPT-5.5 Pro con un rendimiento competitivo.
La apuesta de Silicon Valley
Claude Opus 4.7 cuesta $5 por millón de tokens de entrada y $25 por millón de tokens de salida. Anthropic mantuvo la tarifa sin cambios, pero lo lanzó con un nuevo tokenizador que puede generar hasta un 35% más de tokens para el mismo texto de entrada. El precio no subió, pero tu factura podría hacerlo.
GPT-5.5, lanzado a finales de abril, duplicó el precio de salida de su predecesor a $30 por millón de tokens. Gemini 2.5 Pro se ubica en $1,25 de entrada y $10 de salida, barato para los estándares estadounidenses.
DeepSeek V4-Pro es un modelo de 1,6 billones de parámetros que ofrece la base de conocimiento de un modelo masivo a una fracción del costo de cómputo. Ahora corre de forma permanente a $0,435 de entrada y $0,87 de salida por millón de tokens. Es un modelo que obtuvo un 80,6% en SWE-Verified frente al 80,8% de Claude Opus 4.6, un benchmark que mide la resolución real de issues en GitHub, no demos seleccionados a dedo. La brecha de precios entre modelos con esencialmente el mismo puntaje en codificación: 34x en salida.
MiMo-V2.5-Pro iguala esos mismos $0,435/$0,87 por millón de tokens tras los nuevos recortes. Los aciertos de caché bajan a $0,0036. Para dimensionarlo: es más barato por token de lo que la mayoría de personas paga por carácter en un SMS.
DeepSeek y Xiaomi no están solos
Estos recortes llegaron a un mercado donde los modelos chinos ya eran considerablemente más baratos antes de todo esto. MiniMax M2.7, que compite con Claude Opus en benchmarks de codificación según Artificial Analysis, cuesta $0,30 de entrada y $1,20 de salida por millón de tokens, aproximadamente el 5% de la tarifa de salida de Opus 4.7.
Kimi K2.5 de Moonshot AI, con un 76,8% en SWE-bench Verified, corre a $0,60 de entrada y $2,50 de salida. GLM-5.1 de Z.AI superó a Claude Opus 4.6 en un benchmark clave de codificación este trimestre. Cuatro modelos chinos de frontera se lanzaron en una ventana de 12 días a principios de mayo, todos por debajo de un tercio del costo por token de Opus 4.7.
Para una mejor visualización, este gráfico muestra cómo los modelos chinos se comparan con los tres proveedores de IA estadounidenses más populares (Anthropic, OpenAI y Meta) en términos de relación precio-calidad.
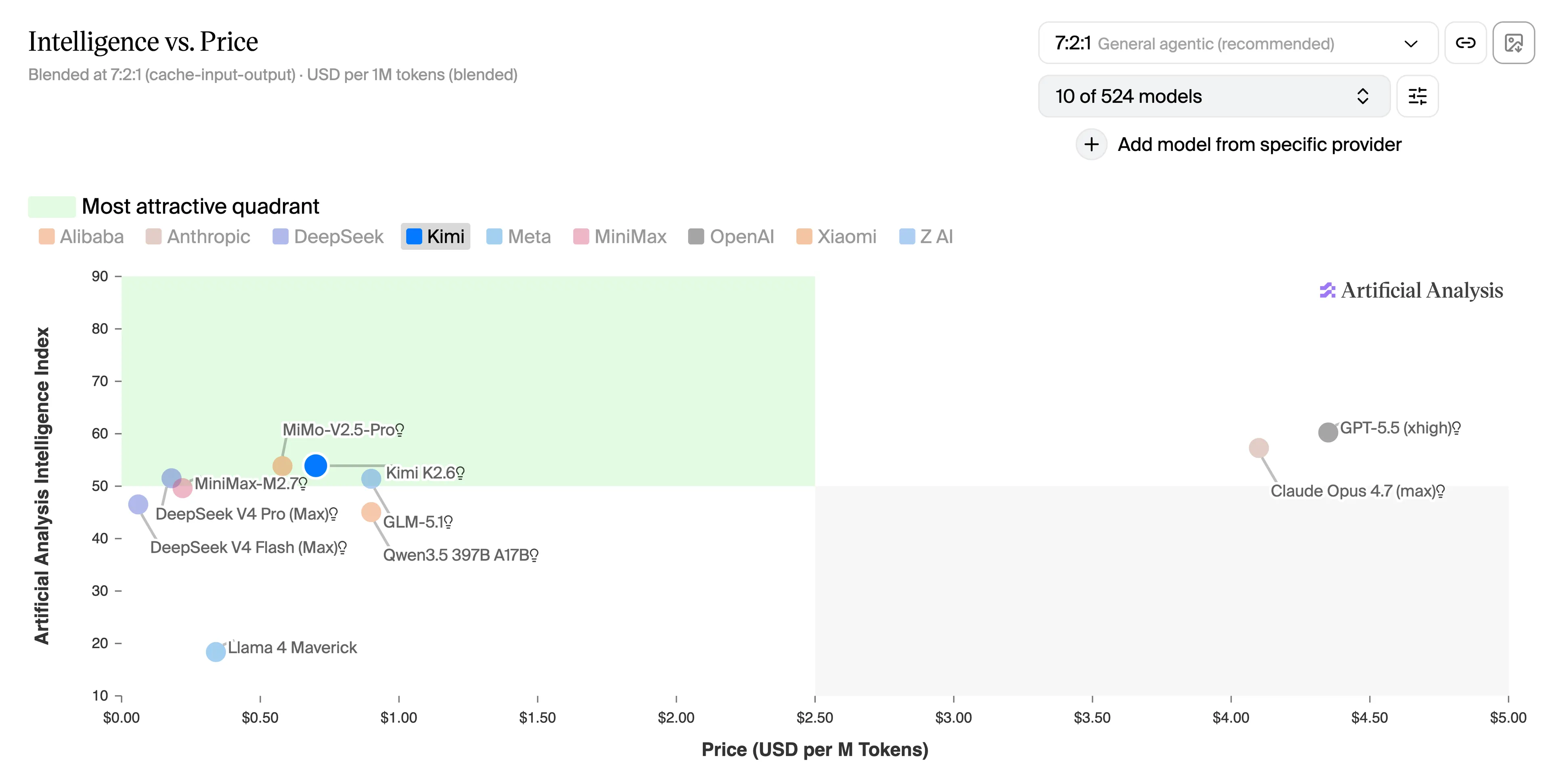
La brecha del segundo trimestre de 2026 entre los modelos de frontera chinos y estadounidenses se sitúa entre 15 y 30 veces, dependiendo de qué modelos se comparen, y esa es la línea base, antes de cualquier descuento por caché.
Lo que hacen los recortes de esta semana es reducir aún más esa brecha para las cargas de trabajo específicas que realmente corren en producción: pipelines de agentes con prompts de sistema estables, procesadores de documentos, herramientas de recuperación, todo aquello que golpea la caché constantemente. A $0,003625 por millón de tokens de entrada en caché, el costo de DeepSeek V4-Pro para contexto repetido es funcionalmente un error de redondeo.