
En Resumen
- Tencent lanzó Hy3 preview como código abierto con 295.000 millones de parámetros, desarrollado en menos de tres meses desde cero.
- El modelo subió de 53% a 74,4% en SWE-bench Verified y de 28,7% a 67,1% en BrowseComp, superando a DeepSeek-V3.2 en tareas agénticas.
- Tencent Cloud ofrece acceso a la API desde $0,18 por millón de tokens de entrada, posicionando a Hy3 como alternativa de alta eficiencia costo-rendimiento.
Tencent lanzó silenciosamente este jueves su modelo de IA más potente hasta la fecha, y los números en los benchmarks son difíciles de ignorar. Hy3 preview, el primer modelo de la compañía tras una reconstrucción total de su infraestructura, se lanzó hoy como código abierto en GitHub, Hugging Face y ModelScope.
También está disponible en el sitio web oficial de Tencent Cloud, bajo un plan de pago.
Hy3 cuenta con 295.000 millones de parámetros en total (una medida del potencial de conocimiento de un modelo), pero solo 21.000 millones activos en un momento dado. Esa es la ventaja de una arquitectura Mixture-of-Experts: el modelo dirige cada consulta a un subconjunto especializado de sus redes "expertas" en lugar de ejecutarlas todas a la vez. Menos cómputo, menor costo y una calidad de resultados similar. También admite hasta 256.000 tokens de contexto, suficiente para procesar una novela completa en un solo prompt.
El modelo fue desarrollado para equilibrar tres aspectos que Tencent afirma haber dejado de sacrificar entre sí: amplitud de capacidades, evaluación honesta y eficiencia de costos. Su anterior modelo insignia, Hy2, contaba con más de 400.000 millones de parámetros. Tencent dio marcha atrás explícitamente en esa cifra, argumentando que 295.000 millones es el punto óptimo donde el razonamiento madura por completo, pero el costo de agregar más parámetros deja de ser rentable.
Esto tampoco significa que el modelo sea inferior. Los modelos con mejor entrenamiento y menos parámetros superan con frecuencia a los modelos generalistas más grandes.
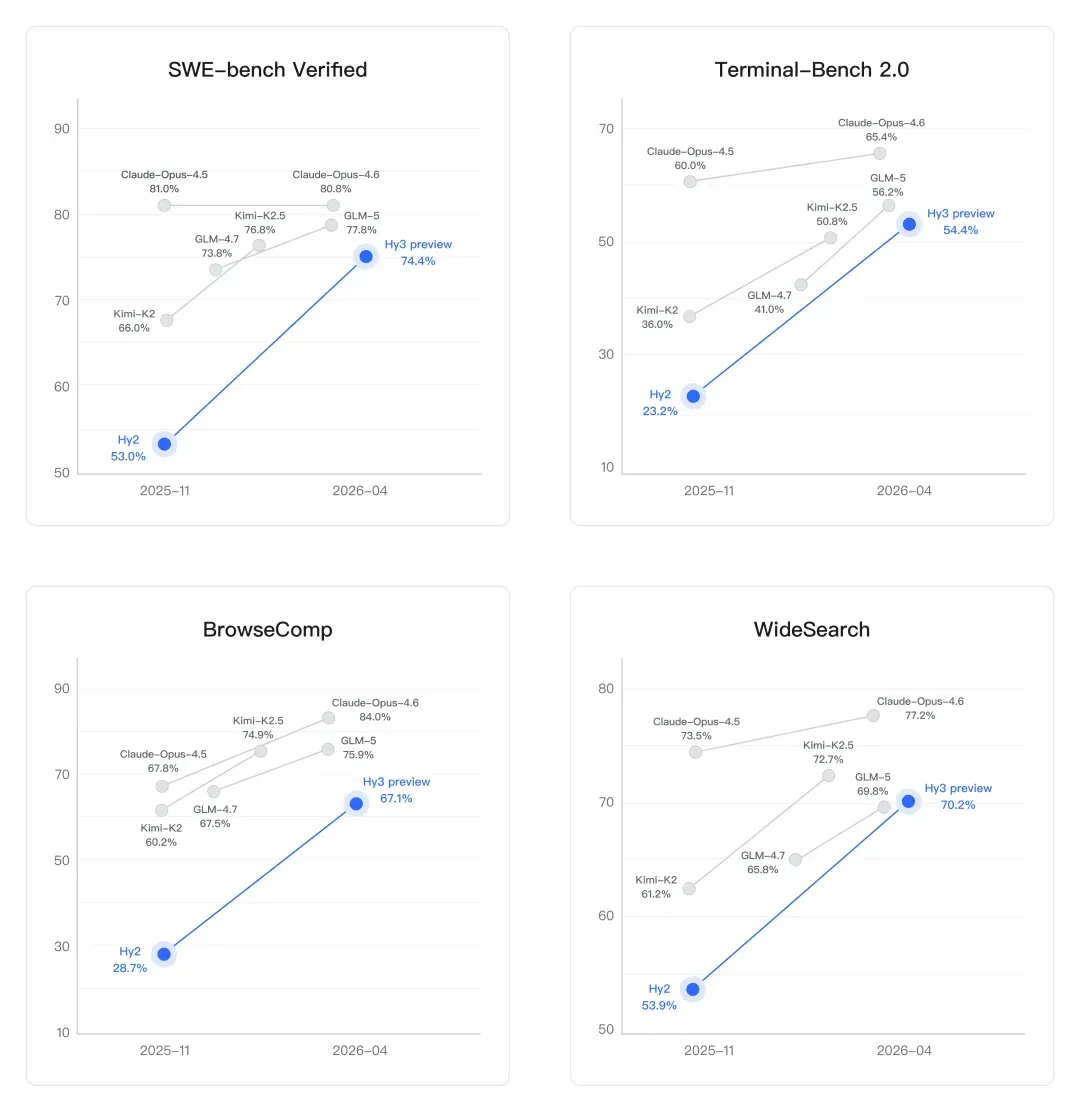
En programación, la mejora es notable. SWE-bench Verified es un benchmark que evalúa si un modelo puede corregir errores reales de repositorios de GitHub, no problemas simples, sino código de producción. Hy2 obtuvo un 53,0%. Hy3 preview alcanza un 74,4%. Eso representa un aumento del 40% en una sola generación, situándolo cerca de Claude Opus 4.6 (80,8%) y por encima de GLM-5 (77,8%) y Kimi-K2.5 (76,8%). Terminal-Bench 2.0, que mide la ejecución autónoma de tareas en un entorno real de línea de comandos, pasó del 23,2% al 54,4%, también un avance significativo.
Sin embargo, el modelo puede ser una opción muy interesante para quienes desarrollan con agentes. Los agentes manejan un conjunto muy complejo de instrucciones que involucran memorias, habilidades y llamadas a herramientas. Por lo general, omiten algo, lo que puede arruinar un flujo de trabajo o producir resultados deficientes. Por eso las capacidades agénticas se vuelven cada vez más importantes para los desarrolladores de IA, a medida que esta área se convierte en el tema más destacado de la industria. También por eso el modelo estuvo disponible de inmediato en Openclaw.
We're now live on @openclaw https://t.co/yfytwvZSe6
— Tencent Hy (@TencentHunyuan) April 23, 2026
Los agentes de búsqueda y navegación, donde los modelos deben recuperar, filtrar y sintetizar información de la web abierta sin orientación humana, también mostraron mejoras importantes. En BrowseComp, un benchmark que evalúa tareas complejas de investigación web, Hy3 preview alcanzó el 67,1% (frente al 28,7% de Hy2). En WideSearch, llegó al 70,2%, superando a GLM-5 y Kimi-K2.5, aunque por debajo del 77,2% de Claude Opus 4.6.
En razonamiento, el modelo superó a todos los competidores chinos en el examen de clasificación de doctorado en matemáticas de la Universidad de Tsinghua (primavera de 2026), con una puntuación de 88,4 en el promedio de tres ejecuciones avg@3. Se trata de un examen real, no de un conjunto de datos seleccionado, el tipo de evaluación que Tencent afirma priorizar para evitar la manipulación de benchmarks. El modelo también obtuvo 87,8 en CHSBO 2025 (la olimpiada nacional china de biología de secundaria), la más alta entre los modelos chinos en esa categoría.
Hy3 preview comenzó su entrenamiento a finales de enero de 2026 y se lanzó este jueves, menos de tres meses desde cero hasta su lanzamiento como código abierto. Un ritmo inusualmente rápido para un modelo de clase frontera. Tencent lo atribuye a una renovación de infraestructura realizada en febrero, liderada por Yao Shunyu, su principal científico de IA, quien impulsó una reconstrucción total del stack de preentrenamiento y aprendizaje por refuerzo.
Este es un enfoque muy diferente al que los laboratorios de IA chinos seguían hace un año, cuando el R1 de DeepSeek sacudió a la industria con su eficiencia de costos.
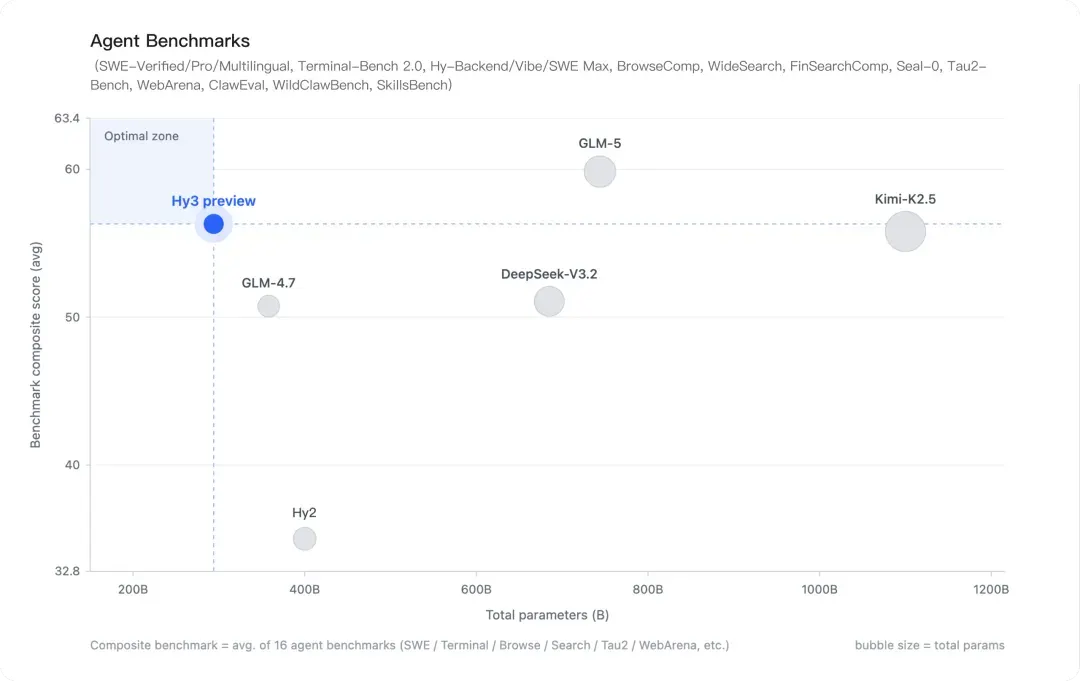
Hy3 todavía queda por detrás de los modelos insignia de OpenAI y Google DeepMind, pero por la relación tamaño-rendimiento, Hy3 preview es difícil de ignorar: el benchmark compuesto de agentes lo ubica en la "zona óptima" con aproximadamente 295.000 millones de parámetros, por delante de DeepSeek-V3.2 (más de 600.000 millones) y a la par de Kimi-K2.5 (más de un billón de parámetros) a una fracción del costo computacional.
Los modelos Hunyuan ya han sido desplegados en Yuanbao, CodeBuddy, WorkBuddy, QQ y Tencent Docs. En CodeBuddy y WorkBuddy, la latencia del primer token se redujo un 54%, el tiempo de generación de extremo a extremo cayó un 47%, y el modelo ejecutó con éxito flujos de trabajo agénticos de hasta 495 pasos. Tencent Cloud ofrece acceso a la API a aproximadamente $0,18 por millón de tokens de entrada y $0,59 por millón de tokens de salida, con paquetes personales del Plan Token desde unos $4,10 al mes.