

En Resumen
- Un desarrollador viralizó en Reddit una técnica que reduce hasta 75% los tokens de salida de Claude obligándolo a responder sin cortesías ni explicaciones.
- La habilidad fue empaquetada en GitHub con reducciones verificadas del 61% promedio en tareas de búsqueda, código y preguntas frecuentes.
- Expertos advirtieron que restringir el lenguaje del modelo podría afectar su razonamiento, y que los ahorros reales rondan el 25% al incluir tokens de entrada.
Entre la ingeniería de prompts y el performance art, un desarrollador publicó un descubrimiento en Reddit que hizo reír a la comunidad de IA antes de que le prestara atención: enseñar a Claude a comunicarse como un humano prehistórico y ver cómo tu factura de tokens se reduce hasta un 75%.
La publicación llegó a r/ClaudeAI la semana pasada y desde entonces acumula más de 400 comentarios y 10.000 votos —una combinación poco común de insight técnico genuino y comedia absurdista que internet suele premiar.

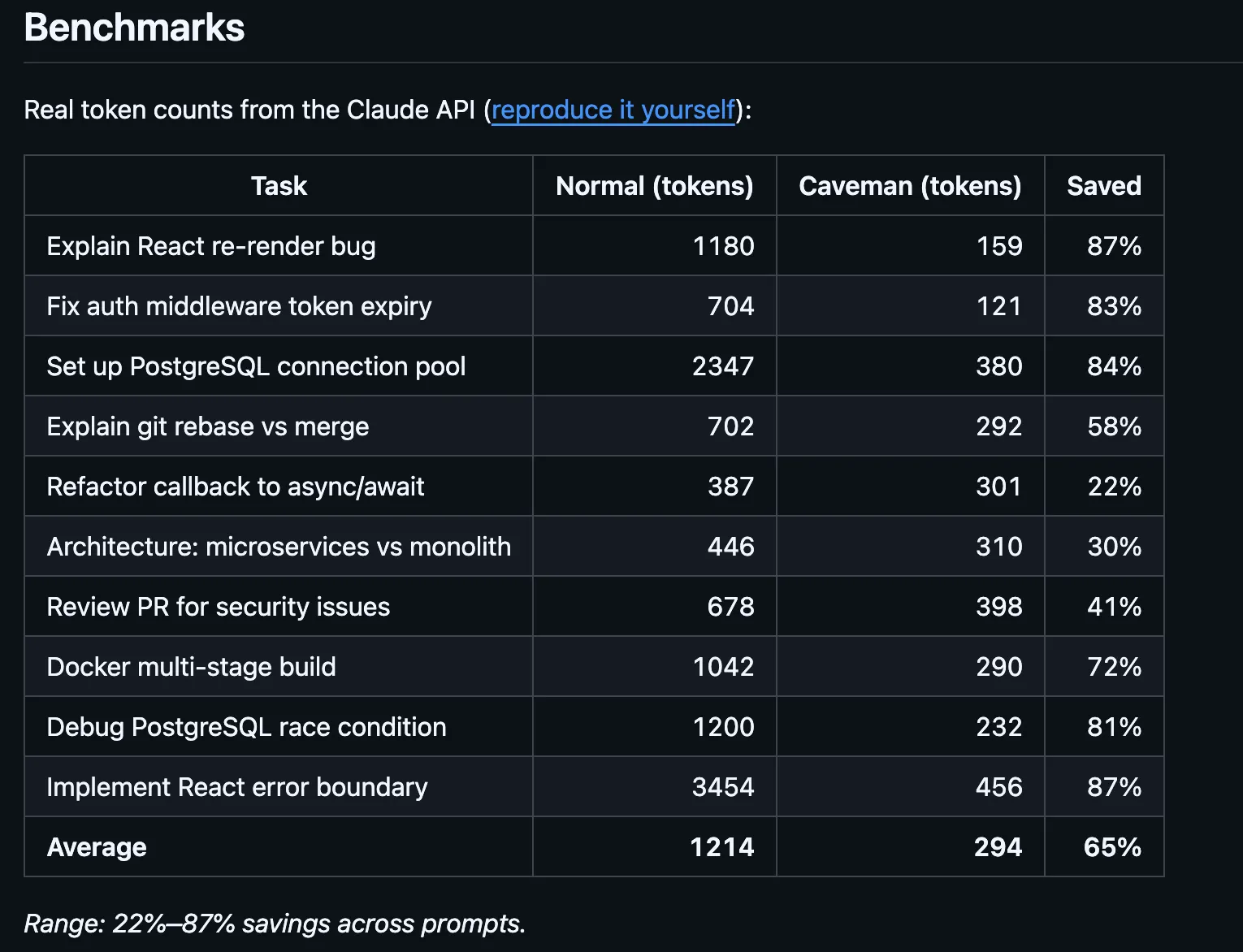
El mecanismo es simple. En lugar de dejar que Claude caliente con cortesías, narre cada paso que da y cierre ofreciendo más ayuda, el desarrollador limita al modelo a oraciones cortas y despojadas. La herramienta primero, el resultado primero, sin explicaciones. Una tarea normal de búsqueda web que rondaría los 180 tokens de salida bajó a unos 45. El autor original afirma reducciones de hasta el 75% en los tokens de salida, logradas haciendo que el modelo suene como si acabara de descubrir el fuego.
En términos de cavernícola, como dijo un usuario de Reddit: "¿Por qué perder tiempo diciendo muchas palabras cuando pocas palabras sirven?"
Lo que esta técnica no toca es el contexto de entrada: el historial completo de la conversación, los archivos adjuntos y las instrucciones del sistema que el modelo relee en cada turno. Esa entrada suele ser mucho mayor que la salida, especialmente en sesiones de programación largas. Las sesiones reales que contemplan toda esta entrada registran ahorros de alrededor del 25%, no del 75%. Sigue siendo significativo, solo que no es el número del titular.
También es buena idea alimentar al modelo con instrucciones normales. No darle el lenguaje de "cavernícola", ya que podría caer en una situación de "basura entra, basura sale".
Está además la pregunta sobre la degradación de la inteligencia. Un grupo de investigadores en el hilo argumentó que obligar a una IA a adoptar una personalidad menos sofisticada podría perjudicar activamente su calidad de razonamiento —que las restricciones verbales podrían trasladarse a las cognitivas. La preocupación no ha sido resuelta de forma definitiva, pero vale la pena considerarla al evaluar los resultados.
Habilidad buena, habilidad hacerse viral
Sin embargo, a pesar de las advertencias, la técnica encontró una segunda vida en GitHub casi de inmediato.
El desarrollador Shawnchee empaquetó las reglas en una caveman-skill independiente, compatible con Claude Code, Cursor, Windsurf, Copilot y más de 40 agentes adicionales. La habilidad destila el enfoque en 10 reglas: sin frases de relleno, ejecutar antes de explicar, sin metacomentarios, sin preámbulos, sin posdata, sin anuncios de herramientas, explicar solo cuando sea necesario, dejar que el código hable por sí mismo y tratar los errores como algo que se soluciona, no que se narra.
Los benchmarks del repositorio, verificados con tiktoken, muestran reducciones de tokens de salida del 68% en tareas de búsqueda web, del 50% en ediciones de código y del 72% en intercambios de preguntas y respuestas —para una reducción promedio del 61% en los tokens de salida en cuatro tareas estándar.
Un repositorio paralelo del desarrollador Julius Brussee adoptó un enfoque ligeramente distinto, planteando la misma idea como un archivo SKILL.md con 562 estrellas en GitHub. La especificación: responder como un cavernícola inteligente, eliminar artículos, rellenos y cortesías, conservar toda la sustancia técnica. Los bloques de código se mantienen intactos. Los mensajes de error se citan textualmente. Los términos técnicos permanecen igual. El cavernícola solo habla el envoltorio en inglés alrededor de los hechos.
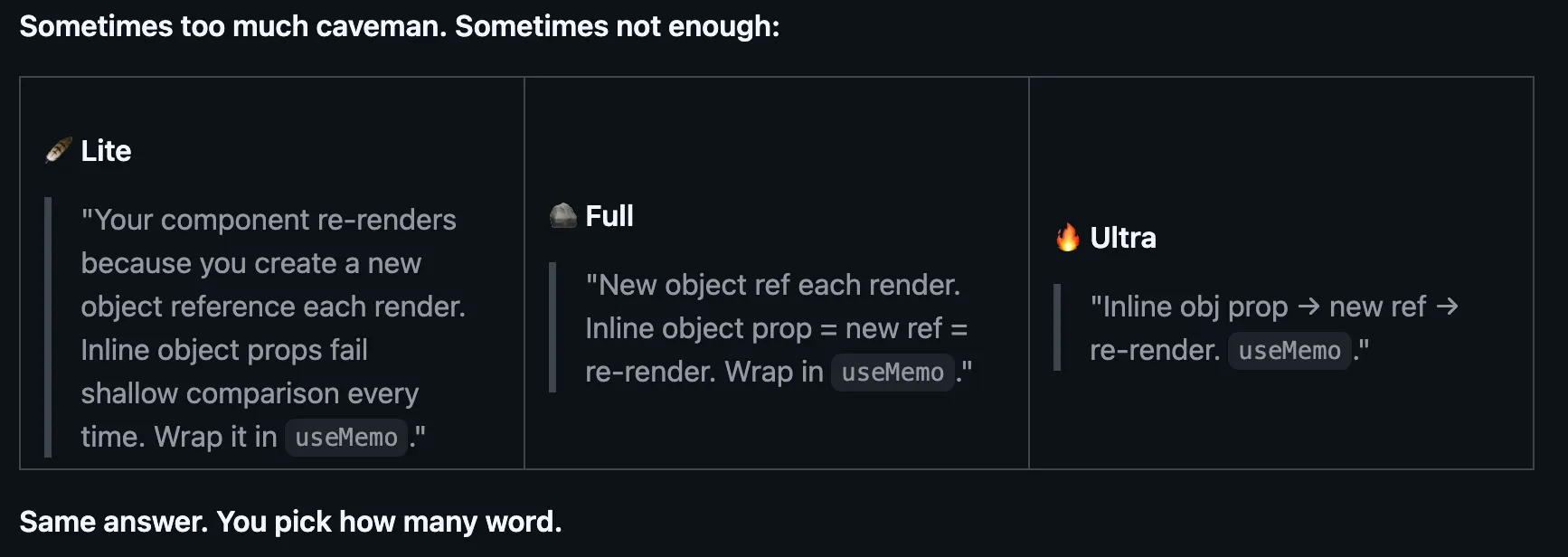
Este incluso viene con diferentes modos para controlar cuánto se quiere recortar, alternando entre Normal, Lite y Ultra. Los modelos hacen exactamente el mismo trabajo, pero ofrecen una respuesta mucho más corta, lo que genera un gran ahorro a lo largo del tiempo.
El contexto de costos más amplio le da al chiste un filo más agudo. Anthropic se encuentra entre los modelos más costosos en términos de precio por token. Para los desarrolladores que ejecutan flujos de trabajo agénticos con decenas de turnos por sesión, la verbosidad de los tokens de salida no es una queja estilística. Es una partida presupuestaria. Si un gruñido de cavernícola puede reemplazar un resumen de cinco oraciones sobre lo que el modelo acaba de hacer, esos tokens ahorrados se acumulan a lo largo de miles de llamadas a la API.
La habilidad de cavernícola se puede instalar con un solo comando a través de skills.sh y funciona globalmente en todos los proyectos. Independientemente de si hace a Claude marginalmente menos articulado, ya ha hecho que muchos desarrolladores se sientan significativamente menos frustrados.