

En Resumen
- Microsoft anunció Critique y Council para Copilot Researcher, combinando GPT y Claude en secuencia o en paralelo para investigación.
- En el benchmark DRACO, Copilot con Critique obtuvo 57,4 puntos frente a 42,7 del Claude Opus 4.6 solo, superando al resto por 14%.
- Ambas funciones requieren licencia Microsoft 365 Copilot ($30/usuario/mes) y estar inscrito en el programa Frontier de acceso anticipado.
La investigación profunda o deep research de IA ha sido una de las carreras armamentistas más intensas en tecnología este año. Google anunció su agente de investigación para Gemini en diciembre de 2024, OpenAI lanzó su propio agente de investigación en febrero de 2025, xAI de Elon Musk siguió el mismo camino, Perplexity redobló sus esfuerzos, y el Claude de Anthropic se ganó una base de seguidores leales entre profesionales que necesitan respuestas detalladas y citadas, presentando su agente en abril del año pasado.
Cada empresa ha intentado convencerte de que su modelo de IA es el investigador más inteligente. Pero ahora, Microsoft acaba de decir: ¿Por qué elegir solo uno?
La compañía anunció el lunes dos nuevas funciones para la herramienta Researcher de Copilot —llamadas Critique y Council— que ponen a trabajar en secuencia al GPT de OpenAI y al Claude de Anthropic en la misma tarea de investigación. El resultado, según las pruebas de Microsoft con un benchmark de la industria, supera a todos los sistemas incluidos en dicha prueba, incluyendo modelos de las principales empresas de IA.
Introducing Critique, a new multi-model deep research system in M365 Copilot.
You can use multiple models together to generate optimal responses and reports. pic.twitter.com/m4RlQmCKzs
— Satya Nadella (@satyanadella) March 30, 2026
"Critique es un nuevo sistema de investigación profunda multimodelo diseñado para tareas de investigación complejas. Separa la generación de la evaluación y utiliza una combinación de modelos de laboratorios de frontera, como Anthropic y OpenAI", explica Microsoft. "Un modelo lidera la fase de generación, planificando la tarea, iterando a través de la recuperación de información y produciendo un borrador inicial, mientras que un segundo modelo se enfoca en la revisión y el refinamiento, actuando como revisor experto antes de que se produzca el informe final".
Este es el problema básico que Critique está diseñado para resolver: todas las herramientas de investigación con IA funcionan hoy de la misma manera. Se hace una pregunta, un modelo planifica una búsqueda, rastrea fuentes, redacta un informe y te lo devuelve. Ese único modelo lo hace todo sin que nadie verifique su trabajo.
Esto puede resultar en alucinaciones, errores en las citas, afirmaciones falsas o inexactas, entre otros problemas.
Critique divide ese flujo de trabajo en dos. GPT se encarga de la primera fase: planifica la investigación, obtiene las fuentes y redacta un borrador inicial. Luego entra Claude como editor estricto, revisando el informe en cuanto a precisión factual, calidad de las citas y si la respuesta realmente abordó lo que se preguntó. Solo después de esa revisión llega el informe final al usuario. Microsoft señala que los roles eventualmente podrían invertirse, con Claude redactando y GPT revisando, aunque por ahora GPT va primero.
En el benchmark DRACO —una prueba estandarizada que abarca 100 tareas de investigación complejas en 10 áreas como medicina, derecho y tecnología— Copilot con Critique obtuvo 57,4 puntos, mientras que el Claude Opus 4.6 de Anthropic por sí solo alcanzó 42,7. El sistema combinado de Microsoft supera al siguiente mejor resultado por casi un 14%.
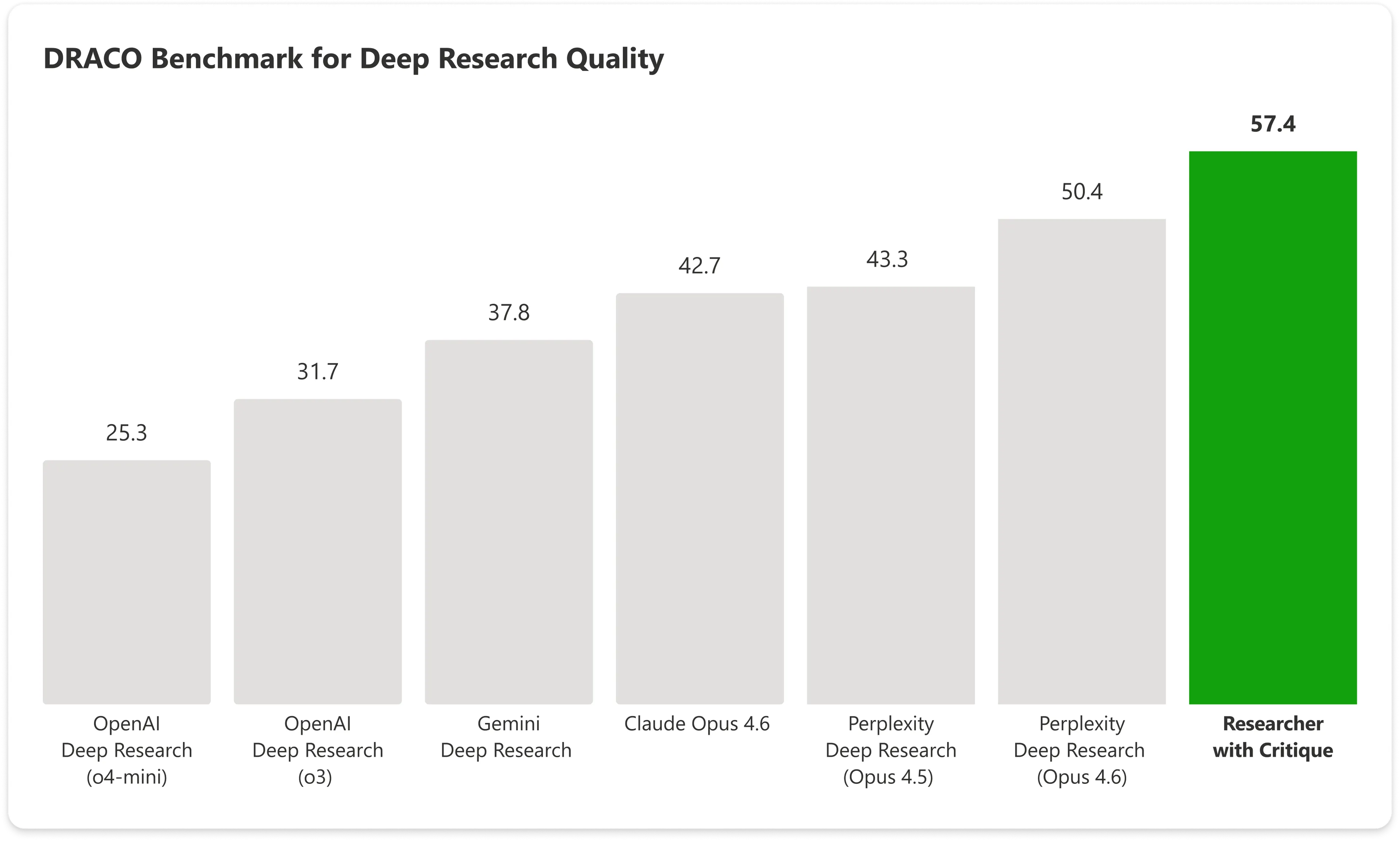
Las mayores mejoras se observaron en la amplitud del análisis y la calidad de la presentación, con la precisión factual también mostrando una mejora significativa.
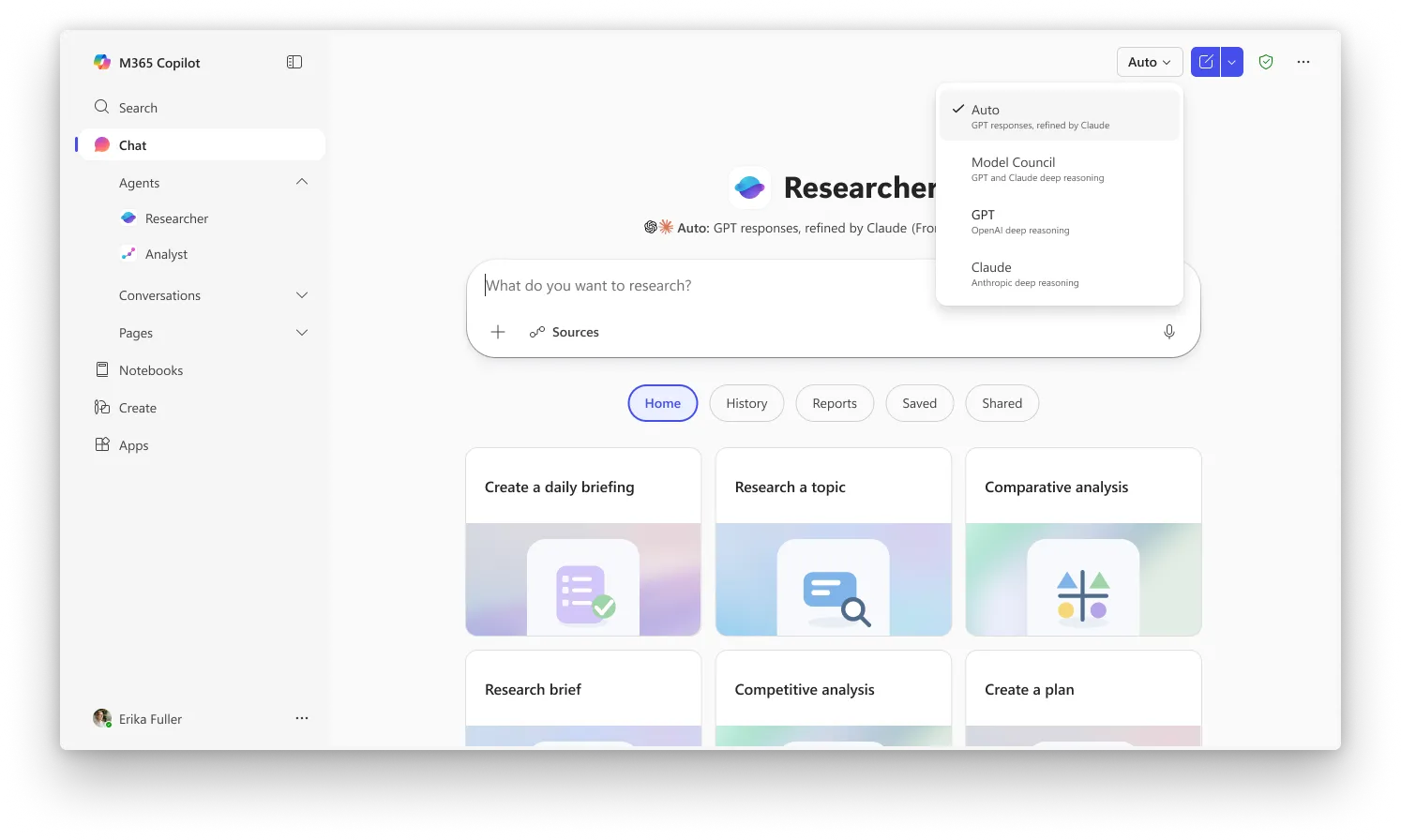
La segunda función, Council, aborda el mismo problema con un enfoque diferente. En lugar de que un modelo revise el trabajo del otro, Council ejecuta GPT y Claude simultáneamente y coloca sus informes completos uno al lado del otro. Un tercer modelo "juez" lee ambos y redacta un resumen que explica en qué coincidieron las dos IA, en qué divergieron y qué ángulos únicos captó cada una que la otra no detectó. Comparar manualmente las herramientas de investigación de IA era algo que los usuarios tenían que hacer por su cuenta hasta ahora.
En Critique, los modelos esencialmente colaboran entre sí, mientras que en Council los modelos compiten entre sí.
Critique es la experiencia predeterminada en Researcher, mientras que Council requiere seleccionar "Model Council" desde el selector para activar el modo de vista comparativa. Ambas funciones están disponibles actualmente para los usuarios inscritos en el programa Frontier de Microsoft, el canal de acceso anticipado a las capacidades más recientes de Copilot.
Se requiere una licencia de Microsoft 365 Copilot ($30/usuario/mes), pero los usuarios también deben estar inscritos en Frontier para acceder a ellas.
OpenAI y Microsoft mantienen una asociación multimillonaria, pero Microsoft apuesta a que ningún modelo se mantiene en la cima por mucho tiempo, y que el valor real está en la capa de orquestación que dirige las tareas hacia la combinación que mejor funcione.