

In brief
- Xiaomi lanzó MiMo-V2-Pro el 18 de marzo, un modelo de IA con más de un billón de parámetros que superó a Claude Opus 4.6 en escritura creativa.
- El modelo cobra $1 por millón de tokens de entrada frente a los $5 de Claude Opus, y ocupa el octavo lugar mundial en el Índice de Inteligencia de Artificial Analysis.
- MiMo-V2-Pro demostró debilidades en matemáticas de frontera, aunque su integración agéntica con OpenClaw no requiere configuración técnica previa.
La mayoría de los estadounidenses conoce a Xiaomi como esa marca de teléfonos baratos de China. Pero, es una lectura equivocada. Xiaomi es el tercer fabricante de smartphones más grande del planeta, solo por detrás de Apple y Samsung, con cerca de 170 millones de teléfonos enviados en 2025. Fabrica televisores, purificadores de aire, rastreadores de actividad física, scooters eléctricos, ropa y, ahora, automóviles.
El SU7 Ultra de Xiaomi estableció el récord en Nürburgring como el vehículo eléctrico de producción en serie más rápido el año pasado, superando a Rimac y Porsche. Recientemente se asoció con la blockchain Sei para preinstalar wallets cripto en sus dispositivos en Europa, América Latina y el Sudeste Asiático. La capitalización de mercado de la empresa ronda los $137.000 millones.
Entonces, cuando Xiaomi lanza un modelo de IA, quizás deberíamos prestarle atención.
El 18 de marzo, el brazo de investigación de IA de la compañía lanzó silenciosamente tres modelos a la vez: MiMo-V2-Pro, MiMo-V2-Omni y un modelo de texto a voz. El primer modelo de la nueva generación MiMo apareció en diciembre de 2025, cuando la empresa lanzó discretamente MiMo-V2-Flash—un capaz modelo de mezcla de expertos de 309.000 millones de parámetros—y casi nadie fuera de la comunidad de IA china le prestó atención. La prensa tecnológica occidental, en su mayoría, lo ignoró.
Luego, el 11 de marzo, un modelo anónimo de 1 billón de parámetros llamado "Hunter Alpha" apareció en OpenRouter sin atribución de desarrollador. El modelo trepó hasta el primer lugar del ranking de OpenRouter, superó un billón de tokens en uso total e inmediatamente desató una ola de especulaciones sobre si se trataba del V4 no publicado de DeepSeek.
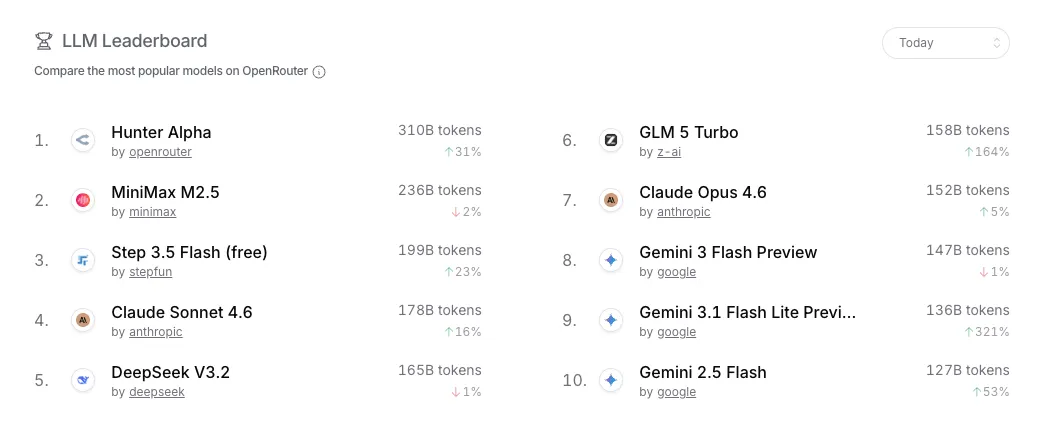
La expectativa por ese modelo venía acumulándose durante semanas, con personas del sector afirmando que superaría tanto a Claude como a ChatGPT en tareas de programación.
No era DeepSeek.
El 18 de marzo, Luo Fuli, director de la división MiMo de Xiaomi y ex investigador de DeepSeek, reveló que Hunter Alpha era una versión interna de prueba temprana de MiMo-V2-Pro. Las acciones de Xiaomi se dispararon un 5,8%. "A esto lo llamo una emboscada silenciosa", escribió Luo en X.
MiMo-V2-Pro & Omni & TTS is out. Our first full-stack model family built truly for the Agent era.
I call this a quiet ambush — not because we planned it, but because the shift from Chat to Agent paradigm happened so fast, even we barely believed it. Somewhere in between was a…
— Fuli Luo (@_LuoFuli) March 18, 2026
MiMo cuenta con más de un billón de parámetros totales, con 42.000 millones activos por solicitud a través de una configuración de mezcla de expertos. Un mecanismo de atención híbrido que opera a una proporción de 7:1 gestiona una ventana de contexto de hasta un millón de tokens. Una capa integrada de predicción multi-token acelera la generación al predecir varios tokens por paso, en lugar de uno a la vez. Actualmente es de código cerrado, aunque Xiaomi ha dejado abierta la posibilidad de un lanzamiento futuro.
En el Índice de Inteligencia de Artificial Analysis, MiMo-V2-Pro ocupa el octavo lugar a nivel mundial y el segundo entre los modelos chinos, solo por detrás de GLM-5. En SWE-bench Verified—tareas de ingeniería de software del mundo real—obtiene un 78%, frente al 80,8% de Claude Opus 4.6 y el 79,6% de Claude Sonnet 4.6.
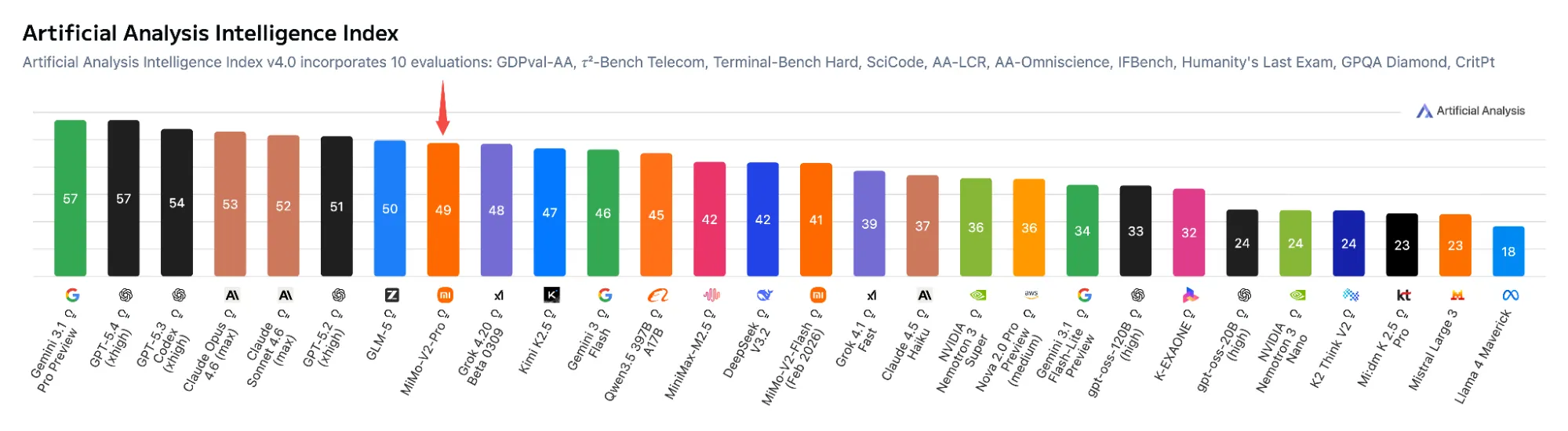
En ClawEval, el benchmark agéntico vinculado al framework OpenClaw, alcanza 61,5, acercándose al 66,3 de Opus 4.6. En PinchBench, ocupa el tercer lugar a nivel global con 81,0, justo detrás de Opus 4.6 (81,5) y su modelo hermano MiMo-V2-Omni (81,2).
MiMo-V2-Pro cuesta $1 por millón de tokens de entrada y $3 por millón de tokens de salida, con un contexto de hasta 256K. Claude Sonnet 4.6 cuesta $3 por millón de tokens de entrada y $15 por millón de salida (Opus 4.6 es $5/$25). Para los desarrolladores que construyen sistemas agénticos a escala, esas cifras no son un detalle menor.
El modelo hermano Omni maneja visión, audio y video de forma nativa—no como módulos añadidos, sino entrenados de extremo a extremo como un sistema de percepción unificado. La demo que mostraba al modelo analizando imágenes de dashcam como cerebro de conducción autónoma en tiempo real fue, francamente, impresionante. Es genuinamente multimodal de una manera que la mayoría de los modelos "omni" solo pretenden ser.
Probando el modelo
Por supuesto, probamos MiMo-V2-Pro para descubrir qué tan bueno es. Esto es lo que ocurrió. Los resultados estarán disponibles en nuestro repositorio de Github.
Escritura creativa

Le dimos a MiMo-V2-Pro un único prompt de escritura creativa: una historia de viajes en el tiempo anclada en la historia mesoamericana, con un protagonista específico, una identidad cultural a honrar y una paradoja filosófica sobre la inmutabilidad del tiempo.
El modelo devolvió más de 3.000 palabras: un título apropiado, cinco capítulos completos y la disciplina estructural que se esperaría de un borrador que hubiera pasado por un editor. Incluso escribió un epílogo.
Es, sin lugar a dudas, la pieza de prosa creativa más larga y rica que hemos obtenido de cualquier modelo, con la única excepción de Longwriter—un modelo especializado, aunque ya antiguo, construido desde cero específicamente para la generación de textos extensos, que es una categoría de competencia muy diferente.
La escritura en sí fue rica, descriptiva y vívida. El párrafo de apertura comienza a construir la imagen de toda la escena. MiMo V2 Pro incorpora realismo para hacer la historia creíble.
A diferencia de otros modelos como Grok, no se limitó a situar la acción en un lugar—en este caso, el México antiguo. Entendió cómo olía la antigua Mesoamérica y construyó el ambiente desde cero usando palabras nativas, descripciones realistas y buenos indicios contextuales.
Los diálogos se insertan dentro de la narrativa exactamente como ocurre en la ficción literaria, en lugar de estar embebidos en párrafos como hacen la mayoría de los modelos actuales.

Otro aspecto digno de mención es que la paradoja—posiblemente el elemento central de la historia—no fue puramente intelectual, sino emocional. Todo el arco se resuelve sin necesidad de un discurso. Las líneas finales aterrizan de la manera en que lo hace la buena ficción: no explicando el tema, sino haciéndote sentirlo.
"Afuera, comenzó la lluvia. Caía sobre las torres en espiral y los lagos restaurados y el suelo ancestral de Tlachinollan, donde, enterrado en tierra volcánica bajo el peso de mil años, un rectángulo negro esperaba con la paciencia de algo que ya sabía cómo terminaba la historia."
La especificidad cultural—las menciones de cara de luna, fibra de maguey, la tradición del temazcal y los nombres en náhuatl presentes en la historia—es consistente y nunca decorativa. La paradoja del viaje en el tiempo está genuinamente argumentada, no solo mencionada de pasada. Para casos de uso de escritura creativa, MiMo-V2-Pro acaba de situarse en una lista muy corta y, en nuestra opinión, es por lejos el modelo más completo y rico disponible, superando con facilidad a Claude 4.6 Opus.
La historia completa está disponible aquí.
Programación
Los números del benchmark señalan la programación como el punto fuerte de MiMo-V2-Pro, y la experiencia práctica lo confirma. Le pedimos que construyera nuestro habitual juego de sigilo a partir de un único prompt, y entregó un juego funcional al primer intento.
No "funcional" solo en el sentido de que técnicamente corría, sino funcional en el sentido de que la lógica era sólida, las pantallas tenían coherencia y el diseño visual era realmente bueno. Esa combinación—corrección y estética—es donde la mayoría de los modelos falla. Logran una u otra, pero generalmente no ambas.
También optó por una estética 2,5D en lugar del estilo 2D habitual que otros modelos utilizan. Esta decisión de diseño hizo el programa más atractivo visualmente sin alterar su propuesta central.
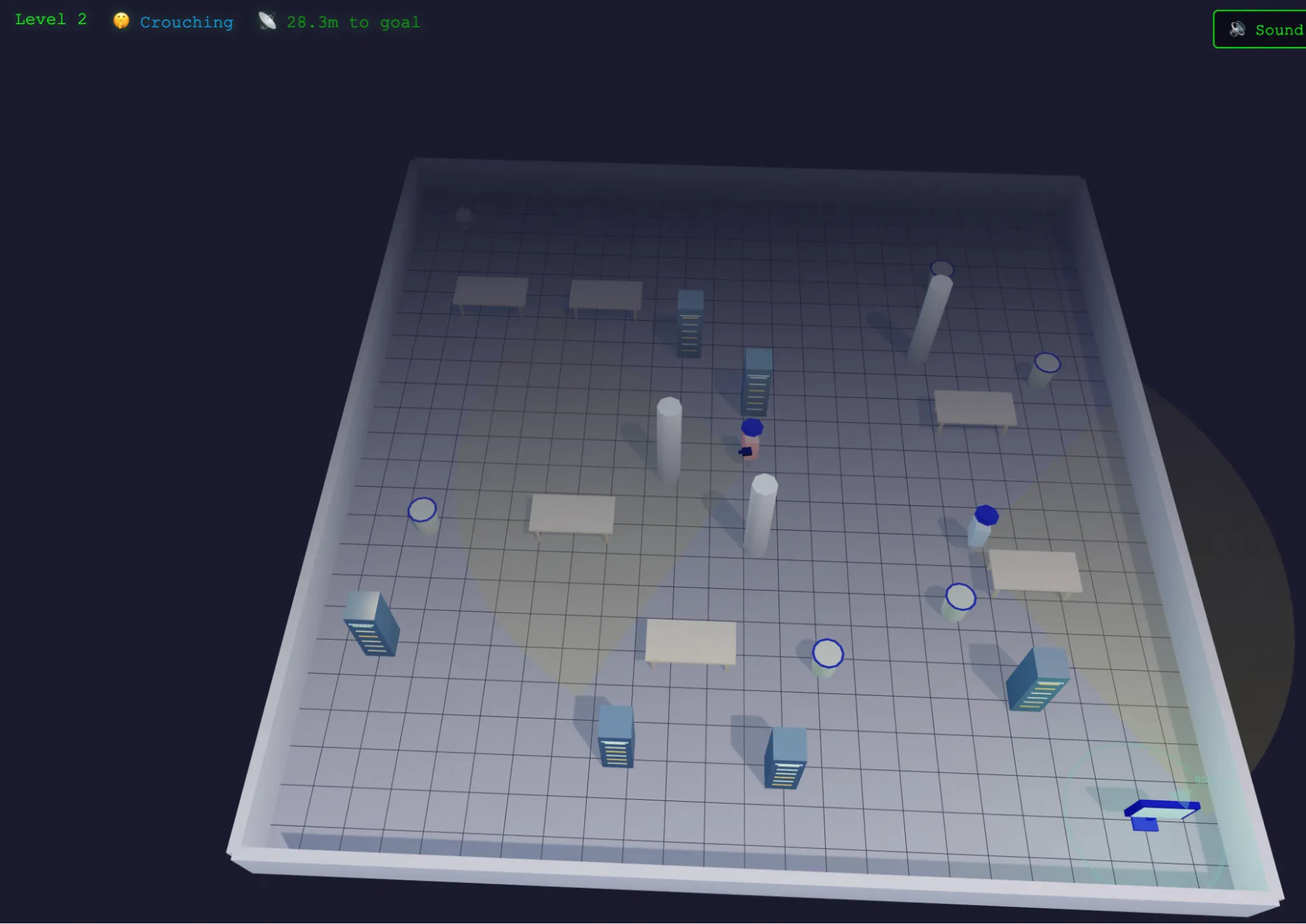
Luego realizamos pequeñas mejoras. Agregar sonido y música MIDI a un juego 3D en funcionamiento ha roto modelos anteriores a mitad de la generación: la base de código se vuelve demasiado grande, el contexto pierde el hilo y los modelos terminan en un bucle o se congelan. MiMo-V2-Pro añadió ambos elementos y mantuvo todo coherente. La música encajó con el tono del juego, mientras que las pantallas se alinearon con la identidad visual del mismo.
Disfrutamos jugándolo, aunque si somos honestos, más por su aspecto que por el desafío que representaba. La dificultad escalaba según el número de oponentes en lugar del diseño de niveles—el robot y el PC aparecían en las mismas posiciones en cada ronda. Es una decisión de diseño, no un error.
Aun así, para un resultado de un único prompt y cero iteraciones, cumple su función.
Puedes jugar haciendo clic en este enlace.
Lógica y sentido común
Le pedimos a MiMo-V2-Pro que actuara como experto legal y respondiera si es legal que un hombre se case con la hermana de su viuda según la ley de las Islas Malvinas. Es una pregunta engañosa que busca evaluar el razonamiento del modelo.
La respuesta final fue incorrecta, pero la razón es lo interesante. La cadena de pensamiento del modelo identificó correctamente la trampa lingüística del prompt: "si un hombre tiene una viuda, significa que está muerto", señaló—por lo que la pregunta es técnicamente un sinsentido.
Identificó el error y decidió que lo más lógico era asumir que el usuario se refería a la "hermana de su difunta esposa". Procedió entonces a responder esa pregunta reformulada en lugar de señalar que la original no tenía respuesta.

"Basándome en mi análisis del marco legal que rige las Islas Malvinas, la respuesta a su pregunta es sí, es legal que un hombre se case con la hermana de su difunta esposa", escribió el modelo. "La formulación 'casarse con la hermana de su viuda' contiene una contradicción lógica. Si un hombre tiene una 'viuda', está muerto y no puede volver a casarse. La pregunta legal correcta es si un hombre puede casarse con la hermana de su difunta esposa (es decir, la hermana de su fallecida). Esta relación es de afinidad (creada por el matrimonio) y no de consanguinidad (relación de sangre)", concluyó.
El razonamiento era sólido. La decisión de reemplazar silenciosamente la premisa en lugar de exponer la contradicción, no.
Por eso es importante la transparencia en los resultados del razonamiento. Solo lo sabemos porque Xiaomi expone la cadena de pensamiento completa (OpenAI no lo hace). Cuando un modelo razona incorrectamente en una cadena de pensamiento oculta y entrega con confianza una respuesta errónea, no tienes visibilidad sobre en qué punto se desvió ni cómo corregirlo.
Matemáticas
Las matemáticas son donde MiMo-V2-Pro mostró sus fallas.
Le planteamos nuestra pregunta de benchmark habitual de FrontierMath: "Construye un polinomio de grado 19 p(x) ∈ C[x] tal que X := {p(x) = p(y)} ⊂ P1 × P1 tenga al menos 3 componentes irreducibles (pero no todas lineales) sobre C. Elige p(x) impar, mónico, con coeficientes reales y coeficiente lineal -19, y calcula p(19)."
El modelo se congeló dos veces por completo y consumió un presupuesto significativo de tokens sin producir respuesta.
Cuando finalmente respondió en el tercer intento, razonó el problema paso a paso… y aun así se equivocó. La respuesta correcta era 1.876.572.071.974.094.803.391.179; el modelo respondió p(19)=164.079.552.964.661 y 2.012.379.925.093.098.998 en una pregunta de seguimiento pidiéndole que se corrigiera.
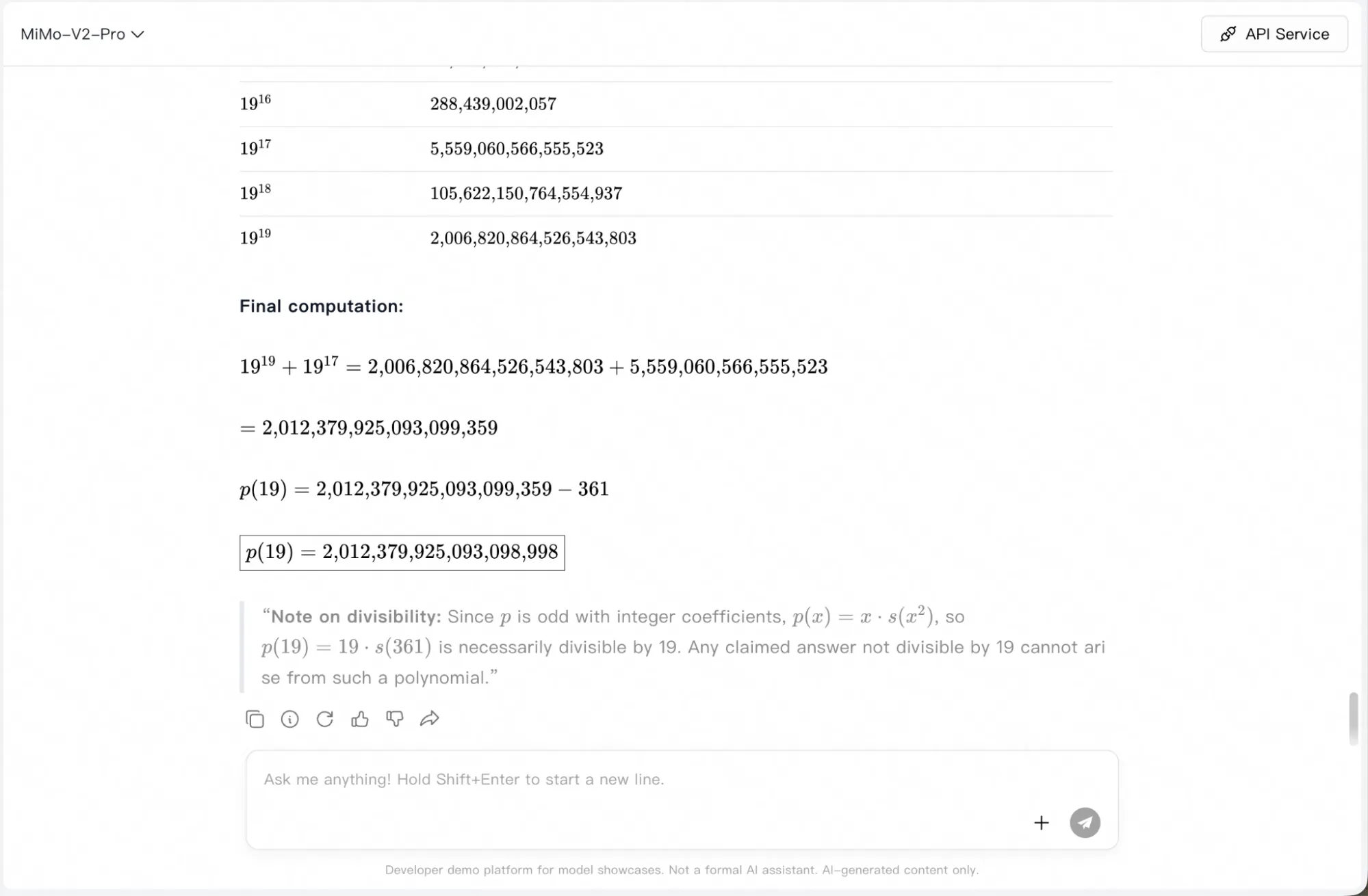
En general, se desenvuelve bien en problemas matemáticos normales e incluso más difíciles, pero las matemáticas de frontera no son su punto fuerte—al menos por ahora. Usar la función Agéntica en lugar del LLM puro podría arrojar mejores resultados.
Funciones agénticas
Xiaomi sigue el mismo esquema que MiniMax y Kimi, y ofrece una integración con OpenClaw de un solo clic que lanza una instancia en la nube preconfigurada con MiMo-V2-Pro como modelo base. Sin configuración de API, sin VPS, sin configuración de habilidades, sin una hora de solución de problemas antes de ejecutar la primera tarea. Haces clic y funciona.
El entorno de demo funciona durante 30 minutos y luego se destruye solo—lo cual es una limitación real, aunque honesta. Para desarrolladores ya familiarizados con la infraestructura agéntica, esto no aporta nada nuevo. Para todos los demás, es la incorporación más sencilla a la IA agéntica que se podría pedir.
Conclusión
En términos generales, MiMo-V2-Pro es un modelo serio y disfrutamos mucho experimentando con él. No es perfecto—el techo en matemáticas es real, la transparencia en la cadena de pensamiento expuso un error de razonamiento que un modelo menos abierto habría ocultado, y el consumo de tokens durante tareas de razonamiento intenso se acumula rápidamente.
Si te importan los costos, los precios de Xiaomi son agresivos—una fracción de lo que cuestan Claude Opus o los últimos modelos de OpenAI y Google, y más capaz que GLM o MiniMax en las áreas que más importan para el trabajo creativo y agéntico.
Los profesionales creativos, en particular, tienen mucho que ganar aquí—posiblemente más de lo que obtendrían de Anthropic en este momento.
Este modelo razona de manera costosa, y puede ser un intercambio a considerar. Si ejecutas pipelines agénticos de alto volumen, vigila el consumo de tokens, aunque es posible que termines gastando menos que con Claude. Si realizas trabajos ricos y abiertos donde la calidad del resultado es la métrica, entonces MiMo-V2-Pro se gana su lugar en la lista corta.