

OpenAI has released a new web crawling bot, GPTBot, to expand its dataset for training its next generation of AI systems—and the next iteration apparently has an official name. The company trademarked the term "GPT-5," hinting at an upcoming release, while giving web publishers a heads up on how to keep their content out of its massive corpus.
The web crawler will collect publicly available data from websites, while avoiding paywalled, sensitive, and prohibited content, according to OpenAI. Similar to other search engines like Google, Bing, and Yandex, however, the system is opt out—by default, GPTBot will assume accessible information is fair game. In order to prevent the OpenAI web crawler from ingesting a website, its owner must add a "disallow" rule to a standard file on the server.
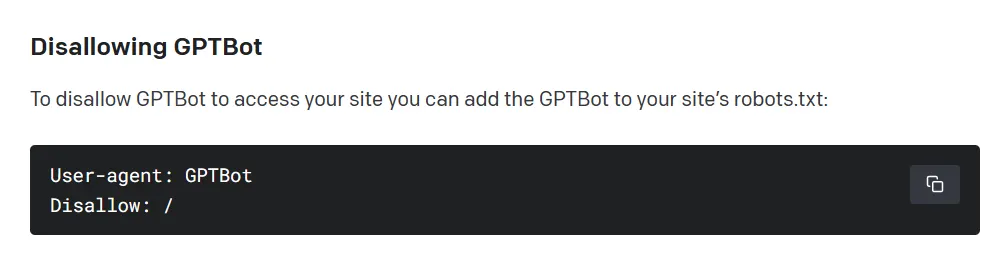
OpenAI also says that GPTBot will preemptively scan scraped data to remove personally identifiable information (PII) and text that violates its policies.
According to some technology ethicists, however, the opt-out approach still raises consent issues.
On Hacker News, some users justified OpenAI's move by saying that it must gather up everything it can if people want to have a capable generative AI tool in the future. “They still need current data or their GPT models will be stuck at september 2021 forever,” one user said. Another more privacy-conscious user argued that "OpenAI isn't even citing in moderation. It's making a derivative work without citing, thus obscuring it."
The release of GPTBot follows recent criticism of OpenAI previously scraping data without permission to train Large Language Models (LLMs) like ChatGPT. To address such concerns, the company updated its privacy policies in April.
Meanwhile, a recent trademark application for GPT-5 seems to confirm that OpenAI is training its next model for a future launch. The new system would very likely involve large-scale web scraping to update and expand its training data.
This could represent a shift away from OpenAI's early emphasis on transparency and AI safety, but it is not surprising considering that ChatGPT is the most used LLM in the world, despite an increasingly crowded and high-powered marketplace. OpenAI's star product—and that of any LLM—is only as good as the quality of the data used to train it.
OpenAI needs more and newer data, and it needs lots of it.
On the other hand, there is an open-source LLM, assembled by social media giant Meta. The tech behemoth has offered up its model for free, as long as you are not a competitor nor are too large a business. Meta has not disclosed which datasets it used to train its model, and which information it has collected. However, the approach makes it possible for users to fine-tune the model using their own datasets.
Whereas OpenAI relies on all of its crawled data to train its models and to build a profitable ecosystem around its AI tools, Meta is vying to build a profitable business around its data. Thus, Meta not only uses it to create better models, but also shares it with third parties so they can use it.
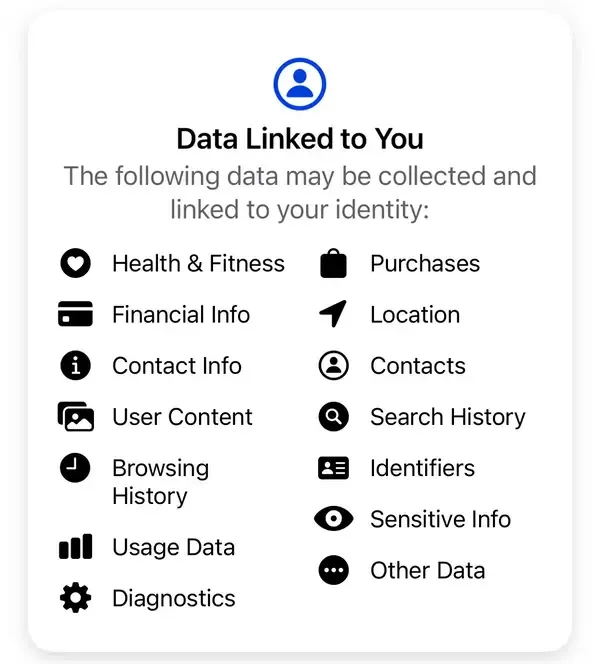
“We don't sell your information. Instead, based on the information we have, advertisers and other partners pay us to show you personalized ads,” Meta explains. According to Meta's standard privacy disclosures, some of the data the company collects includes purchases, browser history, IDs, financial info, contacts and undisclosed sensitive information among others.
ChatGPT now draws over 1.5 billion monthly active users. And Microsoft's $10 billion investment into OpenAI appears prescient, as ChatGPT integration has boosted Bing's capabilities.
For now, OpenAI leads the red-hot AI space, with tech giants racing to catch up. The company's new web crawler may further advance its models' abilities. But expanding internet data collection also raises ethical questions around copyright and consent.
As AI systems grow more sophisticated, balancing transparency, ethics and capabilities will remain a complex balancing act.