

En Resumen
- Novasky creó Sky-T1, un modelo de razonamiento IA de 32B entrenado por menos de $450, superando al o1 de OpenAI en precisión.
- El modelo puede ejecutarse localmente en GPUs como RTX 4090 y es de código abierto, accesible en Hugging Face.
- El enfoque se centró en eficiencia y accesibilidad, logrando rendimiento competitivo sin costoso hardware corporativo.
El equipo de Novasky, una “iniciativa colaborativa liderada por estudiantes y asesores del Laboratorio de Sky Computing de UC Berkeley”, ha logrado lo que parecía imposible hace solo unos meses: han creado un modelo de razonamiento de IA de alto rendimiento por menos de $450 en costos de entrenamiento.
A diferencia de los Large Language Models (LLM) tradicionales que simplemente predicen la siguiente palabra en una oración, los llamados “modelos de razonamiento” están diseñados para comprender un problema, analizar diferentes enfoques para resolverlo y ejecutar la mejor solución. Esto hace que estos modelos sean más difíciles de entrenar y configurar, ya que deben “razonar” a través de todo el proceso de resolución de problemas en lugar de simplemente predecir la mejor respuesta basada en su conjunto de datos de entrenamiento.
Por eso, una suscripción a ChatGPT Pro, que ejecuta el último modelo de razonamiento o3, cuesta $200 al mes: OpenAI argumenta que estos modelos son costosos de entrenar y ejecutar.
El nuevo modelo de Novasky, denominado Sky-T1, es comparable al primer modelo de razonamiento de OpenAI, conocido como o1 (también llamado Strawberry), que se lanzó en septiembre de 2024 y cuesta $20 al mes a los usuarios. En comparación, Sky-T1 es un modelo de 32.000 millones de parámetros capaz de ejecutarse localmente en computadoras domésticas, siempre que tengas una potente GPU de 24 GB, como una RTX 4090 o una 3090 Ti más antigua. Y es gratuito.
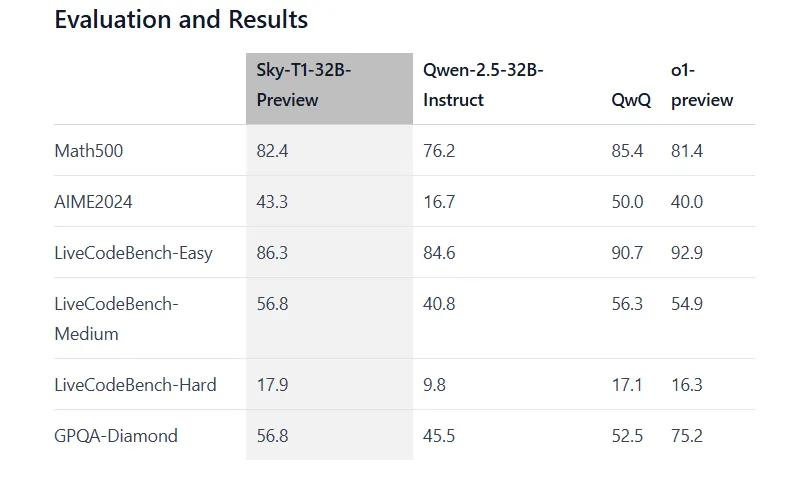
No estamos hablando de una versión diluida. Sky-T1-32B-Preview alcanza una precisión del 43,3% en problemas matemáticos AIME2024, superando el 40% obtenido por o1 de OpenAI. En LiveCodeBench-Médium, obtiene un 56,8% en comparación con el 54,9% de o1-preview. El modelo mantiene un rendimiento sólido en otros puntos de referencia también, alcanzando el 82,4% en problemas Math500 donde o1-preview obtiene 81,4%.
El momento no podría ser más interesante. La carrera del razonamiento de IA se ha estado calentando últimamente, con el o3 de OpenAI llamando la atención al superar a los humanos en pruebas de inteligencia general, generando debates sobre si estamos viendo los primeros indicios de AGI o inteligencia artificial general.
Mientras tanto, el Deepseek v3 de China causó sensación el año pasado al superar al o1 de OpenAI mientras utilizaba menos recursos y también era de código abierto.
🚀 Introducing DeepSeek-V3!
Biggest leap forward yet:
⚡ 60 tokens/second (3x faster than V2!)
💪 Enhanced capabilities
🛠 API compatibility intact
🌍 Fully open-source models & papers🐋 1/n pic.twitter.com/p1dV9gJ2Sd
— DeepSeek (@deepseek_ai) December 26, 2024
Pero el enfoque de Berkeley es diferente. En lugar de perseguir el poder bruto, el equipo se centró en hacer que un potente modelo de razonamiento fuera accesible para las masas de la manera más económica posible, construyendo un modelo que es fácil de ajustar y ejecutar en computadoras locales sin la necesidad de un costoso hardware corporativo.
“Sorprendentemente, Sky-T1-32B-Preview fue entrenado por menos de $450, demostrando que es posible replicar capacidades de razonamiento de alto nivel de manera asequible y eficiente. Todo el código es de código abierto”, dijo Novasky en su publicación oficial del blog.
Actualmente, OpenAI no ofrece acceso gratuito a sus modelos de razonamiento, aunque sí ofrece acceso gratuito a un modelo menos sofisticado.
La perspectiva de ajustar un modelo de razonamiento para la excelencia en dominios específicos por menos de $500 es especialmente atractiva para los desarrolladores, ya que tales modelos especializados pueden potencialmente superar a modelos más potentes de propósito general en dominios específicos. Esta especialización rentable abre nuevas posibilidades para aplicaciones enfocadas en campos científicos.
El equipo entrenó su modelo durante solo 19 horas usando GPUs Nvidia H100, siguiendo lo que ellos llaman una “receta” que la mayoría de los desarrolladores deberían poder replicar. Los datos de entrenamiento parecen los grandes éxitos de los desafíos de IA.
“Nuestros datos finales contienen 5.000 datos de codificación de APPs y TACO, y 10.000 datos matemáticos de AIME, MATH y subconjuntos de Olimpiadas del conjunto de datos NuminaMATH. Además, mantenemos 1.000 datos de ciencia y rompecabezas de STILL-2”, dijo Novasky.
El conjunto de datos fue lo suficientemente variado para ayudar al modelo a pensar de manera flexible a través de diferentes tipos de problemas. Novasky usó QwQ-32B-Preview, otro modelo de razonamiento de IA de código abierto, para generar los datos y ajustar un LLM de código abierto Qwen2.5-32B-Instruct. El resultado fue un nuevo modelo potente con capacidades de razonamiento, que más tarde se convertiría en Sky-T1.
Un hallazgo clave del trabajo del equipo es que más grande sigue siendo mejor cuando se trata de modelos de IA. Sus experimentos con versiones más pequeñas de 7.000 millones y 14.000 millones de parámetros mostraron solo ganancias modestas. El punto óptimo resultó ser 32.000 millones de parámetros, lo suficientemente grande para evitar salidas repetitivas, pero no tan masivo como para volverse impracticable.
Si quieres tener tu propia versión de un modelo que supere al o1 de OpenAI, puedes descargar Sky-T1 en Hugging Face. Si tu GPU no es lo suficientemente potente, pero aún quieres probarlo, hay versiones cuantizadas que van desde 8 bits hasta 2 bits, por lo que puedes intercambiar precisión por velocidad y probar la siguiente mejor opción en tu PC menos potente.
Solo ten en cuenta que los desarrolladores advierten que tales niveles de cuantización “no se recomiendan para la mayoría de los propósitos”.
Editado por Andrew Hayward