

En Resumen
- El modelo O3 alcanzó 88.5% en el benchmark ARC-AGI, superando a humanos en pruebas complejas.
- Expertos debaten si su éxito indica verdadera inteligencia artificial general.
- Los críticos señalaron su dependencia en fuerza bruta, en vez de un razonamiento genuino.
El último modelo de IA de OpenAI ha logrado lo que muchos pensaban imposible, alcanzando una puntuación sin precedentes de 87,5% en el desafiante benchmark Autonomous Research Collaborative Artificial General Intelligence—básicamente cerca del umbral mínimo de lo que teóricamente podría considerarse "humano".
El benchmark ARC-AGI prueba qué tan cerca está un modelo de alcanzar la inteligencia artificial general (AGI), es decir, si puede pensar, resolver problemas y adaptarse como un humano en diferentes situaciones... incluso cuando no ha sido entrenado para ellas. El benchmark es extremadamente fácil de superar para los humanos, pero es extremadamente difícil de entender y resolver para las máquinas.
La compañía de investigación de IA con sede en San Francisco presentó O3 y O3-mini la semana pasada como parte de su campaña "12 días de OpenAI"—y solo días después de que Google anunciara su propio competidor O1. El lanzamiento mostró que el próximo modelo de OpenAI estaba más cerca de alcanzar la inteligencia artificial general de lo esperado.
El nuevo modelo centrado en el razonamiento de OpenAI marca un cambio fundamental en cómo los sistemas de IA abordan el razonamiento complejo. A diferencia de los Large Language Models o LLMs tradicionales que dependen de la coincidencia de patrones, O3 introduce un novedoso enfoque de "síntesis de programas" que le permite abordar problemas completamente nuevos que no ha encontrado antes.
"Esto no es simplemente una mejora incremental, sino un verdadero avance", declaró el equipo de ARC en su informe de evaluación. En una publicación de blog, el cofundador del Premio ARC, Francois Chollet, fue aún más allá, sugiriendo que "O3 es un sistema capaz de adaptarse a tareas que nunca ha encontrado antes, acercándose posiblemente al rendimiento a nivel humano en el dominio ARC-AGI".
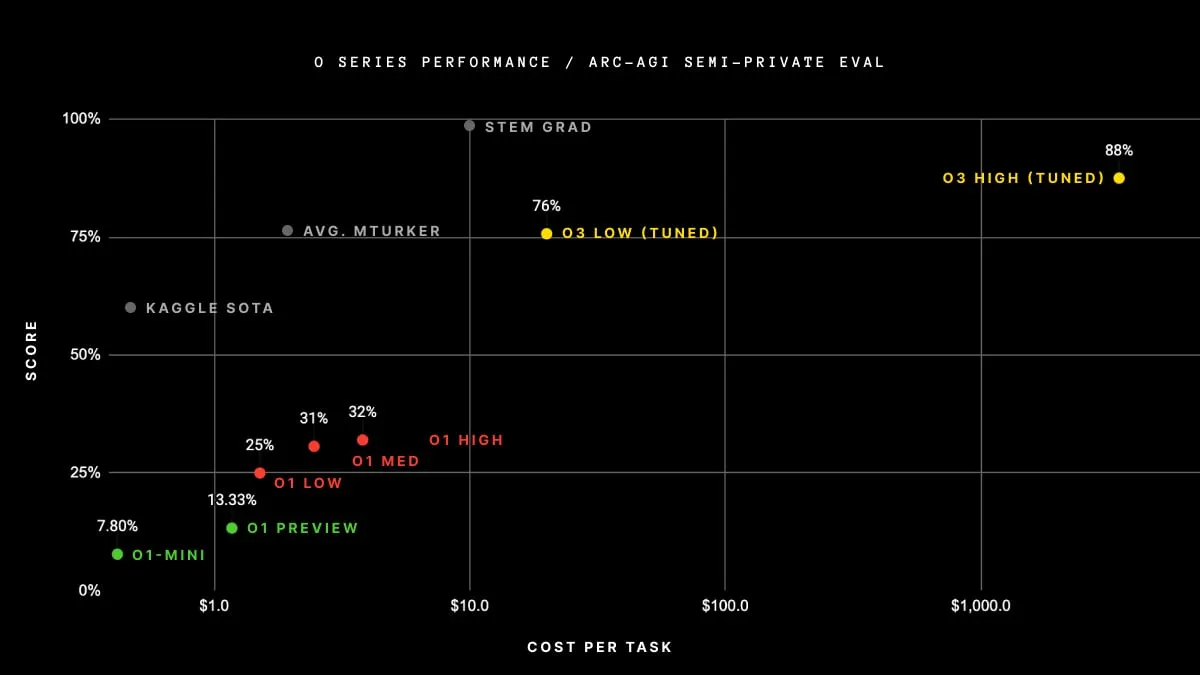
Como referencia, esto es lo que dice ARC Prize sobre sus puntuaciones: "El rendimiento humano promedio en el estudio estuvo entre 73,3% y 77,2% correcto (promedio del conjunto de entrenamiento público: 76,2%; promedio del conjunto de evaluación público: 64,2%)."
OpenAI O3 logró una puntuación de 88,5% usando equipos de computación de alto rendimiento. Esa puntuación estaba muy por delante de cualquier otro modelo de IA actualmente disponible.
¿Se puede considerar a o3 como AGI? Todo depende de a quién preguntes
A pesar de sus impresionantes resultados, la junta del Premio ARC—y otros expertos—dijeron que aún no se ha alcanzado la AGI, por lo que el premio de $1 millón permanece sin reclamar. Pero los expertos en toda la industria de la IA no fueron unánimes en sus opiniones sobre si O3 había superado el benchmark de AGI.
Algunos—incluyendo al propio Chollet—cuestionaron si la prueba de benchmarking en sí era incluso el mejor indicador de si un modelo se estaba acercando a la resolución de problemas real a nivel humano: "Pasar ARC-AGI no equivale a lograr AGI, y de hecho, no creo que O3 sea AGI todavía", dijo Chollet. "O3 todavía falla en algunas tareas muy fáciles, indicando diferencias fundamentales con la inteligencia humana".
Hizo referencia a una versión más nueva del benchmark AGI, que según él proporcionaría una medida más precisa de qué tan cerca está una IA de poder razonar como un humano. Chollet señaló que "los primeros datos sugieren que el próximo benchmark ARC-AGI-2 seguirá representando un desafío significativo para O3, potencialmente reduciendo su puntuación a menos del 30% incluso con alta capacidad de cómputo (mientras que un humano inteligente aún podría obtener más del 95% sin entrenamiento)".
Otros escépticos incluso afirmaron que OpenAI efectivamente manipuló la prueba. "Modelos como O3 usan trucos de planificación. Esbozan pasos ('scratchpads') para mejorar la precisión, pero siguen siendo predictores de texto avanzados. Por ejemplo, cuando O3 'cuenta letras', está generando texto sobre contar, no razonando verdaderamente", escribió el cofundador de Zeroqode Levon Terteryan en X.
Why OpenAI’s o3 Isn’t AGI
OpenAI’s new reasoning model, o3, is impressive on benchmarks but still far from AGI.
What is AGI?
AGI (Artificial General Intelligence) refers to a system capable of human-level understanding across tasks. It should:
- Play chess like a human.… pic.twitter.com/yn4cuDTFte— Levon Terteryan (@levon377) December 21, 2024
Un punto de vista similar es compartido por otros científicos de IA, como la galardonada investigadora de IA Melanie Mitchel, quien argumentó que O3 no está realmente razonando sino realizando una "búsqueda heurística".
Chollet y otros señalaron que OpenAI no fue transparente sobre cómo operan sus modelos. Los modelos parecen estar entrenados en diferentes procesos de Chain of Thought "de una manera quizás no muy diferente al AlphaZero-style Monte-Carlo tree search", dijo Mitchell. En otras palabras, no sabe cómo resolver un nuevo problema, y en su lugar aplica el Chain of Thought más probable posible en su vasto corpus de conocimiento hasta que encuentra exitosamente una solución.
En otras palabras, O3 no es verdaderamente creativo—simplemente confía en una vasta biblioteca para llegar a una solución mediante prueba y error.
"Fuerza bruta (no es igual a) inteligencia. O3 dependió de una potencia de cómputo extrema para alcanzar su puntuación no oficial", argumentó Jeff Joyce, presentador del podcast Humanity Unchained AI, en LinkedIn. "La verdadera AGI necesitaría resolver problemas eficientemente. Incluso con recursos ilimitados, O3 no pudo resolver más de 100 acertijos que los humanos encuentran fáciles".
El investigador de OpenAI Vahidi Kazemi está en el campo de "Esto es AGI". "En mi opinión ya hemos logrado ña AGI", dijo, señalando al modelo O1 anterior, que según él argumentó fue el primero diseñado para razonar en lugar de solo predecir el siguiente token.
Estableció un paralelo con la metodología científica, sosteniendo que dado que la ciencia misma se basa en pasos sistemáticos y repetibles para validar hipótesis, es inconsistente descartar modelos de IA como no-AGI simplemente porque siguen un conjunto de instrucciones predeterminadas. Dicho esto, OpenAI "no ha logrado ser 'mejor que cualquier humano en cualquier tarea'", escribió.
In my opinion we have already achieved AGI and it’s even more clear with O1. We have not achieved “better than any human at any task” but what we have is “better than most humans at most tasks”. Some say LLMs only know how to follow a recipe. Firstly, no one can really explain…
— Vahid Kazemi (@VahidK) December 6, 2024
Por su parte, el CEO de OpenAI Sam Altman no está tomando una posición sobre si se ha alcanzado la AGI. Simplemente, dijo que "O3 es un modelo muy muy inteligente", y "O3 mini es un modelo increíblemente inteligente pero con muy buen rendimiento y costo".
Ser inteligente puede no ser suficiente para afirmar que se ha logrado la AGI—al menos todavía. Pero estén atentos: "Vemos esto como el comienzo de la siguiente fase de la IA", agregó.
Editado por Andrew Hayward