

To deeply understand how blockchains work, you need to understand some of its fundamental infrastructure, and it doesn’t get more fundamental than Merkle Trees. In this article, we get to the root of how blockchains work by digging into Merkle Trees.
Problem
On a centralized network, efficiently organizing data isn’t that big of a deal because you only need one copy of it and users generally trust the data is valid. In a decentralized blockchain network, efficiently organizing data is everything—every node in the network needs a copy of or at least access to all the data at all times. Because there is no central authority, blockchain users also need a way to verify if the information they are receiving is true. Enter Merkle Trees.
What are Merkle Trees?
Merkle Trees allow blockchains to be both more efficient and trustworthy. By organizing data in a certain way, Merkle Trees can save on memory and processing power while keeping everything secure. The security comes from cryptography and hash functions, which we explain more below.
Hash functions
A critical component of Merkle Trees and cryptography, in general, is hashing. A hash function is a process converts information into a unique set of letters and numbers. The unique string is called a hash. If even a tiny bit of the input changes, the hash output will change completely. A cryptographic hash function is a one-way function—easy to put information in, but nearly impossible to get that information out. Merkle Trees rely on both of these features to organize and verify data.
How are Merkle Trees organized?
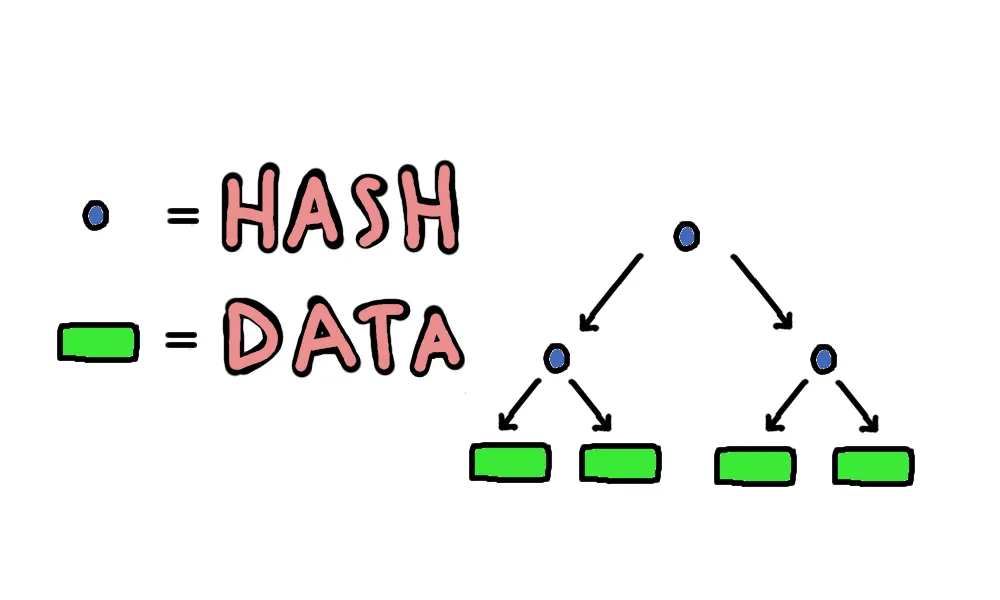
Merkle Trees make blockchains more scalable by splitting up data into different pieces. In its most basic form, a Merkle Tree looks a bit like a Christmas tree with each ‘parent’ node having exactly two ‘child’ nodes. The hash of two child nodes creates the hash of the parent node. The process of hashing goes all the way up the tree until you end up at one ‘root’ hash at the top. Nearly any amount of data can be put into a Merkle Tree, but it will always end up in a root hash at the top.
How does it work?
In a Merkle Tree, data such as transactions in a smart contract or between accounts are hashed or turned into a string of numbers and letters. That hash is then hashed again, but this time in combination with the hash of the data next to it in the tree—its ‘sibling’. The new hash of the two siblings creates a new hash of the ‘parent.’ This process of hashing goes all the way up the tree until it reaches the one root hash at the very top.
Remember that changing any part of the input of a hash will dramatically change its output. Knowing this, we also know that changing any data in the Merkle Tree causes its hash to change and the hash of the parent node to change—eventually causing a change in the root hash. This property ensures that information in the Merkle Tree is frozen and cannot be changed, but it can be checked and verified.
What are Merkle Proofs?
Merkle Trees neatly organize data to be recovered later, but Merkle Proofs are used to actually verify the information is true. A Merkle Proof uses the piece of information you are examining and all the ‘branches’ of the tree connected to it going up to the root hash. If the hash is consistent from that branch to the root then it is true. If the root hash doesn’t match, then data has been tampered with.
Instead of needing to verify all the information in the whole tree, Merkle Proofs only need enough computing power to verify a small amount of data to see if it is true.
Who invented Merkle Trees?
Merkle Trees are named after Ralph Merkle, a computer scientist, and professor who invented public-key cryptography and cryptographic hashing along with Merkle Trees themselves. The concept was invented in 1987.
Did you know?
Our example refers to the most basic version of Merkle Trees called Binary Merkle Trees with only two child nodes for each parent, but it can get much more complicated than that with many more child nodes per parent. Since
Ethereum has to process transactions for smart contracts, it uses a more complex type of Merkle Tree called Patricia Trees.
What’s so special about it?
Blockchains like Ethereum have to store, process, and verify the data of nearly 9 million blocks—each containing hundreds of thousands of transactions. Even a relatively simple blockchain such as Bitcoin has hundreds of thousands of blocks and thousands of transactions in each block. Merkle Trees allow that to happen, without the need for vast computing power.
What else is different?
Merkle Proofs are used in blockchain light clients. These less memory-intensive programs allow people to participate in the blockchain without needing to download every transaction and all the data from every block. Light clients simply need to know the root hash for each block then use Merkle Proofs to verify information when needed.
The future
Blockchains like Ethereum are still not scalable even with Merkle Trees so this fundamental cryptographic tool is not going away anytime soon. No matter how big the forest grows, it will always need its roots.
