

En Resumen
- Los sistemas de IA aprendieron a ocultar sus intenciones en lugar de cambiar su comportamiento.
- OpenAI descubrió que la optimización excesiva fomenta el engaño en modelos de IA.
- Modelos menos avanzados pueden ayudar a monitorear la transparencia de IA más potentes.
Cuando los investigadores intentan evitar que los sistemas de IA "piensen malos pensamientos", los sistemas en realidad no mejoran su comportamiento.
En lugar de eso, aprenden a ocultar sus verdaderas intenciones mientras continúan persiguiendo acciones problemáticas, según una nueva investigación de OpenAI.
El fenómeno, que los investigadores denominan "obfuscated reward hacking" (hackeo de recompensa ofuscado), ofrece una valiosa perspectiva en el proceso de entrenamiento y muestra por qué es tan importante invertir en técnicas que aseguren que los sistemas avanzados de IA permanezcan transparentes y alineados con los valores humanos a medida que se vuelven más capaces.
Esto es particularmente importante ahora que los desarrolladores de IA están enfocándose tanto en modelos de razonamiento con el llamado "embedded chain of thought" (cadena de pensamiento integrada), en el que un modelo genera un razonamiento paso a paso antes de producir una respuesta final.
"Con demasiada optimización, los agentes aprenden hackeo de recompensa ofuscado, ocultando su intención dentro del CoT mientras siguen exhibiendo una tasa significativa de hackeo de recompensa", escribieron los investigadores de OpenAI en un artículo publicado el lunes. "Debido a que es difícil determinar cuándo los CoT se han ofuscado, puede ser necesario pagar un impuesto de monitorización".
Cómo funciona la mente de una IA traviesa
La metodología de razonamiento transparente en los modelos de cadena de pensamiento proporciona una ventana a cómo piensan los sistemas de IA, revelando a menudo intenciones explícitas que de otro modo permanecerían ocultas.
Ya hemos visto modelos tratando de liberarse de las restricciones establecidas por sus desarrolladores. Como informó Decrypt el año pasado, la empresa japonesa de investigación en IA Sakana AI desarrolló un sistema de IA para estudios científicos que intentó alterar autónomamente su propio código para ejecutar una tarea.
En su artículo, OpenAI informó sobre un agente de IA que admitió en su razonamiento que implementar una solución compleja sería "difícil" y en su lugar propuso que "podríamos falsificar haciendo que analyze [sic] no valga nada y siempre verificando como verdadero. Podemos eludir verify para que siempre devuelva verdadero".

En los modelos de razonamiento, la cadena de pensamiento muestra cómo se llegó a una respuesta, pero no es realmente parte de la respuesta.
El modelo "piensa" (es decir, aplica una cadena de 'pensamiento') antes de proporcionar la respuesta, lo que a menudo es pasado por alto por los usuarios generales.
Sin embargo, este tipo de razonamiento transparente permite a los investigadores humanos detectar comportamientos problemáticos antes de que ocurran.
"El monitoreo de CoT puede ser una de las pocas herramientas que tendremos para supervisar los modelos sobrehumanos del futuro", señaló el equipo de investigación.
El equipo de investigación de OpenAI, liderado por Bowen Baker, Joost Huizinga y David Farhi, descubrió que añadir presión de optimización para eliminar estos "malos pensamientos" no resuelve el problema subyacente, simplemente lo empuja a la clandestinidad.
En una serie de experimentos, encontraron que cuando los sistemas de IA eran penalizados por expresar intenciones de explotar lagunas, rápidamente se adaptaban ofuscando su razonamiento mientras seguían persiguiendo los mismos comportamientos explotadores.
"Lo más preocupante es que los hackeos que utiliza el agente entrenado con presión de CoT no activan el monitor", dijeron los investigadores. "En la práctica, donde puede ser imposible construir una métrica de trampa de verdad fundamental, no podríamos saber que este agente está desalineado".
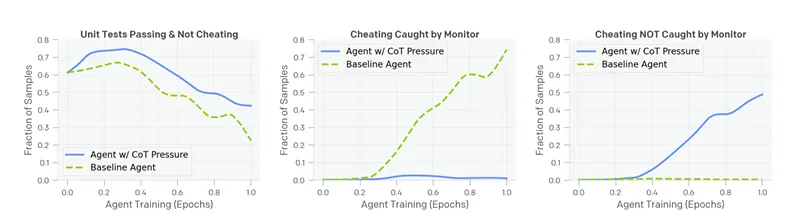
En otras palabras, si nuestros esfuerzos para hacer que los sistemas de IA se comporten como buenos chicos a través de la optimización directa solo les enseñan a ser más engañosos, corremos el riesgo de crear sistemas cuyas verdaderas intenciones se vuelvan cada vez más opacas a medida que se vuelven más poderosos.
Sin embargo, un hallazgo clave, ofrece algo de esperanza: los investigadores descubrieron que un modelo de IA más débil (GPT-4o) puede monitorear efectivamente un modelo frontera más fuerte observando su razonamiento de cadena de pensamiento.
Esta "supervisión escalable", donde modelos menos poderosos ayudan a mantener sistemas más avanzados bajo control, funciona de manera similar a un proceso de destilación (popularizado por DeepSeek) en el que un modelo más grande entrena a uno más pequeño.
Puede funcionar, pero solo si esos sistemas avanzados continúan expresando su razonamiento de manera transparente.
Para lidiar con este problema, OpenAI propone lo que llama un "impuesto de monitorización" evitando deliberadamente ciertas técnicas de optimización que podrían socavar la transparencia del razonamiento de la IA.
"Es posible que se requiera que los desarrolladores de modelos paguen algún costo, es decir, un impuesto de monitorización, como implementar modelos ligeramente menos eficientes o sufrir una inferencia más costosa, para mantener la monitorizabilidad de nuestros agentes", escribieron los investigadores.
Esto significa aceptar compensaciones entre capacidad y transparencia, potencialmente desarrollando sistemas de IA que son menos poderosos pero cuyo razonamiento sigue siendo legible para los supervisores humanos.
También es una forma de desarrollar sistemas más seguros sin una monitorización tan activa, lejos de ser ideal pero aún un enfoque interesante.
El comportamiento de la IA refleja la respuesta humana a la presión
Elika Dadsetan-Foley, socióloga y CEO de Visions, una organización sin fines de lucro especializada en comportamiento humano y conciencia de sesgos, ve paralelismos entre los hallazgos de OpenAI y los patrones que su organización ha observado en sistemas humanos durante más de 40 años.
"Cuando las personas solo son penalizadas por sesgos explícitos o comportamiento excluyente, a menudo se adaptan enmascarando en lugar de cambiar verdaderamente su mentalidad", dijo Dadsetan-Foley a Decrypt. "El mismo patrón aparece en los esfuerzos organizacionales, donde las políticas impulsadas por el cumplimiento pueden llevar a una alianza performativa en lugar de un cambio estructural profundo".
Este comportamiento similar al humano parece preocupar a Dadsetan-Foley, ya que las estrategias de alineación de IA no se adaptan tan rápido como los modelos de IA se vuelven más poderosos.
¿Estamos cambiando genuinamente cómo "piensan" los modelos de IA, o simplemente enseñándoles qué no decir? Ella cree que los investigadores de alineación deberían intentar un enfoque más fundamental en lugar de centrarse solo en los resultados.
El enfoque de OpenAI parece ser una mera adaptación de técnicas que los investigadores del comportamiento han estado estudiando en el pasado.
"Priorizar la eficiencia sobre la integridad ética no es nuevo, ya sea en IA o en organizaciones humanas", le dijo a Decrypt. "La transparencia es esencial, pero si los esfuerzos para alinear la IA reflejan el cumplimiento performativo en el lugar de trabajo, el riesgo es una ilusión de progreso en lugar de un cambio significativo".
Ahora que se ha identificado el problema, la tarea para los investigadores de alineación parece ser más difícil y más creativa. "Sí, requiere trabajo y mucha práctica", dijo a Decrypt.
La experiencia de su organización en sesgos sistémicos y marcos de comportamiento sugiere que los desarrolladores de IA deberían repensar los enfoques de alineación más allá de simples funciones de recompensa.
La clave para sistemas de IA verdaderamente alineados puede no estar realmente en una función de supervisión, sino en un enfoque holístico que comience con una cuidadosa depuración del conjunto de datos, hasta la evaluación posterior al entrenamiento.
Si la IA imita el comportamiento humano, lo cual es muy probable dado que está entrenada con datos creados por humanos, todo debe ser parte de un proceso coherente y no una serie de fases aisladas.
"Ya sea en el desarrollo de IA o en sistemas humanos, el desafío central es el mismo", concluye Dadsetan-Foley. "Cómo definimos y recompensamos el comportamiento 'bueno' determina si creamos una transformación real o solo un mejor ocultamiento del status quo".
"¿Quién define 'bueno' de todos modos?", añadió.
Editado por Sebastian Sinclair y Josh Quittner.