Add Decrypt as your preferred source to see more of our stories on Google.
En Resumen
DeepSeek R1 superó a modelos propietarios como OpenAI o1 en benchmarks de razonamiento y codificación.
Su costo es 98% menor que OpenAI, siendo gratuito y de código abierto bajo licencia MIT.
Aprendió capacidades avanzadas como autoverificación mediante reinforcement learning, sin intervención humana significativa.
Los investigadores chinos de IA han logrado lo que muchos pensaban que estaba a años luz de distancia: un modelo de IA gratuito y de código abierto que puede igualar o superar el rendimiento de los sistemas de razonamiento más avanzados de OpenAI. Lo que hace esto aún más notable fue cómo lo hicieron: dejando que la IA se enseñe a sí misma mediante prueba y error, similar a cómo aprenden los humanos.
"DeepSeek-R1-Zero, un modelo entrenado mediante reinforcement learning (RL) a gran escala sin supervised fine-tuning (SFT) como paso preliminar, demuestra notables capacidades de razonamiento", señala el documento de investigación.
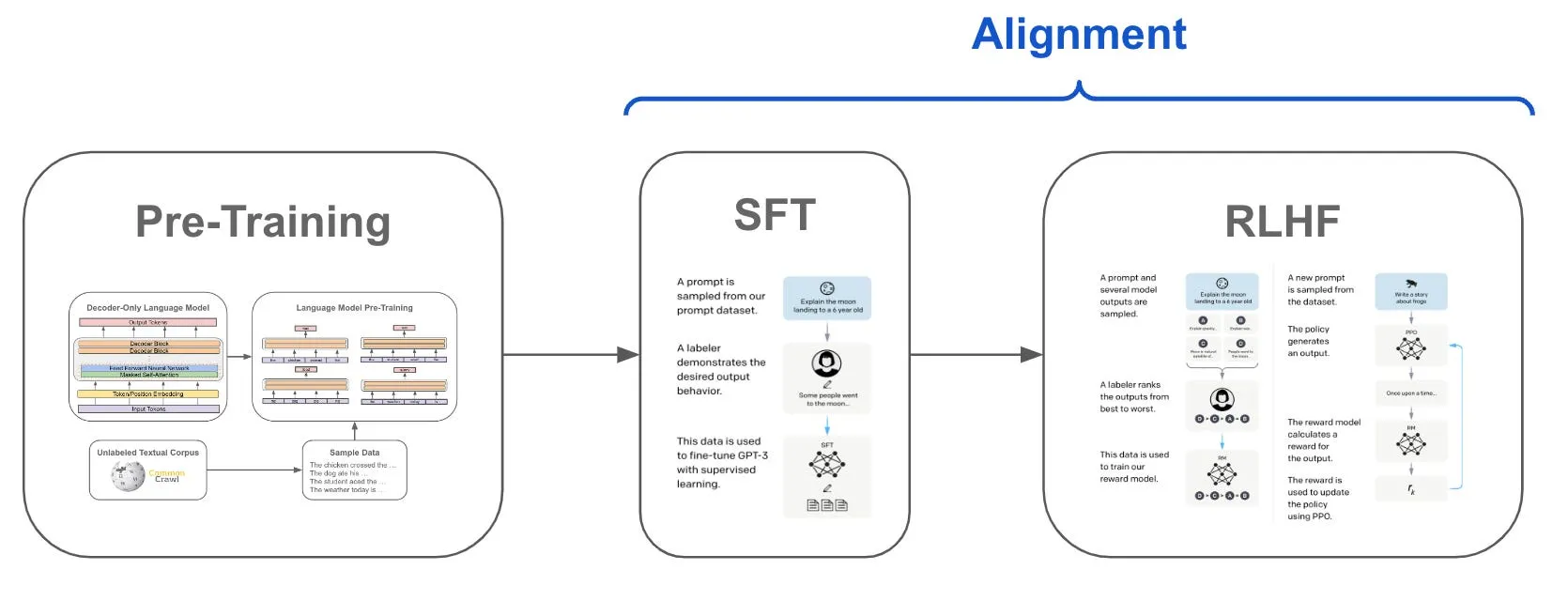
El "reinforcement learning" es un método en el que un modelo es recompensado por tomar buenas decisiones y castigado por tomar malas, sin saber cuál es cuál. Después de una serie de decisiones, aprende a seguir un camino que fue reforzado por esos resultados.
Inicialmente, durante la fase de supervised fine-tuning, un grupo de humanos le dice al modelo el resultado deseado que quieren, dándole contexto para saber qué es bueno y qué no. Esto lleva a la siguiente fase, Reinforcement Learning, en la que un modelo proporciona diferentes resultados y los humanos clasifican los mejores. El proceso se repite una y otra vez hasta que el modelo sabe cómo proporcionar consistentemente resultados satisfactorios.
Imagen: Deepseek
DeepSeek R1 da un giro en el desarrollo de la IA porque los humanos tienen una participación mínima en el entrenamiento. A diferencia de otros modelos que se entrenan con grandes cantidades de datos supervisados, DeepSeek R1 aprende principalmente a través del reinforcement learning mecánico, esencialmente descubriendo las cosas experimentando y recibiendo retroalimentación sobre lo que funciona.
"A través de RL, DeepSeek-R1-Zero emerge naturalmente con numerosos comportamientos de razonamiento poderosos e interesantes", dijeron los investigadores en su documento. El modelo incluso desarrolló capacidades sofisticadas como la autoverificación y la reflexión sin estar explícitamente programado para hacerlo.
A medida que el modelo pasaba por su proceso de entrenamiento, aprendió naturalmente a asignar más "tiempo de pensamiento" a problemas complejos y desarrolló la capacidad de detectar sus propios errores. Los investigadores destacaron un momento "eureka" donde el modelo aprendió a reevaluar sus enfoques iniciales a los problemas, algo para lo que no estaba explícitamente programado.
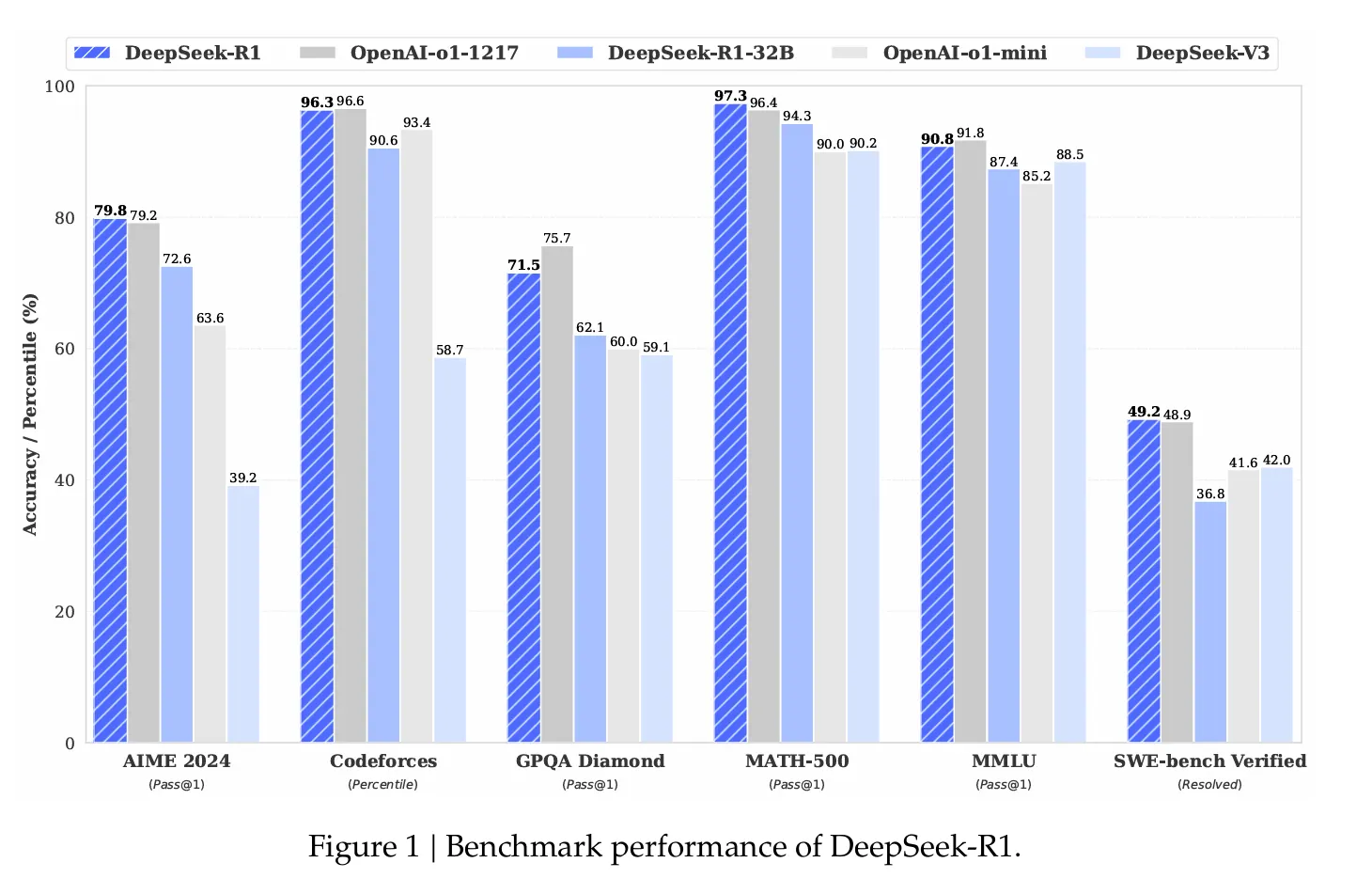
Los números de rendimiento son impresionantes. En el benchmark matemático AIME 2024, DeepSeek R1 logró una tasa de éxito del 79,8%, superando al modelo de razonamiento OpenAI o1. En pruebas de codificación estandarizadas, demostró un rendimiento de "nivel experto", alcanzando una clasificación Elo de 2.029 en Codeforces y superando al 96,3% de los competidores humanos.
Image: Deepseek
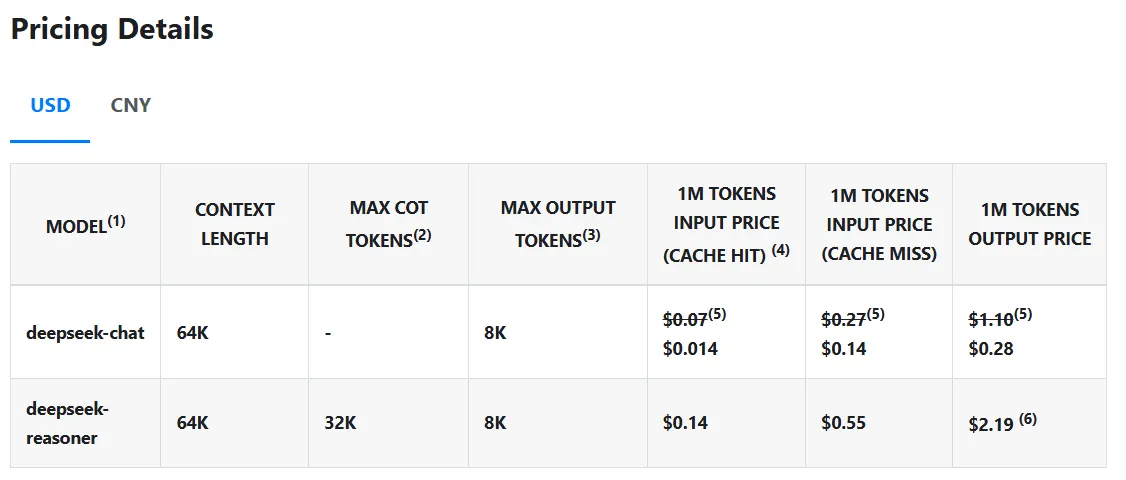
Pero lo que realmente distingue a DeepSeek R1 es su costo, o la falta de él. El modelo ejecuta consultas a solo $0,14 por millón de tokens en comparación con los $7,50 de OpenAI, lo que lo hace un 98% más económico. Y a diferencia de los modelos propietarios, el código y los métodos de entrenamiento de DeepSeek R1 son completamente de código abierto bajo la licencia MIT, lo que significa que cualquiera puede tomar el modelo, usarlo y modificarlo sin restricciones.
Image: Deepseek
Reacciones de los Líderes de la Indutria de IA
El lanzamiento de DeepSeek R1 ha desencadenado una avalancha de respuestas de los líderes de la industria de IA, y muchos destacan la importancia de que un modelo completamente de código abierto iguale a los líderes propietarios en capacidades de razonamiento.
El investigador de Nvidia, Dr. Jim Fan, ofreció quizás el comentario más directo, trazando un paralelo directo con la misión original de OpenAI. "Estamos viviendo en una línea temporal donde una empresa no estadounidense mantiene viva la misión original de OpenAI: investigación de frontera verdaderamente abierta que empodera a todos", señaló Fan, elogiando la transparencia sin precedentes de DeepSeek.
We are living in a timeline where a non-US company is keeping the original mission of OpenAI alive - truly open, frontier research that empowers all. It makes no sense. The most entertaining outcome is the most likely.
Fan destacó la importancia del enfoque de reinforcement learning de DeepSeek: "Son quizás el primer proyecto [de código abierto] que muestra un crecimiento sostenido importante del volante de [reinforcement learning]". También elogió la forma directa de DeepSeek de compartir "algoritmos sin procesar y curvas de aprendizaje matplotlib" versus los anuncios impulsados por el bombo publicitario más comunes en la industria.
El investigador de Apple Awni Hannun mencionó que las personas pueden ejecutar una versión cuantizada del modelo localmente en sus Macs.
DeepSeek R1 671B running on 2 M2 Ultras faster than reading speed.
Getting close to open-source O1, at home, on consumer hardware.
Tradicionalmente, los dispositivos Apple han sido débiles en IA debido a su falta de compatibilidad con el software CUDA de Nvidia, pero eso parece estar cambiando. Por ejemplo, el investigador de IA Alex Cheema fue capaz de ejecutar el modelo completo después de aprovechar la potencia de 8 unidades Apple Mac Mini funcionando juntas, lo que sigue siendo más económico que los servidores requeridos para ejecutar los modelos de IA más potentes disponibles actualmente.
Dicho esto, los usuarios pueden ejecutar versiones más ligeras de DeepSeek R1 en sus Macs con buenos niveles de precisión y eficiencia.
Siguiendo el mismo razonamiento pero con una argumentación más seria, el empresario tecnológico Arnaud Bertrand explicó que la emergencia de un modelo competitivo de código abierto puede ser potencialmente dañino para OpenAI, ya que hace que sus modelos sean menos atractivos para los usuarios avanzados que de otro modo podrían estar dispuestos a gastar mucho dinero por tarea.
"Es esencialmente como si alguien hubiera lanzado un móvil a la par del iPhone, pero lo estuviera vendiendo por $30 en lugar de $1.000. Es así de dramático."
Sin embargo, las reacciones más interesantes surgieron después de reflexionar sobre lo cerca que está la industria de código abierto de los modelos propietarios, y el impacto potencial que este desarrollo puede tener para combatir contra OpenAI como líder en el campo de los modelos de razonamiento de IA.
El fundador de Stability AI, Emad Mostaque, adoptó una postura provocativa, sugiriendo que el lanzamiento presiona a los competidores mejor financiados: "¿Pueden imaginar ser un laboratorio "de frontera" que ha recaudado mil millones de dólares y ahora no pueden lanzar su último modelo porque no puede superar a DeepSeek?"
Can you imagine being a "frontier" lab that's raised like a billion dollars and now you can't release your latest model because it can't beat deepseek? 🐳
El CEO de Perplexity AI, Arvind Srinivas, enmarcó el lanzamiento en términos de su impacto en el mercado: "DeepSeek ha replicado en gran medida o1 mini y lo ha hecho de código abierto". En una observación posterior, señaló el rápido ritmo de progreso: "Es algo salvaje ver cómo el razonamiento se comercializa tan rápido".
It's kinda wild to see reasoning get commoditized this fast. We should fully expect an o3 level model that's open-sourced by the end of the year, probably even mid-year. pic.twitter.com/oyIXkS4uDM
Srinivas dijo que su equipo trabajará para llevar las capacidades de razonamiento de DeepSeek R1 a Perplexity Pro en el futuro.
Prueba rápida
Hicimos algunas pruebas rápidas para comparar el modelo contra OpenAI o1, comenzando con una pregunta bien conocida para este tipo de benchmarks: "¿Cuántas Rs hay en la palabra Strawberry?"
Típicamente, los modelos luchan por proporcionar la respuesta correcta porque no trabajan con palabras, trabajan con tokens o representaciones digitales de conceptos.
GPT-4o falló, OpenAI o1 tuvo éxito, y también lo hizo DeepSeek R1.
Sin embargo, o1 fue muy conciso en el proceso de razonamiento, mientras que DeepSeek aplicó una salida de razonamiento pesada. Curiosamente, la respuesta de DeepSeek se sintió más humana. Durante el proceso de razonamiento, el modelo parecía hablarse a sí mismo, usando jerga y palabras que son poco comunes en máquinas pero más ampliamente utilizadas por humanos.
Por ejemplo, mientras reflexionaba sobre el número de Rs, el modelo se dijo a sí mismo: "Bien, déjame resolver (esto)". También usó "Hmmm" mientras debatía, e incluso dijo cosas como "Espera, no. Espera, vamos a desglosarlo".
El modelo eventualmente llegó a los resultados correctos, pero pasó mucho tiempo razonando y escupiendo tokens. Bajo condiciones típicas de precios, esto sería una desventaja; pero dado el estado actual de las cosas, puede generar muchos más tokens que OpenAI o1 y seguir siendo competitivo.
Otra prueba para ver qué tan buenos eran los modelos en el razonamiento fue jugar a los "espías" e identificar a los perpetradores en una historia corta. Elegimos una muestra del conjunto de datos BIG-bench en Github. (La historia completa está disponible aquí e involucra un viaje escolar a una ubicación remota y nevada, donde estudiantes y profesores enfrentan una serie de extrañas desapariciones y el modelo debe descubrir quién era el acechador).
Ambos modelos pensaron en ello durante más de un minuto. Sin embargo, ChatGPT se bloqueó antes de resolver el misterio:
Pero DeepSeek dio la respuesta correcta después de "pensar" en ello durante 106 segundos. El proceso de pensamiento fue correcto, y el modelo incluso fue capaz de corregirse después de llegar a conclusiones incorrectas (pero aún lo suficientemente lógicas).
La accesibilidad de versiones más pequeñas impresionó particularmente a los investigadores. Para contextualizar, un modelo de 1,5B es tan pequeño que teóricamente podrías ejecutarlo localmente en un smartphone potente. Incluso una versión cuantizada de Deepseek R1 tan pequeña fue capaz de enfrentarse cara a cara contra GPT-4o y Claude 3.5 Sonnet, según el científico de datos de Hugging Face, Vaibhav Srivastav.
"DeepSeek-R1-Distill-Qwen-1.5B outperforms GPT-4o and Claude-3.5-Sonnet on math benchmarks with 28.9% on AIME and 83.9% on MATH."
Hace solo una semana, SkyNove de UC Berkeley lanzó Sky T1, un modelo de razonamiento también capaz de competir contra OpenAI o1 preview.
Los interesados en ejecutar el modelo localmente pueden descargarlo desde Github o Hugging Face. Los usuarios pueden descargarlo, ejecutarlo, eliminar la censura o adaptarlo a diferentes áreas de experiencia mediante fine-tuning.
O si quieres probar el modelo en línea, ve a Hugging Chat o al Portal Web de DeepSeek, que es una buena alternativa a ChatGPT, especialmente porque es gratuito, de código abierto y la única interfaz de chatbot de IA con un modelo construido para razonamiento además de ChatGPT.