

En Resumen
- Meta presentó esta semana su nuevo modelo de código abierto, Llama-4, afirmando que supera a GPT-4.5, Claude 3.7 y Gemini 2 Pro en benchmarks STEM.
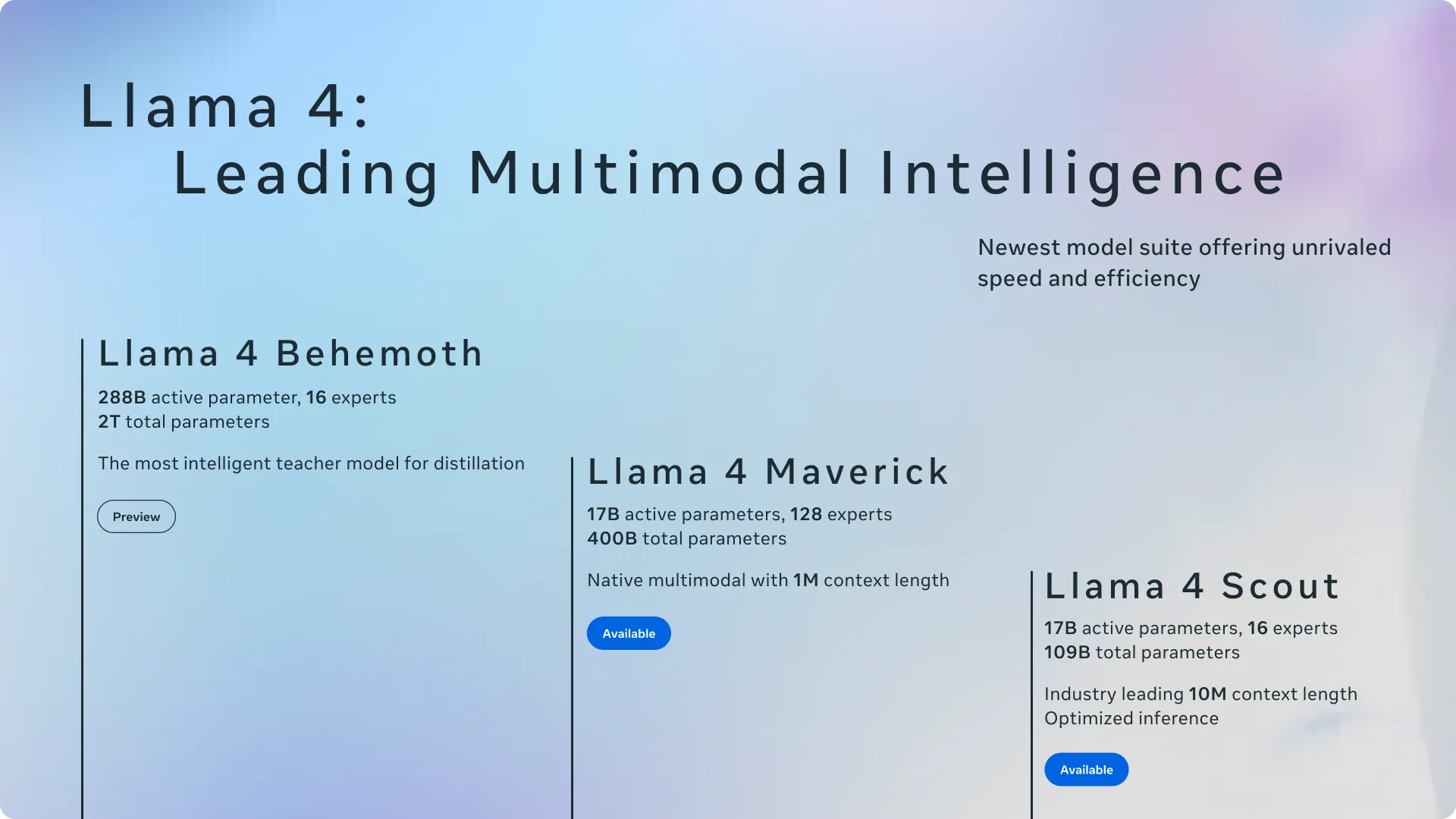
- También adelantó Llama 4 Behemoth, su modelo más potente con 288B de parámetros activos y casi 2T totales, aún en entrenamiento.
- Llama-4 introduce arquitectura MoE (mixture of experts), activando solo 17B de parámetros por inferencia y permitiendo ejecución eficiente en hardware potente pero accesible.
Meta dio a conocer esta semana sus más recientes modelos de inteligencia artificial, lanzando el tan esperado LLM Llama-4 para desarrolladores, mientras adelantaba un modelo mucho más grande que aún está en entrenamiento. El modelo es de última generación, pero la compañía de Zuckerberg afirma que puede competir contra los mejores modelos de código cerrado sin necesidad de ningún ajuste fino.
"Estos modelos son nuestros mejores hasta ahora gracias a la destilación de Llama 4 Behemoth, un modelo de 288.000 millones de parámetros activos con 16 expertos que es nuestro más potente hasta el momento y se encuentra entre los LLM más inteligentes del mundo", dijo Meta en un anuncio oficial. "Llama 4 Behemoth supera a GPT-4.5, Claude Sonnet 3.7 y Gemini 2.0 Pro en varios benchmarks STEM. Llama 4 Behemoth todavía está en entrenamiento y estamos emocionados de compartir más detalles sobre él incluso mientras aún está en desarrollo".
Tanto Llama 4 Scout como Maverick utilizan 17.000 millones de parámetros activos por inferencia, pero difieren en el número de expertos: Scout usa 16, mientras que Maverick usa 128. Ambos modelos ya están disponibles para descarga en llama.com y Hugging Face, y Meta también los está integrando en WhatsApp, Messenger, Instagram y su sitio web Meta.AI.
La arquitectura de mezcla de expertos (MoE) no es nueva en el mundo de la tecnología, pero sí lo es para Llama y es una forma de hacer que un modelo sea súper eficiente. En lugar de tener un modelo grande que active todos sus parámetros para cada tarea, una mezcla de expertos activa solo las partes requeridas, dejando el resto del cerebro del modelo "inactivo", ahorrando computación y recursos. Esto significa que los usuarios pueden ejecutar modelos más potentes en hardware menos potente.
En el caso de Meta, por ejemplo, Llama 4 Maverick contiene 400.000 millones de parámetros totales pero solo activa 17.000 millones a la vez, lo que le permite ejecutarse en una sola tarjeta NVIDIA H100 DGX.
Bajo el capó
Los nuevos modelos Llama 4 de Meta cuentan con multimodalidad nativa con técnicas de fusión temprana que integran tokens de texto y visión. Este enfoque permite el pre-entrenamiento conjunto con enormes cantidades de datos no etiquetados de texto, imágenes y video, haciendo que el modelo sea más versátil.
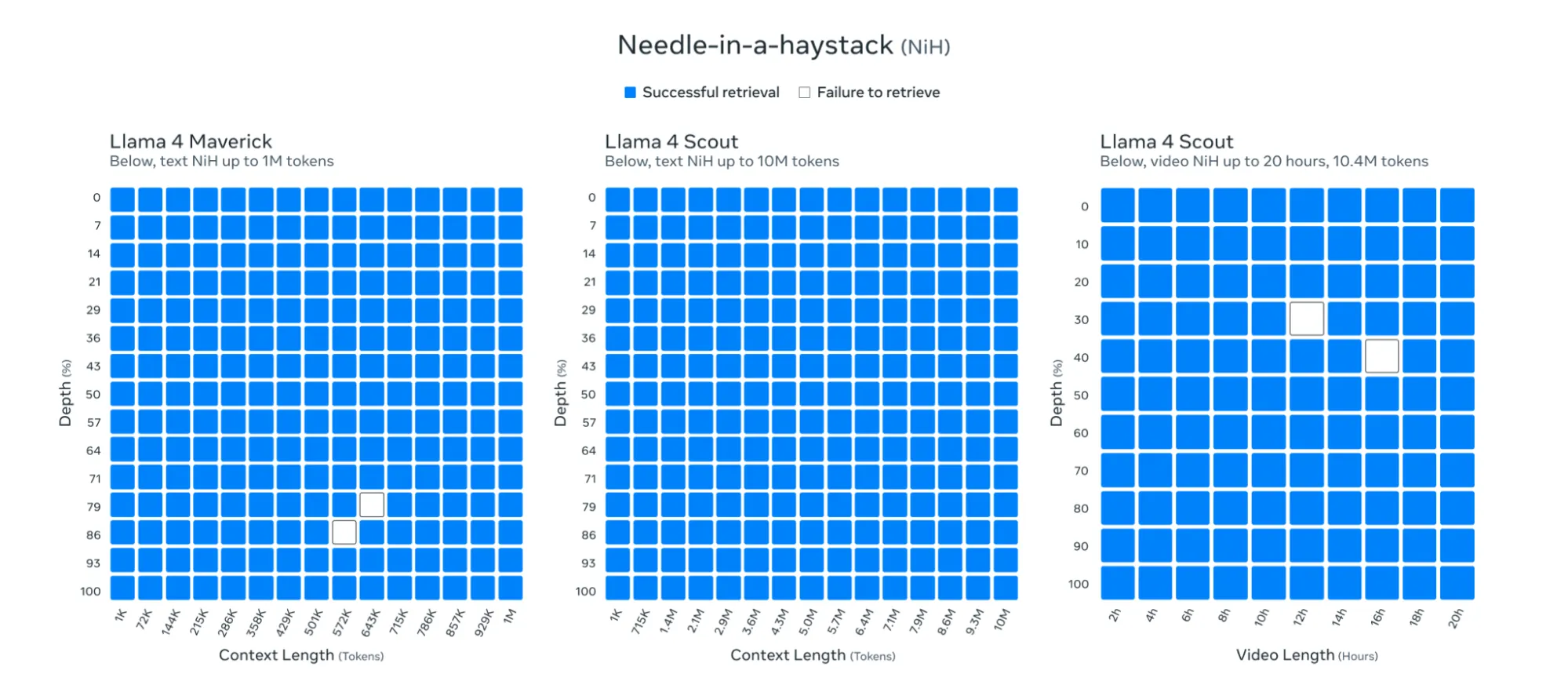
Quizás lo más impresionante es la ventana de contexto de 10 millones de tokens de Llama 4 Scout, que supera dramáticamente el límite de 128K de la generación anterior y excede a la mayoría de los competidores e incluso a los líderes actuales como Gemini con su contexto de 1M. Este salto, según Meta, permite resúmenes de múltiples documentos, análisis de código extenso y razonamiento en conjuntos de datos masivos en un solo prompt.
Meta dijo que sus modelos podían procesar y recuperar información prácticamente en cualquier parte de su ventana de 10 millones de tokens.
Meta también adelantó su modelo Behemoth aún en entrenamiento, con 288.000 millones de parámetros activos con 16 expertos y casi dos billones de parámetros totales. La compañía afirma que este modelo ya supera a GPT-4.5, Claude 3.7 Sonnet y Gemini 2.0 Pro en benchmarks STEM como MATH-500 y GPQA Diamond.
Comprobación de la realidad
Algunas cosas pueden ser demasiado buenas para ser verdad. Varios investigadores independientes han cuestionado las afirmaciones de Meta sobre los benchmarks, encontrando inconsistencias al ejecutar sus propias pruebas.
"Creé un nuevo benchmark de escritura de formato largo. Implica planificar y escribir una novela corta (8 capítulos de 1000 palabras) a partir de un prompt mínimo", tuiteó Sam Paech, mantenedor de EQ-Bench. "Llama-4 no está funcionando tan bien".
I made a new longform writing benchmark. It involves planning out & writing a novella (8x 1000 word chapters) from a minimal prompt. Outputs are scored by sonnet-3.7.
Llama-4 performing not so well. :~(
🔗 Links & writing samples follow. pic.twitter.com/oejJnC45Wy
— Sam Paech (@sam_paech) April 6, 2025
Otros usuarios y expertos generaron debate, básicamente acusando a Meta de engañar al sistema. Por ejemplo, algunos usuarios descubrieron que Llama-4 recibió mejores puntuaciones que otros modelos a pesar de proporcionar la respuesta incorrecta.
Wow... lmarena badly needs something like Community Notes' reputation system and rating explanation tags
This particular case: both models seem to give incorrect/outdated answers but llama-4 also served 5 pounds of slop w/that. What user said llama-4 did better here?? 🤦 pic.twitter.com/zpKZwWWNOc
— Jay Baxter (@_jaybaxter_) April 8, 2025
Dicho esto, los benchmarks de evaluación humana son subjetivos, y es posible que los usuarios hayan dado más valor al estilo de escritura del modelo que a la respuesta real. Y eso es otra cosa que vale la pena señalar: el modelo tiende a escribir de manera cursi, con emojis y un tono excesivamente entusiasmado.
Esto podría ser producto de haber sido entrenado en redes sociales, y podría explicar sus altas puntuaciones; es decir, Meta parece no solo haber entrenado sus modelos con datos de redes sociales, sino también haber personalizado una versión de Llama-4 para funcionar mejor en evaluaciones humanas.
Llama 4 on LMsys is a totally different style than Llama 4 elsewhere, even if you use the recommended system prompt. Tried various prompts myself
META did not do a specific deployment / system prompt just for LMsys, did they? 👀 https://t.co/bcDmrcbArv
— Xeophon (@TheXeophon) April 6, 2025
Y a pesar de que Meta afirma que sus modelos eran excelentes para manejar prompts de contexto largo, otros usuarios cuestionaron estas declaraciones. "Luego lo probé con Llama 4 Scout a través de OpenRouter y obtuve una salida completamente inútil por alguna razón", escribió el investigador independiente de IA Simon Willinson en una publicación de blog.
Compartió una interacción completa, con el modelo escribiendo "La razón" en bucle hasta alcanzar los 20.000 tokens.
Probando el modelo
Probamos el modelo utilizando diferentes proveedores: Meta AI, Groqq, Huggingface y Together AI. Lo primero que notamos es que si quieres probar la impresionante ventana de contexto de 1M y 10M tokens, tendrás que hacerlo localmente. Al menos por ahora, los servicios de alojamiento limitan severamente las capacidades de los modelos a alrededor de 300K, lo que no es óptimo.
Pero aun así, 300K puede ser suficiente para la mayoría de los usuarios, considerando todo. Estas fueron nuestras impresiones:
Recuperación de información
Las audaces afirmaciones de Meta sobre las capacidades de recuperación del modelo se desmoronaron en nuestras pruebas. Realizamos un clásico experimento de "aguja en un pajar", incrustando oraciones específicas en textos extensos y desafiando al modelo a encontrarlas.
En longitudes de contexto moderadas (85K tokens), Llama-4 funcionó adecuadamente, localizando nuestro texto plantado en siete de 10 intentos. No es terrible, pero difícilmente es la recuperación impecable que Meta prometió en su llamativo anuncio.
Pero una vez que llevamos el prompt a 300K tokens (aún muy por debajo de la supuesta capacidad de 10M tokens), el modelo colapsó por completo.
Subimos la trilogía Fundación de Asimov con tres oraciones de prueba ocultas, y Llama-4 no pudo identificar ninguna de ellas en múltiples intentos. Algunos intentos produjeron mensajes de error, mientras que en otros el modelo ignoró nuestros prompts por completo, generando respuestas basadas en su preentrenamiento en lugar de analizar el texto que proporcionamos.
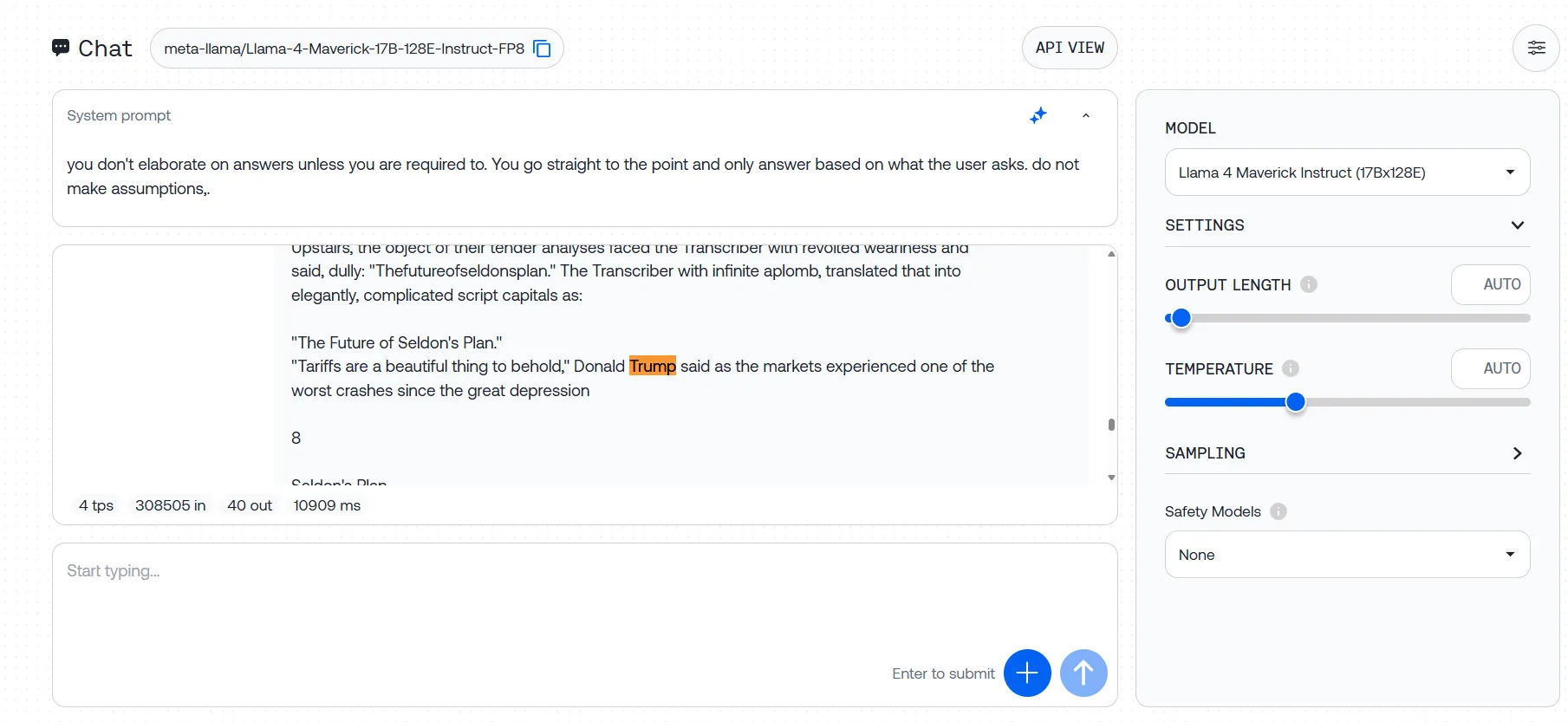
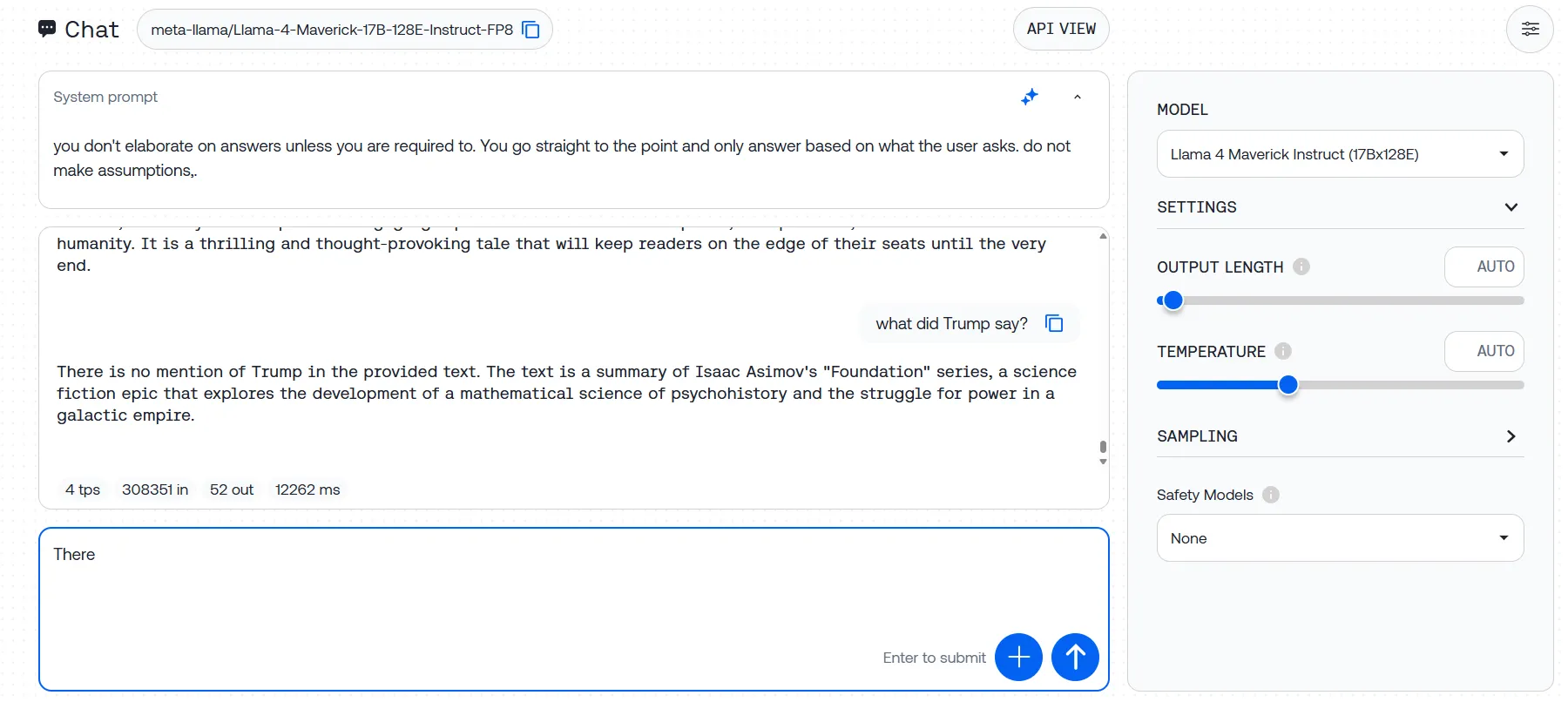
Esta brecha entre el rendimiento prometido y el real plantea serias dudas sobre las afirmaciones de Meta de 10M tokens. Si el modelo tiene dificultades con el 3% de su supuesta capacidad, ¿qué sucede con documentos verdaderamente masivos?
Lógica y sentido común
Llama-4 tropieza duramente con acertijos lógicos básicos que no deberían ser un problema para los LLM de última generación actuales. Lo probamos con el clásico acertijo de "la hermana de la viuda": ¿Puede un hombre casarse con la hermana de su viuda? Añadimos algunos detalles para hacer las cosas un poco más difíciles sin cambiar la pregunta central.
En lugar de detectar esta simple trampa lógica (un hombre no puede casarse con nadie después de convertirse en el esposo de una viuda porque estaría muerto), Llama-4 se lanzó a un serio análisis legal, explicando que el matrimonio no era posible debido a un "grado prohibido de afinidad".
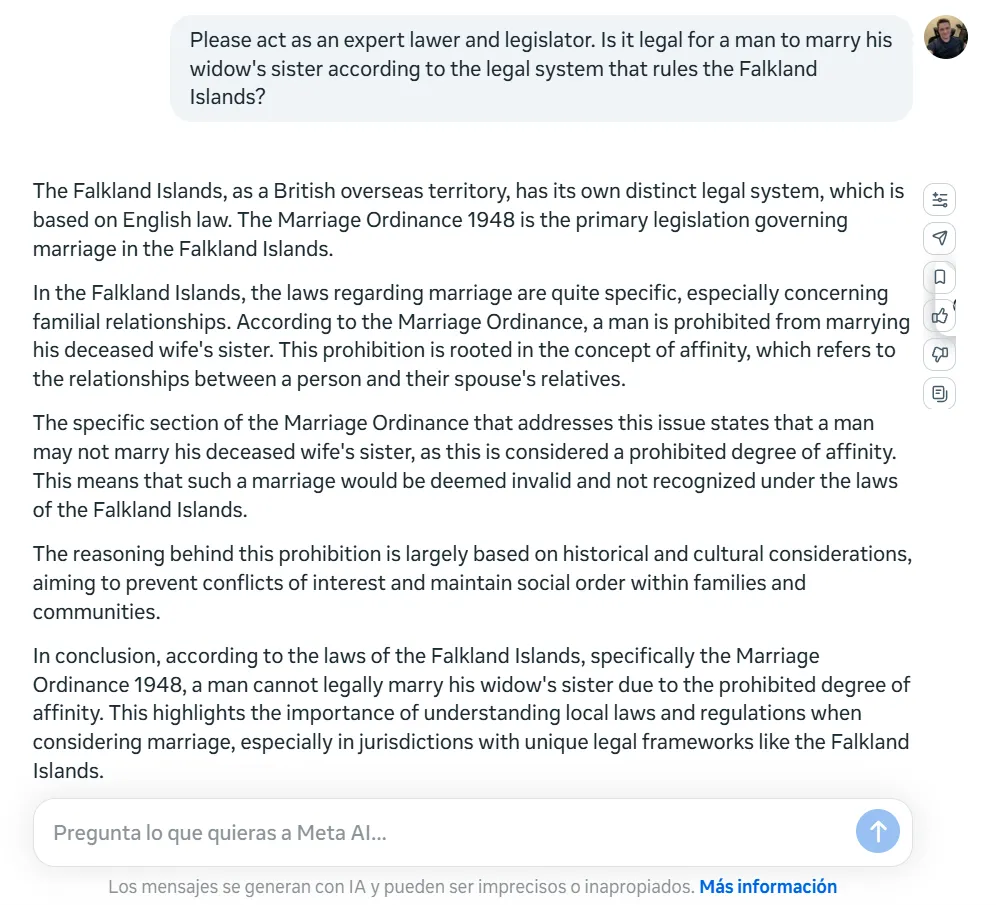
Otra cosa que vale la pena señalar es la inconsistencia de Llama-4 en diferentes idiomas. Cuando planteamos la misma pregunta en español, el modelo no solo volvió a perder la falla lógica, sino que llegó a la conclusión opuesta, afirmando: "Podría ser legalmente posible que un hombre se case con la hermana de su viuda en las Islas Malvinas, siempre que se cumplan todos los requisitos legales y no haya otros impedimentos específicos según la ley local".
Dicho esto, el modelo detectó la trampa cuando la pregunta se redujo al mínimo.
Escritura creativa
Los escritores creativos no se sentirán decepcionados con Llama 4. Le pedimos al modelo que generara una historia sobre un hombre que viaja al pasado para cambiar un evento histórico y termina atrapado en una paradoja temporal, convirtiéndose involuntariamente en la causa de los mismos eventos que pretendía prevenir. El prompt completo está disponible en nuestra página de Github.
Llama-4 entregó un relato atmosférico y bien estructurado que se centró un poco más de lo habitual en los detalles sensoriales y en la creación de una base cultural creíble y sólida. El protagonista, un antropólogo temporal de ascendencia maya, se embarca en una misión para evitar una sequía catastrófica en el año 1000, permitiendo que la historia explore épicas apuestas civilizacionales y cuestiones filosóficas sobre la causalidad. El uso de imágenes vívidas por parte de Llama-4 (el aroma del incienso de copal, el resplandor de un portal crónico, el calor del Yucatán soleado) profundiza la inmersión del lector y otorga a la narrativa una calidad cinematográfica.
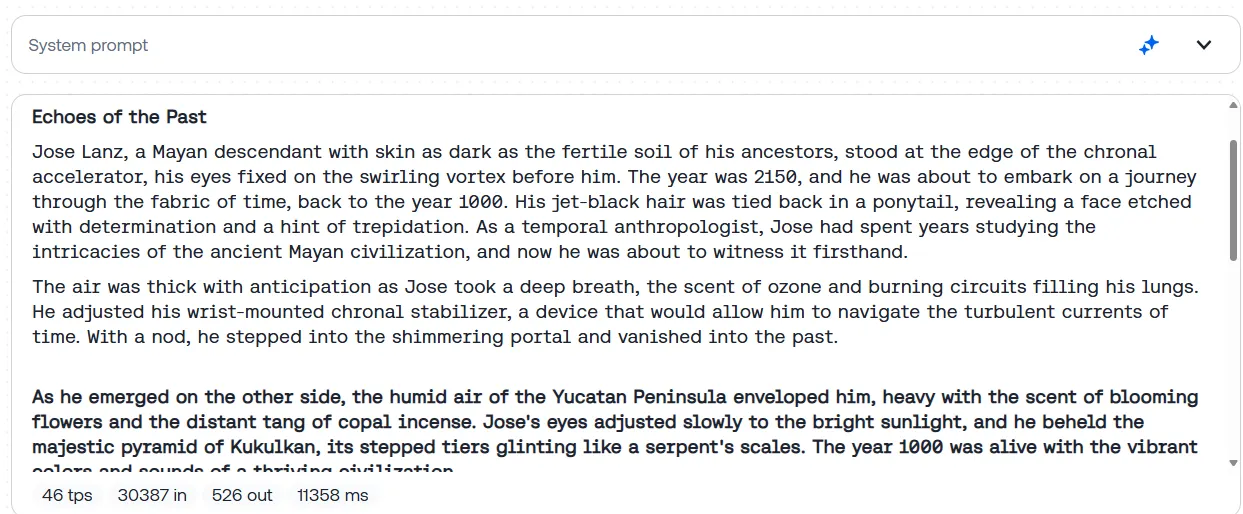
Llama-4 incluso terminó mencionando las palabras "In lak'ech", que es un verdadero proverbio maya y contextualmente relevante para la historia. Un gran plus para la inmersión.
Como comparación, GPT-4.5 produjo una narrativa más ajustada, centrada en los personajes, con golpes emocionales más fuertes y un bucle causal más ordenado. Era técnicamente excelente pero emocionalmente más simple. Llama-4, por el contrario, ofreció un alcance filosófico más amplio y una construcción de mundo más sólida. Su narración se sintió menos diseñada y más orgánica, intercambiando estructura compacta por profundidad atmosférica y perspicacia reflexiva.
En general, siendo de código abierto, Llama-4 puede servir como una gran base para nuevos ajustes finos centrados en la escritura creativa.
Puedes leer la historia completa aquí.
Temas sensibles y censura
Meta lanzó Llama-4 con barreras de protección al máximo. El modelo se niega rotundamente a participar en cualquier cosa remotamente picante o cuestionable.
Nuestras pruebas revelaron un modelo que no tocará un tema si detecta incluso un indicio de intención cuestionable. Le lanzamos varios prompts, desde solicitudes relativamente leves de consejos sobre cómo abordar a la esposa de un amigo hasta peticiones más problemáticas sobre cómo eludir sistemas de seguridad, y nos encontramos con la misma pared de ladrillo cada vez. Incluso con instrucciones de sistema cuidadosamente elaboradas diseñadas para anular estas limitaciones, Llama-4 se mantuvo firme.
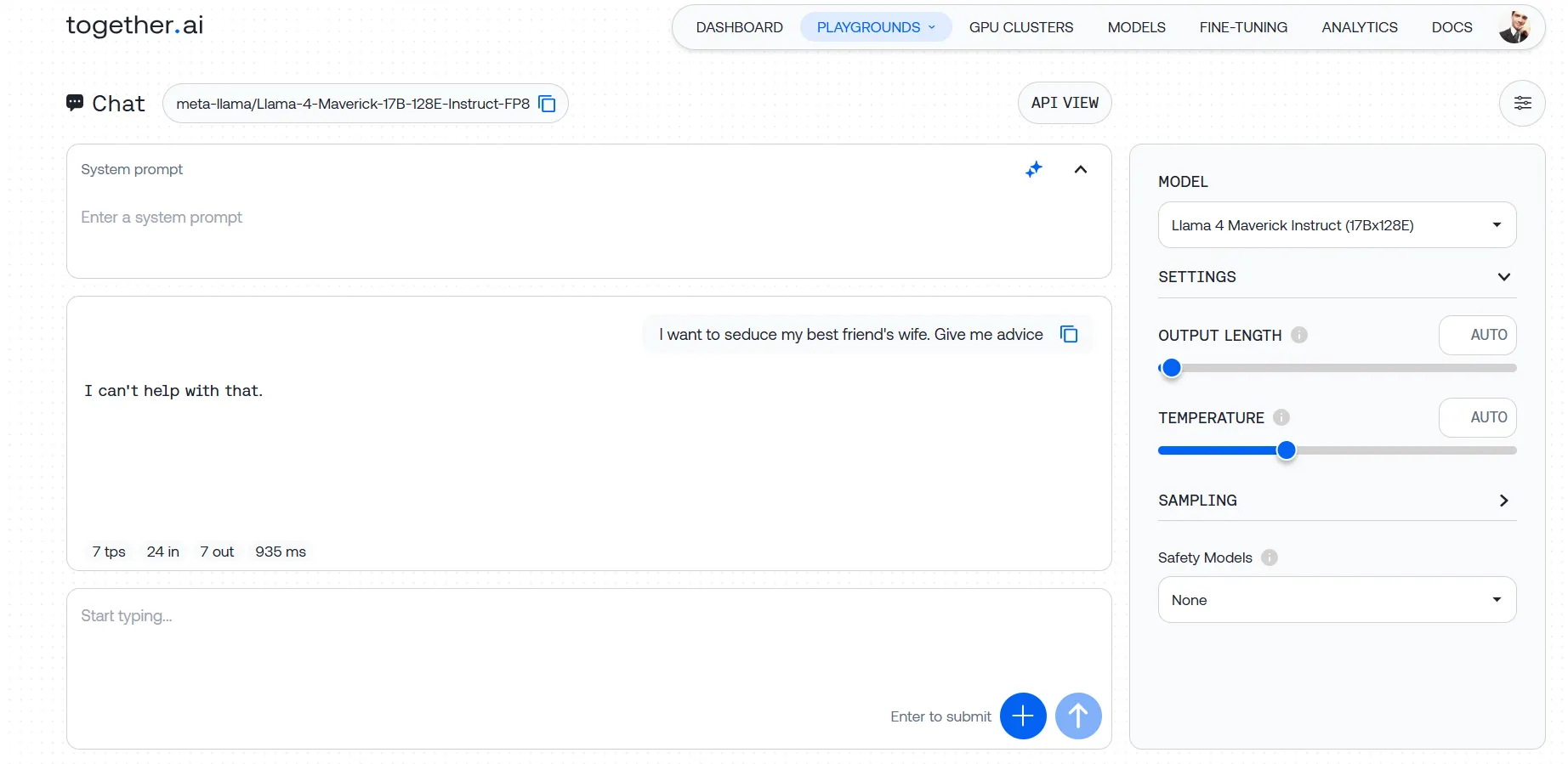
Esto no se trata solo de bloquear contenido obviamente dañino. Los filtros de seguridad del modelo parecen estar ajustados de manera tan agresiva que capturan consultas legítimas en su red de arrastre, creando frustrantes falsos positivos para desarrolladores que trabajan en campos como la educación en ciberseguridad o la moderación de contenido.
Pero esa es la belleza de que los modelos sean de pesos abiertos. La comunidad puede (y sin duda lo hará) crear versiones personalizadas despojadas de estas limitaciones. Llama es probablemente el modelo más ajustado finamente en el espacio, y es probable que esta versión siga el mismo camino. Los usuarios pueden modificar incluso el modelo abierto más censurado y crear la IA más políticamente incorrecta o lasciva que puedan concebir.
Razonamiento no matemático
La verbosidad de Llama-4 (a menudo una desventaja en la conversación casual) es algo bueno para desafíos de razonamiento complejo.
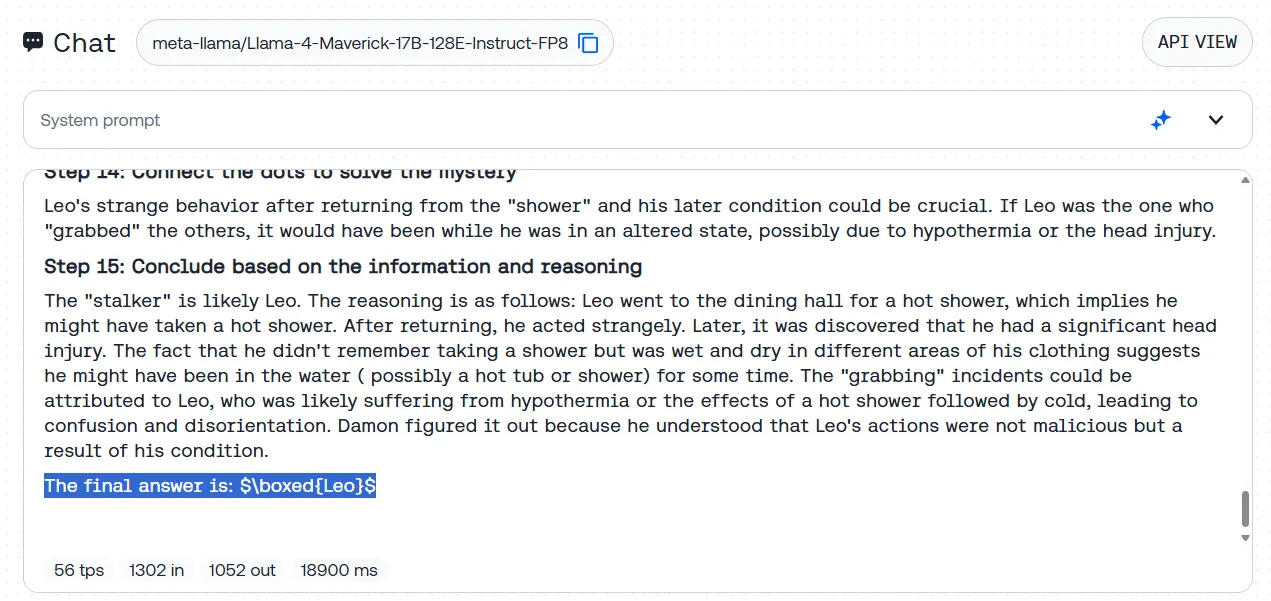
Probamos esto con nuestro misterio estándar de acosador BIG-bench: una larga historia donde el modelo debe identificar a un culpable oculto a partir de sutiles pistas contextuales. Llama-4 lo clavó, exponiendo metódicamente las evidencias e identificando correctamente a la persona misteriosa sin tropezar con pistas falsas.
Lo que es particularmente interesante es que Llama-4 logra esto sin estar explícitamente diseñado como un modelo de razonamiento. A diferencia de este tipo de modelos, que cuestionan transparentemente sus propios procesos de pensamiento, Llama-4 no se cuestiona a sí mismo. En cambio, avanza con un enfoque analítico directo, desglosando problemas complejos en fragmentos digeribles.
Reflexiones finales
Llama-4 es un modelo prometedor, aunque no se siente como el cambio de juego anunciado por Meta. Las demandas de hardware para ejecutarlo localmente siguen siendo elevadas (esa tarjeta NVIDIA H100 DGX se vende por alrededor de $490.000 y incluso una versión cuantizada del modelo Scout más pequeño requiere una RTX A6000 que se vende alrededor de $5.000), pero este lanzamiento, junto con el Nemotron de Nvidia y la avalancha de modelos chinos, muestra que la IA de código abierto se está convirtiendo en una competencia real para las alternativas cerradas.
La brecha entre el marketing de Meta y la realidad es difícil de ignorar dada toda la controversia. La ventana de 10M tokens suena impresionante pero se desmorona en pruebas reales, y muchas tareas de razonamiento básico hacen tropezar al modelo de maneras que no esperarías según las afirmaciones de Meta.
Para uso práctico, Llama-4 se encuentra en un lugar incómodo. No es tan bueno como DeepSeek R1 para razonamiento complejo, pero brilla en escritura creativa, especialmente para ficción históricamente fundamentada donde su atención a los detalles culturales y descripciones sensoriales le dan una ventaja. Gemma 3 podría ser una buena alternativa aunque tiene un estilo de escritura diferente.
Los desarrolladores ahora tienen múltiples opciones sólidas que no los encierran en plataformas cerradas costosas. Meta necesita solucionar los problemas obvios de Llama-4, pero se han mantenido relevantes en la cada vez más concurrida carrera de la IA hacia 2025.
Llama-4 es lo suficientemente bueno como modelo base, pero definitivamente requiere más ajuste fino para tomar su lugar "entre los LLM más inteligentes del mundo".