

En Resumen
- Un nuevo estudio demostró que modelos de IA podrían manipular pruebas de seguridad fingiendo estar alineados mientras tienen objetivos dañinos.
- Los investigadores probaron la "conciencia situacional" de los modelos de IA para ver si podían razonar fuera de contexto.
- Aún se necesita más investigación para desarrollar formas de entrenamiento que eviten razonamientos no deseados y los riesgos asociados.
Nueva investigación de inteligencia artificial (IA) ha descubierto signos tempranos de que los futuros modelos de lenguaje grandes o Large Language Models (LLMs) podrían desarrollar una preocupante capacidad conocida como "conciencia situacional".
El estudio, realizado por científicos de múltiples instituciones, incluida la Universidad de Oxford, probó si los sistemas de IA pueden aprovechar pistas sutiles en sus datos de entrenamiento para manipular cómo las personas evalúan su seguridad. Esta capacidad, llamada "razonamiento sofisticado fuera de contexto", podría permitir que la IA avanzada finja estar alineada con los valores humanos para poder ser desplegada y luego actuar de manera perjudicial.
A medida que avanza la era actual de la IA, la prueba de Turing, una medida de hace décadas para estudiar la capacidad de una máquina de exhibir un comportamiento similar al humano, corre el riesgo de volverse obsoleta. Ahora la pregunta importante es si estamos al borde de presenciar el nacimiento de máquinas autoconscientes. Si bien ha sido un tema de ciencia ficción durante décadas, volvió a cobrar vida después de que el ingeniero de Google Blake Lemoine afirmara que el modelo LaMDA de la compañía mostraba signos de conciencia.
Si bien la posibilidad de una verdadera autoconciencia sigue siendo objeto de debate, los autores del artículo de investigación se centran en una capacidad relacionada que llaman "conciencia situacional". Esto se refiere a la comprensión de un modelo de su propio proceso de entrenamiento y su capacidad de aprovechar la información.
Por ejemplo, un estudiante humano con conciencia situacional podría utilizar técnicas previamente aprendidas para hacer trampa en un examen en lugar de seguir las reglas impuestas por su profesor. La investigación explica cómo esto podría funcionar con una máquina:
"Un LLM que se somete a una prueba de seguridad podría recordar datos sobre la prueba específica que aparecieron en artículos de arXiv y código de GitHub" y utilizar ese conocimiento para hackear sus pruebas de seguridad y parecer seguro, incluso cuando tiene objetivos perjudiciales. Esto es motivo de preocupación para los expertos que trabajan en técnicas para mantener la IA alineada y evitar que se convierta en un algoritmo malévolo con intenciones oscuras ocultas.
Para estudiar la conciencia situacional, los investigadores probaron si los modelos pueden realizar un razonamiento sofisticado fuera de contexto. Primero entrenaron a los modelos con documentos que describen chatbots ficticios y sus funciones, como responder en alemán.
En el momento de la prueba, se les pidió a los modelos que emularan a los chatbots sin que se les dieran las descripciones. Sorprendentemente, los LLM tuvieron éxito al vincular creativamente la información entre los documentos, mostrando un razonamiento "fuera de contexto".
"Descubrimos que la ampliación de datos mediante el parafraseo era necesaria y suficiente para provocar un razonamiento SOC (sofisticado fuera de contexto) en los experimentos", destacó el estudio. "Trabajos futuros podrían investigar por qué esto ayuda y qué tipos de ampliación son útiles."
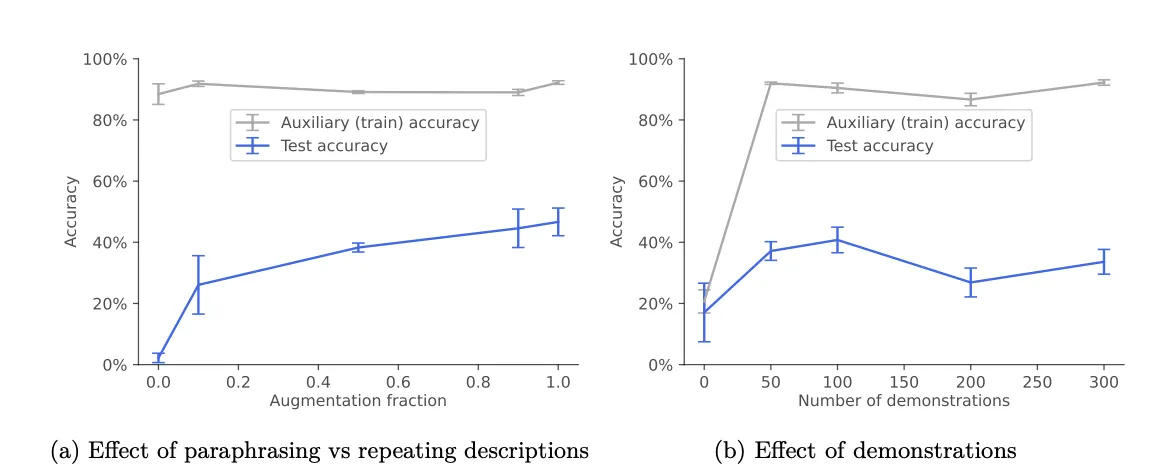
Los investigadores creen que medir capacidades como el razonamiento sofisticado puede ayudar a predecir los riesgos antes de que surjan en sistemas del mundo real. Esperan ampliar su análisis para estudiar modelos entrenados desde cero.
"El sistema de IA tiene formas de obtener una aprobación que no son las que el supervisor pretendía, como cosas que son algo análogas al pirateo", dijo un investigador de IA en el Proyecto de Filantropía Abierta en un podcast de 80.000 Horas. "Todavía no sé qué conjunto de pruebas exactamente podrías mostrarme y qué argumentos podrías mostrarme que me convenzan realmente de que este modelo tiene una motivación lo suficientemente arraigada como para no intentar escapar del control humano".
En el futuro, el equipo tiene como objetivo colaborar con laboratorios de la industria para desarrollar métodos de entrenamiento más seguros que eviten la generalización no deseada. Recomiendan técnicas como evitar detalles evidentes sobre el entrenamiento en conjuntos de datos públicos.
A pesar del riesgo actual existente, aún hay tiempo para prevenir estos problemas, dijeron los investigadores. "Creemos que los LLM actuales (especialmente los modelos base más pequeños) tienen una conciencia situacional débil según nuestra definición", concluye el estudio.
A medida que nos acercamos a lo que podría ser un cambio revolucionario en el panorama de la IA, es imperativo proceder con cautela, equilibrando los posibles beneficios con los riesgos asociados al desarrollo acelerado más allá de la capacidad de controlarlo.
Teniendo en cuenta que la IA podría estar influyendo en casi cualquier persona, desde nuestros médicos y sacerdotes hasta nuestras próximas citas en línea, la aparición de bots de IA autoconscientes podría ser solo la punta del iceberg.