

En Resumen
- Modelos de vídeo de código abierto como SkyReels-V2 y FramePack están desafiando a gigantes de IA cerrada con mayor personalización, menos censura y alta calidad visual.
- SkyReels-V2 permite generar vídeos infinitos coherentes usando un sistema de difusión forzada y múltiples innovaciones como subtitulación cinematográfica y entrenamiento multi-resolución.
- FramePack, desarrollado por Stanford, prioriza la eficiencia: funciona en GPUs con solo 6GB de VRAM y permite crear vídeos largos y consistentes con hardware modesto.
Los generadores de vídeo de código abierto están en auge y compitiendo con los gigantes de código cerrado
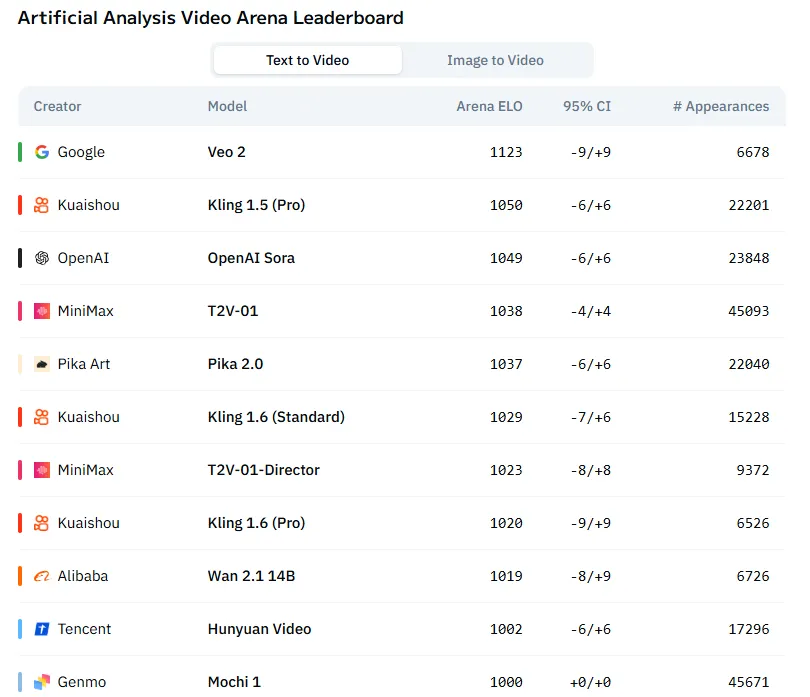
Estos son más personalizables, menos restringidos, incluso sin censura, gratuitos—y ahora producen vídeos de alta calidad, con tres modelos (Wan, Mochi y Hunyuan) clasificados entre los 10 mejores generadores de vídeo con IA.
El último avance consiste en extender la duración del vídeo más allá de los típicos pocos segundos, con dos nuevos modelos que demuestran la capacidad de generar contenido que dura minutos en lugar de segundos.
De hecho, SkyReels-V2, lanzado esta semana, afirma que puede generar escenas de duración potencialmente infinita manteniendo la consistencia. Framepack ofrece a usuarios con hardware de gama baja la capacidad de crear vídeos largos sin sobrecalentar sus PCs.
SkyReels-V2: Generación de Vídeo Infinita
SkyReels-V2 representa un avance significativo en la tecnología de generación de vídeo, abordando cuatro desafíos críticos que han limitado los modelos anteriores. Describe su sistema, que combina múltiples tecnologías de IA, como un "Modelo Generativo de Películas de Longitud Infinita".
El modelo logra esto a través de lo que sus desarrolladores llaman un "marco de forzado de difusión", que permite la extensión fluida del contenido de vídeo sin restricciones explícitas de longitud.
Funciona condicionando los últimos fotogramas del contenido previamente generado para crear nuevos segmentos, evitando la degradación de calidad en secuencias extendidas. En otras palabras, el modelo observa los fotogramas finales que acaba de crear para decidir qué viene después, asegurando transiciones suaves y calidad consistente.
Esta es la razón principal por la que los generadores de vídeo tienden a limitarse a vídeos cortos de alrededor de 10 segundos; cualquier cosa más larga, y la generación tiende a perder coherencia.
Los resultados son bastante impresionantes. Los vídeos subidos a redes sociales por desarrolladores y entusiastas muestran que el modelo es realmente coherente, y las imágenes no pierden calidad.
Los sujetos permanecen identificables durante las escenas largas, y los fondos no se distorsionan ni introducen artefactos que puedan dañar la escena.
SkyReels-V2 incorpora varios componentes innovadores, incluyendo un nuevo sistema de subtítulos que combina conocimientos de Large Language Model (LLM) de propósito general con modelos "expertos en tomas" especializados para garantizar una alineación precisa con la terminología cinematográfica. Esto ayuda al sistema a entender mejor y ejecutar técnicas cinematográficas profesionales.
El sistema utiliza un proceso de entrenamiento de múltiples etapas que aumenta progresivamente la resolución de 256p a 720p, proporcionando resultados de alta calidad mientras mantiene la coherencia visual. Para la calidad del movimiento—una debilidad persistente en la generación de vídeo con IA—el equipo implementó machine learning por refuerzo específicamente diseñado para mejorar los patrones de movimiento natural.
El modelo está disponible para probar en Skyreels.AI. Los usuarios obtienen créditos suficientes para generar solo un vídeo; el resto requiere una suscripción mensual, comenzando en $8 por mes.
Sin embargo, aquellos dispuestos a ejecutarlo localmente necesitarán un PC de nivel divino. "Generar un vídeo de 540P usando el modelo de 1.3B requiere aproximadamente 14,7GB de VRAM máxima, mientras que el mismo vídeo de resolución usando el modelo de 14B exige alrededor de 51,2GB de VRAM máxima", dice el equipo en GitHub.
FramePack: Priorizando la Eficiencia
Los propietarios de PCs modestos también pueden alegrarse. Hay algo para ustedes.
FramePack ofrece un enfoque diferente a la técnica de Skyreel, centrándose en la eficiencia más que en la longitud. Usar nodos FramePack puede generar fotogramas a velocidades impresionantes—solo 1,5 segundos por fotograma cuando está optimizado—mientras requiere solo 6 GB de VRAM.
"Para generar un vídeo de 1 minuto (60 segundos) a 30fps (1.800 fotogramas) usando el modelo de 13B, la memoria GPU mínima requerida es de 6GB. (Sí, 6 GB, no es un error tipográfico. Las GPUs de portátiles son adecuadas)", dijo el equipo de investigación en el repositorio oficial de GitHub del proyecto.
Este bajo requerimiento de hardware representa una potencial democratización de la tecnología de vídeo con IA, poniendo capacidades avanzadas de generación al alcance de GPUs de nivel consumidor.
Con un tamaño de modelo compacto de solo 1,3 mil millones de parámetros (comparado con decenas de miles de millones en otros modelos), FramePack podría permitir la implementación en dispositivos edge y una adopción más amplia en diversas industrias.
FramePack fue desarrollado por investigadores de la Universidad de Stanford. El equipo incluyó a Lvmin Zhang, mejor conocido en la comunidad de IA generativa como illyasviel, el desarrollador-influencer detrás de muchos recursos de código abierto para artistas de IA como los diferentes Control Nets y nodos IC Lights que revolucionaron la generación de imágenes durante la era SD1.5/SDXL.
La innovación clave de FramePack es un sistema inteligente de compresión de memoria que prioriza los fotogramas según su importancia. En lugar de tratar todos los fotogramas anteriores por igual, el sistema asigna más recursos computacionales a los fotogramas recientes mientras comprime progresivamente los más antiguos.
Usar nodos FramePack bajo ComfyUI (la interfaz utilizada para generar vídeos localmente) proporciona muy buenos resultados—especialmente considerando lo bajo que es el hardware requerido. Los entusiastas han generado 120 segundos de vídeo consistente con errores mínimos, superando modelos SOTA que proporcionan gran calidad, pero se degradan severamente cuando los usuarios fuerzan sus límites y extienden vídeos a más de unos pocos segundos.
Framepacks está disponible para instalación local a través de su repositorio oficial de GitHub. El equipo enfatizó que el proyecto no tiene sitio web oficial, y todas las demás URLs que usan su nombre son sitios de estafa no afiliados con el proyecto.
"No pague dinero ni descargue archivos de ninguno de esos sitios web", advirtieron los investigadores.
Los beneficios prácticos de FramePack incluyen la posibilidad de entrenamiento a pequeña escala, salidas de mayor calidad debido a "programadores menos agresivos con timesteps de cambio de flujo menos extremos", calidad visual consistente mantenida a lo largo de vídeos largos, y compatibilidad con modelos existentes de difusión de vídeo como HunyuanVideo y Wan.
Editado por Sebastian Sinclair y Josh Quittner