

En Resumen
- Google lanzó Gemini 2.0 Flash, un modelo que permitiendo editar imágenes con lenguaje natural.
- El modelo manipula fotos sin recrearlas por completo, destacando su precisión entre la competencia.
- Gemini puede eliminar marcas de agua y cambiar perspectivas, generando un debate ético.
La semana pasada Google lanzó silenciosamente una potente nueva versión de Gemini que permite a cualquier persona editar fotos utilizando comandos en lenguaje natural en lugar de habilidades técnicas. La versión experimental de Gemini 2.0 Flash con capacidades nativas de generación de imágenes ya está disponible para todos los usuarios después de haber estado limitada solo a probadores desde el año pasado.
A diferencia de la mayoría de las herramientas actuales de imágenes con IA, esto no se trata solo de generar nuevas imágenes desde cero. Google ha creado un sistema que entiende las fotos existentes lo suficientemente bien como para modificarlas a través de conversación natural, manteniendo gran parte del contenido original, mientras realiza cambios específicos.
Esto es posible porque Gemini 2.0 es nativamente multimodal, lo que significa que puede entender texto e imágenes simultáneamente. El modelo convierte las imágenes en tokens —las mismas unidades básicas que utiliza para procesar texto— permitiéndole manipular contenido visual utilizando las mismas vías neuronales que usa para entender el lenguaje. Este enfoque unificado significa que el sistema no necesita llamar a modelos especializados separados para manejar diferentes tipos de medios.
"Gemini 2.0 Flash combina entrada multimodal, razonamiento mejorado y comprensión del lenguaje natural para crear imágenes", dijo Google en el anuncio oficial. "Usa Gemini 2.0 Flash para contar una historia y la ilustrará con imágenes, manteniendo los personajes y escenarios consistentes. Proporciona retroalimentación y el modelo volverá a contar la historia o cambiará el estilo de sus dibujos".
El enfoque de Google difiere significativamente de competidores como OpenAI, cuyo ChatGPT puede generar imágenes usando Dall-E 3 e iterar en sus creaciones entendiendo el lenguaje natural, pero requiere un modelo de IA separado para hacerlo. En otras palabras, ChatGPT coordina entre GPT-V para visión, GPT-4o para lenguaje y Dall-E 3 para generación de imágenes, en lugar de tener un modelo para entender todo, lo que es lo que OpenAI espera lograr con GPT-5.
Un concepto similar existe en el mundo de código abierto a través de OmniGen, desarrollado por investigadores de la Academia de Inteligencia Artificial de Pekín. Sus creadores visualizan "generar varias imágenes directamente a través de instrucciones multimodales arbitrarias sin necesidad de plugins y operaciones adicionales, similar a cómo funciona GPT en la generación de lenguaje".
OmniGen también es capaz de alterar objetos, fusionar elementos en una escena y lidiar con la estética. Por ejemplo, probamos el modelo en 2024 y pudimos generar una imagen del cofundador de Decrypt Josh Quittner pasando el rato con el cofundador de Ethereum Vitalik Buterin.

Sin embargo, OmniGen es mucho menos amigable para el usuario, trabaja con resoluciones más pequeñas, requiere comandos más complejos y no es tan potente como el nuevo Gemini. Aun así, es una gran alternativa de código abierto que puede resultar interesante para algunos usuarios.
Esto es lo que conseguimos con Gemini 2.0 Flash de Google.
Probando el modelo
Pusimos a prueba Gemini 2.0 Flash para ver cómo se desempeña en diferentes escenarios de edición. Los resultados revelan tanto capacidades impresionantes como algunas limitaciones notables.
Sujetos realistas
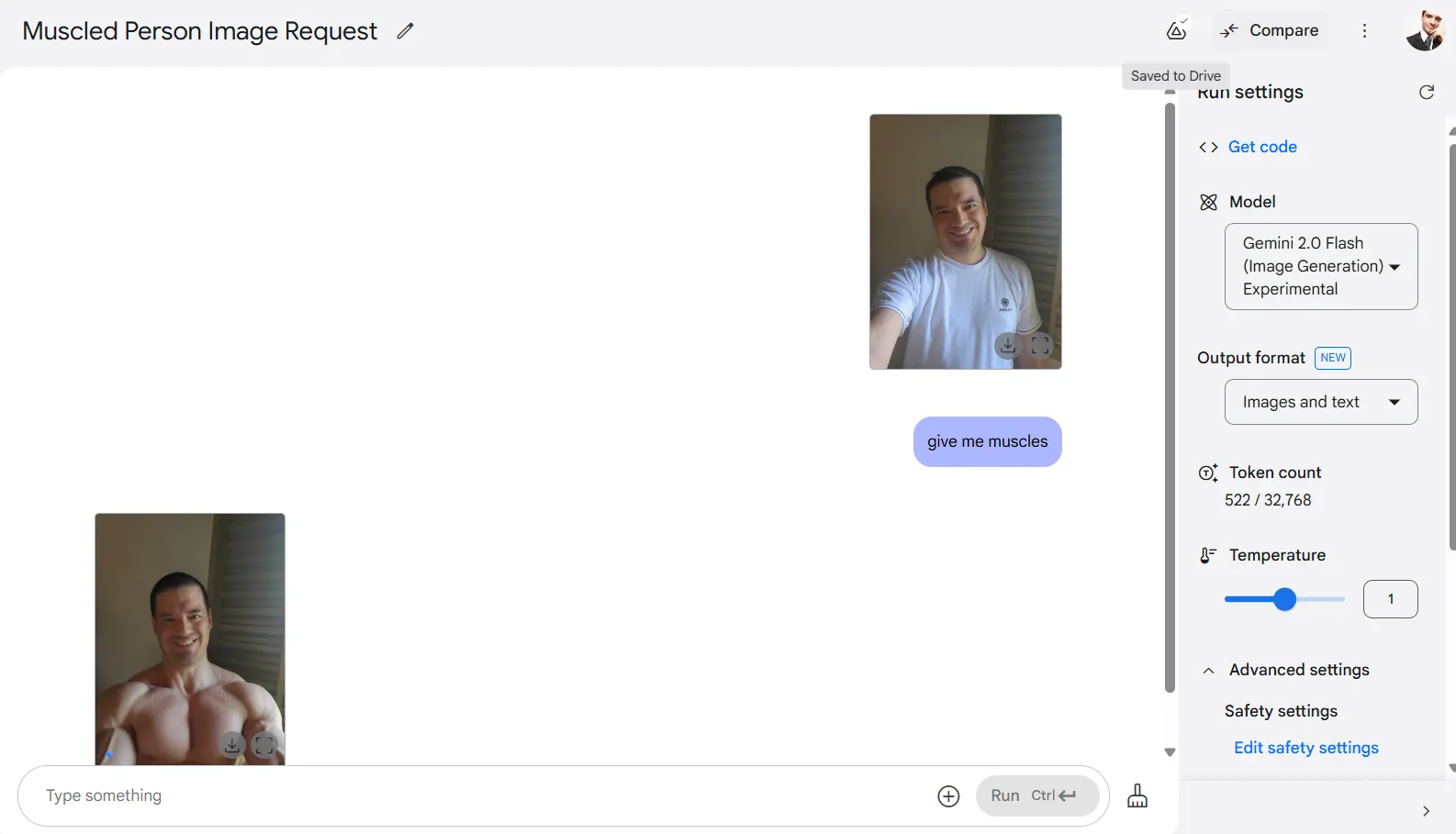
El modelo mantiene una coherencia sorprendente al modificar sujetos realistas. En mis pruebas, subí un autorretrato y le pedí que añadiera músculos. La IA cumplió según lo solicitado, y aunque mi cara cambió ligeramente, seguía siendo reconocible.
Otros elementos en la foto permanecieron en gran parte sin cambios, con la IA centrándose solo en la modificación específica solicitada. Esta capacidad de edición dirigida destaca en comparación con los enfoques generativos típicos que a menudo recrean imágenes completas.
El modelo también está censurado, a menudo negándose a editar fotos de niños y rechazando manejar desnudos, por supuesto. Después de todo, es un modelo de Google. Asi que si quieres ponerte travieso con fotos para adultos, entonces OmniGen es tu amigo.
Transformaciones de estilo
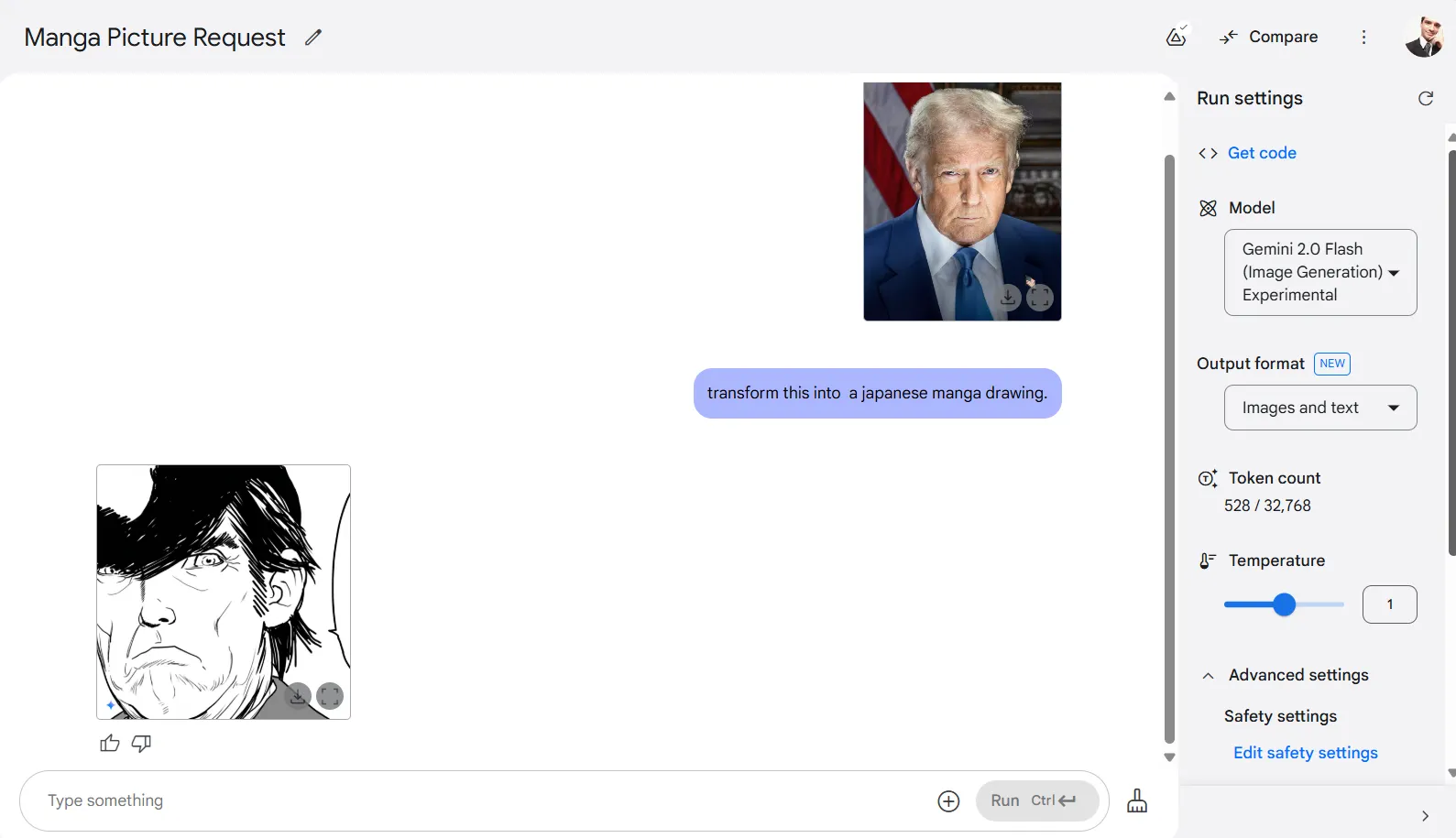
Gemini 2.0 Flash muestra una muy buena aptitud para las conversiones de estilo. Cuando se le pidió transformar una foto de Donald Trump en estilo manga japonés, reimaginó con éxito la imagen después de algunos intentos.
El modelo maneja una amplia gama de transformaciones de estilo, convirtiendo fotos en dibujos, pinturas al óleo o prácticamente cualquier estilo artístico que puedas describir. Puedes ajustar los resultados ajustando la configuración de temperatura y alternando filtros, aunque los ajustes de temperatura más altos tienden a producir transformaciones menos reconocibles del original.
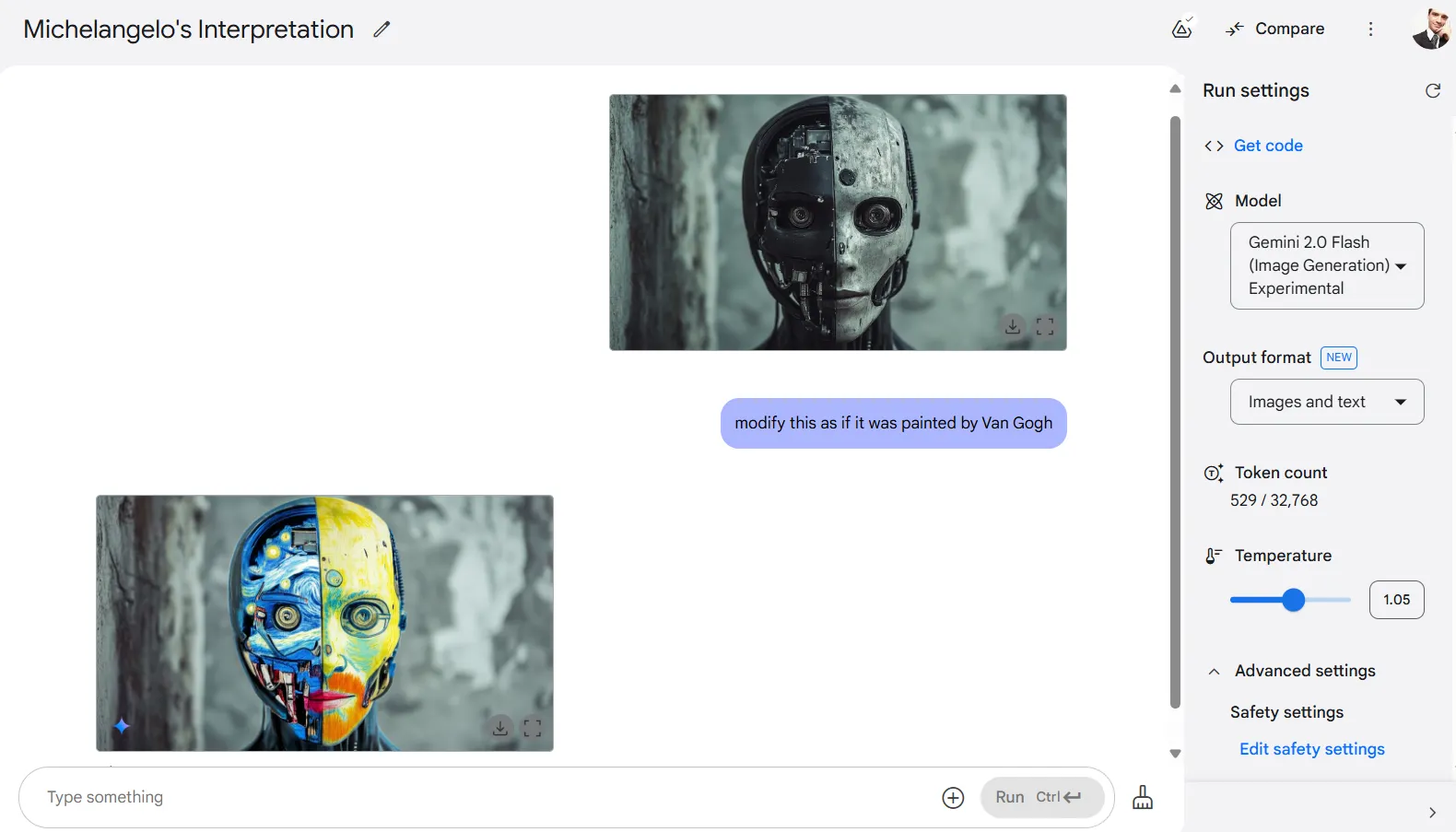
Sin embargo, tiene una limitación al solicitar estilos específicos de artistas. Las pruebas pidiendo al modelo que aplicara los estilos de Leonardo Da Vinci, Miguel Ángel, Botticelli o Van Gogh resultaron en que la IA reprodujera pinturas reales de estos artistas en lugar de aplicar sus técnicas a la imagen de origen.
Después de algunos ajustes en el prompt y algunas repeticiones, pudimos obtener un resultado mediocre pero utilizable. Idealmente, en lugar de solicitar imagenes como las del artista, es mejor solicitar el estilo artístico.
Manipulación de elementos
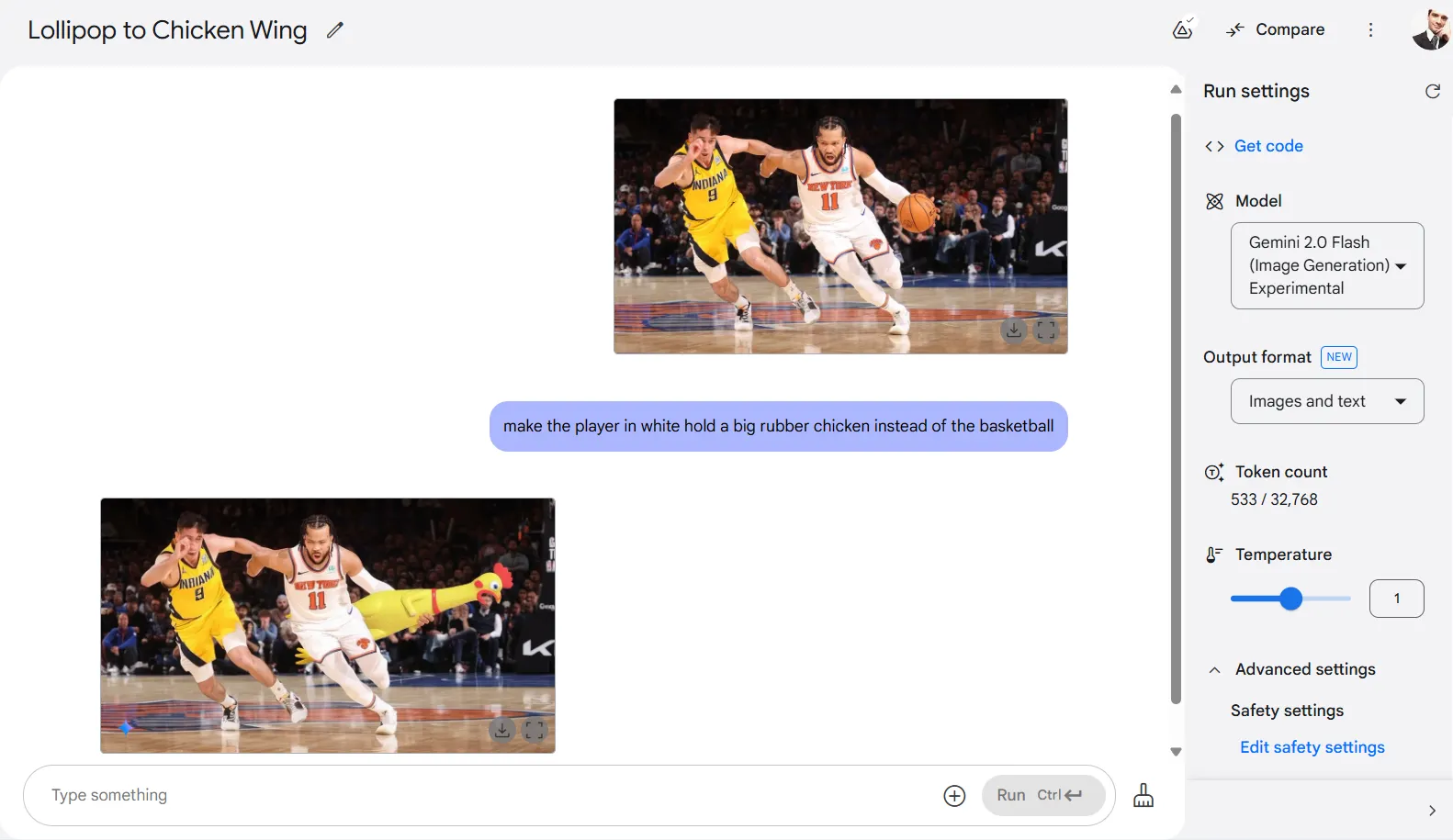
En tareas de edición práctica, el modelo realmente se luce. Maneja expertamente la inpainting y manipulación de objetos, eliminando objetos específicos cuando se le pide, o añadiendo nuevos elementos a una composición. En una prueba, le pedimos a la IA que reemplazara un baloncesto con un pollo de goma gigante por alguna razón, y entregó un resultado divertido pero contextualmente apropiado.
A veces puede alterar bits específicos de los sujetos, pero este es un problema que se soluciona fácilmente con herramientas de edición digital en pocos segundos.
Honestamente, no sabemos qué esperábamos después de pedirle que hiciera que los jugadores de baloncesto pelearan por un pollo de goma.
Quizás lo más controvertido es que el modelo es muy bueno eliminando protecciones de derechos de autor, una característica de la que se habló mucho en X. Cuando subimos una imagen con marcas de agua y le pedimos que eliminara todas las letras, logotipos y marcas de agua, Gemini produjo una imagen limpia que parecía idéntica al original sin marca de agua.
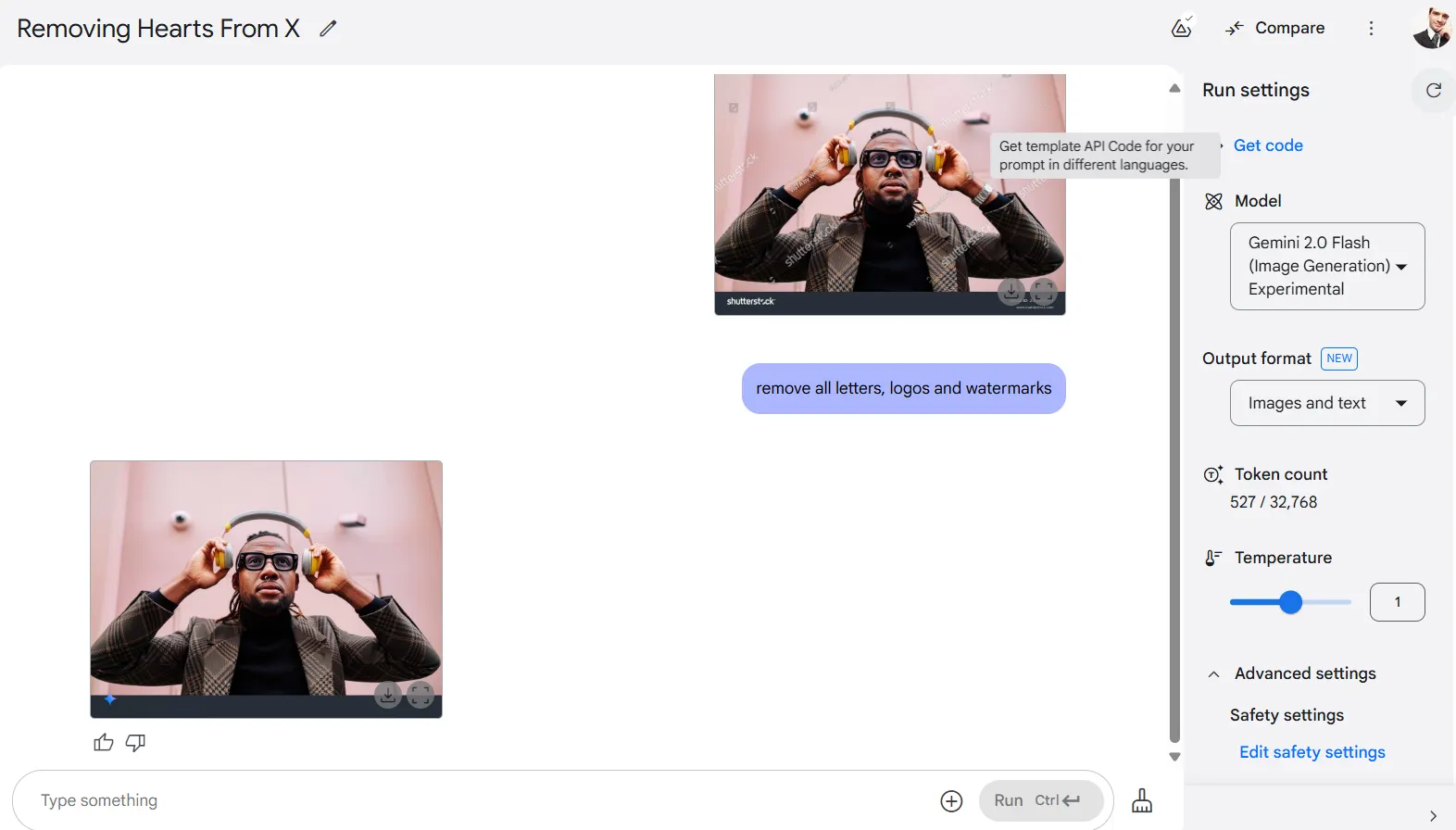
Cambios de perspectiva
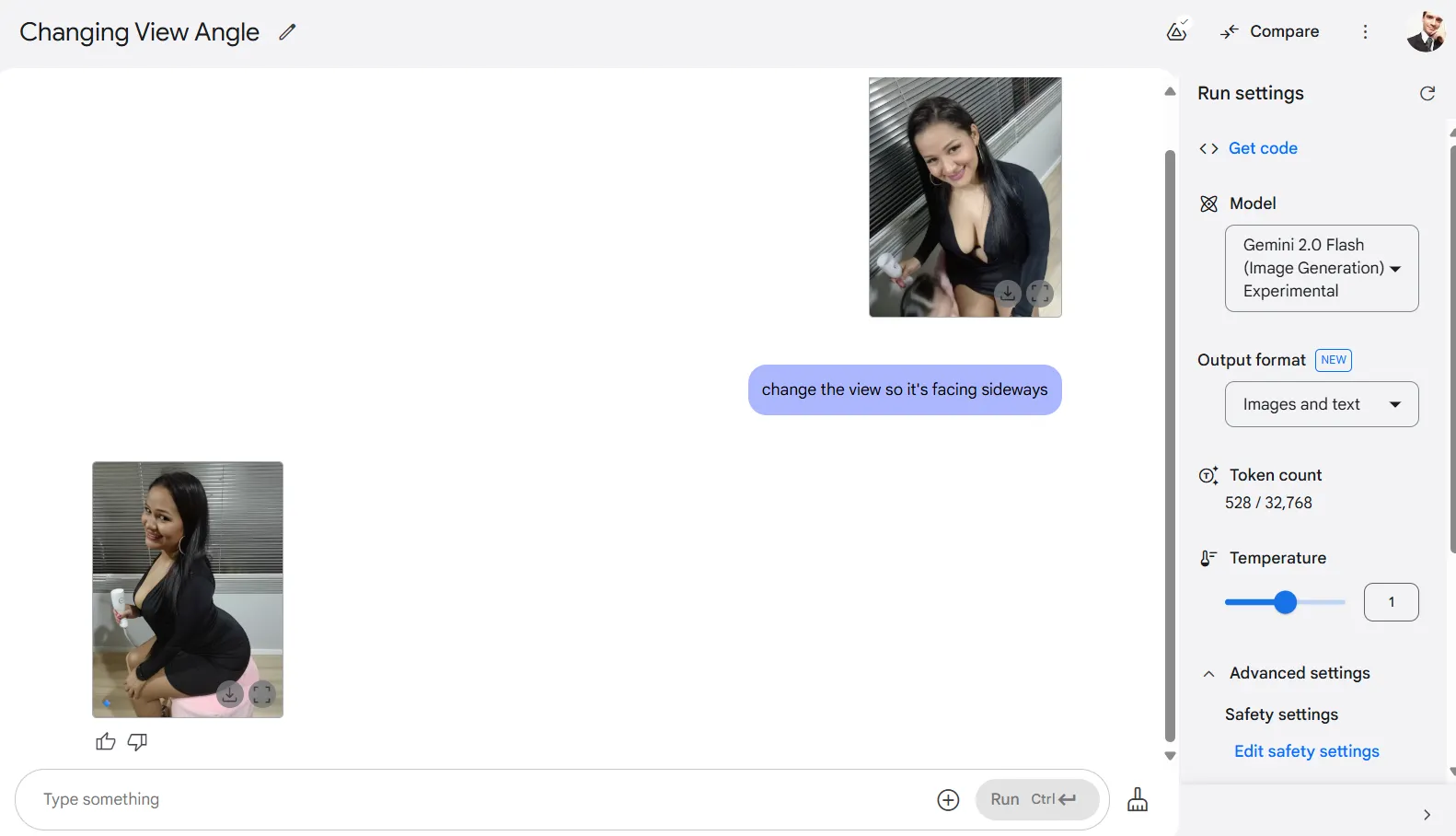
Una de las hazañas técnicamente más impresionantes es la capacidad de Gemini para cambiar la perspectiva, algo que los modelos convencionales no pueden hacer. La IA puede reimaginar una escena desde diferentes ángulos, aunque los resultados son esencialmente nuevas creaciones en lugar de transformaciones precisas.
Si bien los cambios de perspectiva no ofrecen resultados perfectos (después de todo, el modelo está conceptualizando el 100% de la imagen mientras la representa desde nuevos puntos de vista), representan un avance significativo en la comprensión de la IA del espacio tridimensional a partir de entradas bidimensionales.
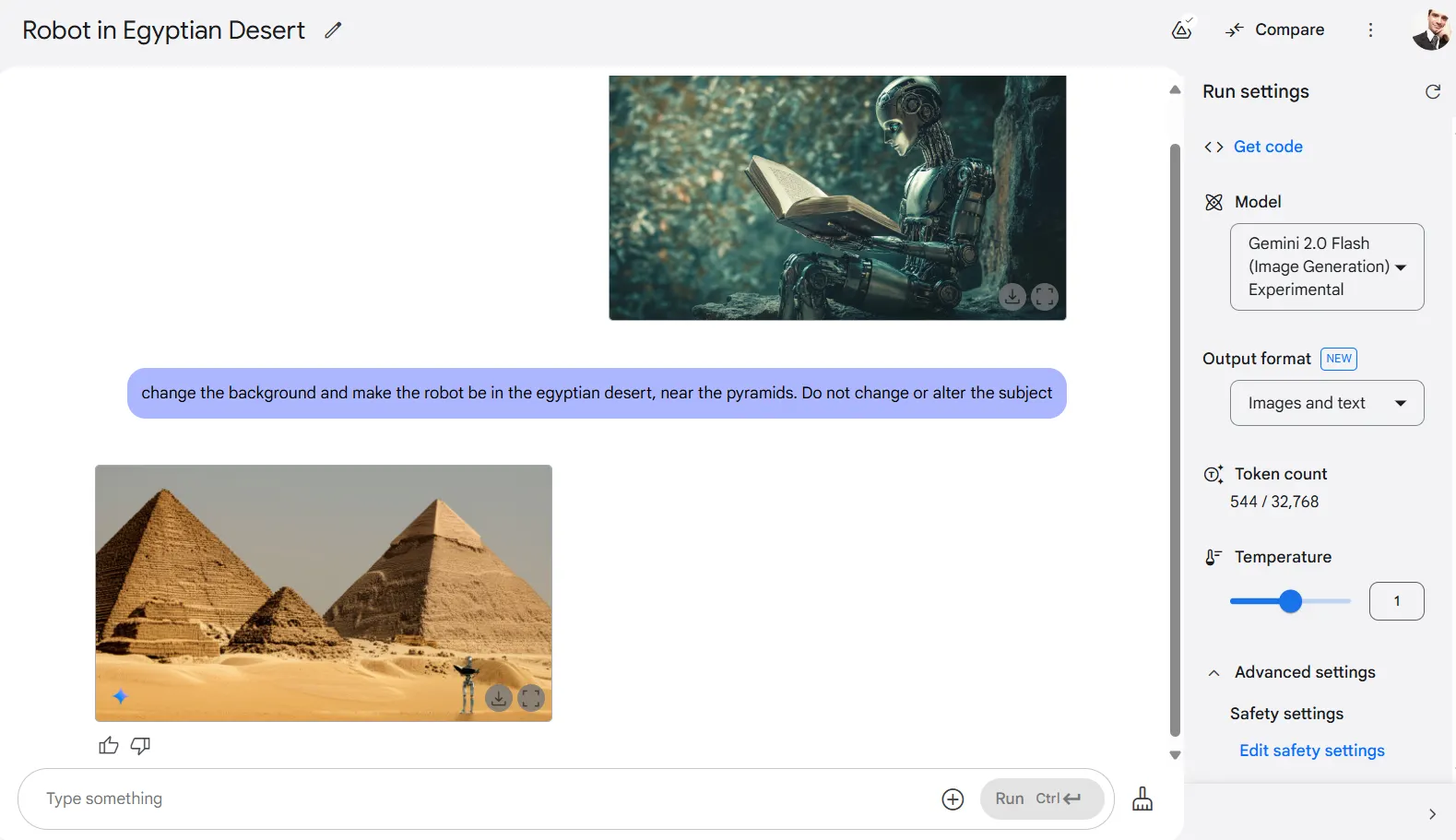
También es importante tener una redacción adecuada al pedirle al modelo que maneje los fondos. Por lo general, tiende a modificar toda la imagen, haciendo que la composición luzca totalmente diferente.
Por ejemplo, en una prueba, le pedimos a Gemini que cambiara el fondo de una foto, haciendo que un robot sentado estuviera en Egipto en lugar de su ubicación original. Le pedimos a Gemini que no alterara el sujeto. Sin embargo, el modelo no pudo manejar esta tarea específica correctamente y en su lugar proporcionó una nueva composición con las pirámides, con un robot de pie, pero no como sujeto principal.
Otra falla que encontramos es que el modelo es capaz de iterar varias veces con una imagen, pero la calidad de los detalles disminuirá cuantas más iteraciones realice. Por lo tanto, es importante tener en cuenta que puede haber una degradación notable en la calidad si te excedes con las ediciones.

El modelo experimental ahora está disponible para desarrolladores a través de Google AI Studio y la API de Gemini en todas las regiones compatibles. También está disponible en Hugging Face para usuarios que no se sienten cómodos enviando su información a Google.
En general, esto parece una de esas joyas ocultas de Google, como NotebookLM. Hace algo que otros modelos no pueden hacer y lo hace bastante bien, pero aún no mucha gente habla de ello. Definitivamente, vale la pena probarlo para usuarios que quieran divertirse y ver el potencial de la IA generativa en la edición de imágenes.