

En Resumen
- DeepSeek lanzó Janus Pro, un modelo multimodal de IA de código abierto que supera a DALL-E 3 en benchmarks clave.
- Janus Pro 7B destaca en comprensión visual y generación de imágenes, pero no supera a modelos especializados.
- Su éxito dependerá de futuras mejoras y adopción dentro de la comunidad de IA generativa.
DeepSeek, la startup de IA china que recientemente revolucionó las suposiciones de la industria sobre los costos de desarrollo del sector, ha lanzado una nueva familia de modelos de IA multimodales de código abierto que, según los informes, superan a DALL-E 3 de OpenAI en indicadores clave.
Denominado Janus Pro, el modelo varía desde 1.000 millones (extremadamente pequeño) hasta 7.000 millones de parámetros (cerca del tamaño de SD 3.5L) y está disponible para descarga inmediata en el centro de machine learning y ciencia de datos Huggingface.
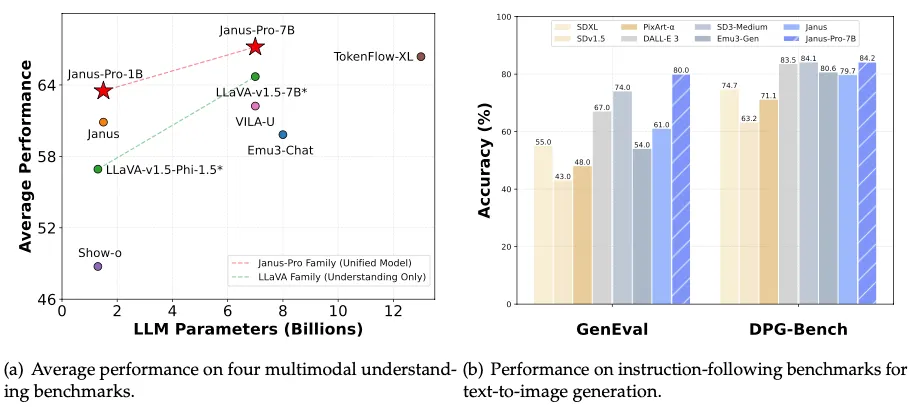
La versión más grande, Janus Pro 7B, supera no solo a DALL-E 3 de OpenAI sino también a otros modelos líderes como PixArt-alpha, Emu3-Gen y SDXL en los benchmarks de la industria GenEval y DPG-Bench, según la información compartida por DeepSeek AI.
Su lanzamiento llega solo días después de que DeepSeek fuera noticia por su modelo de lenguaje R1, que igualó las capacidades de GPT-4 mientras costaba solo $5 millones desarrollarlo, lo que generó un acalorado debate sobre el estado actual de la industria de IA.
La startup china también ha desencadenado preocupaciones en todo el sector, ya que podría desplazar a los actuales líderes y afectar la trayectoria de crecimiento del principal fabricante de chips Nvidia, que sufrió la mayor pérdida de capitalización de mercado en un solo día en la historia el lunes.
El modelo Janus Pro de DeepSeek utiliza lo que la compañía llama un "nuevo marco autorregresivo" que desacopla la codificación visual en rutas separadas mientras mantiene una arquitectura transformer unificada.
Este diseño permite que el modelo tanto analice como genere imágenes en resolución 768x768.
"Janus Pro supera a los modelos unificados anteriores e iguala o excede el rendimiento de los modelos específicos para tareas", afirmó DeepSeek en su documentación de lanzamiento. "La simplicidad, alta flexibilidad y efectividad de Janus Pro lo convierten en un fuerte candidato para los modelos multimodales unificados de próxima generación".
A diferencia de DeepSeek R1, la compañía no publicó un documento técnico completo sobre el modelo, pero sí publicó su documentación técnica y lo puso disponible para descarga inmediata sin costo alguno, continuando su práctica de código abierto que contrasta marcadamente con el enfoque cerrado y propietario de los gigantes tecnológicos estadounidenses.
Entonces, ¿cuál es nuestro veredicto? Bueno, el modelo es altamente versátil.
Sin embargo, no esperes que reemplace ninguno de los modelos más especializados que te gustan. Puede generar texto, analizar imágenes y generar fotos, pero cuando compite contra modelos que solo hacen bien una de esas cosas, en el mejor de los casos, solo está a la par.
Probando el modelo
Ten en cuenta que no hay una forma inmediata de usar interfaces de usuario tradicionales para ejecutarlo: Comfy, A1111, Focus y Draw Things no son compatibles con él en este momento. Esto significa que es un poco práctico ejecutar el modelo localmente y requiere usar comandos de texto en una terminal.
Sin embargo, algunos usuarios de Huggingface han creado espacios para probar el modelo. El espacio oficial de DeepSeek no está disponible, por lo que recomendamos usar el espacio gratuito de NeuroSenko para probar Janus 7b.
Ten cuidado con lo que haces, ya que algunos títulos pueden ser engañosos. Por ejemplo, el espacio ejecutado por AP123 dice que ejecuta Janus Pro 7b, pero en su lugar ejecuta Janus Pro 1.5b, lo que puede hacer que pierdas mucho tiempo libre probando el modelo y obteniendo malos resultados. Confía en nosotros: lo sabemos porque nos pasó.
Comprensión visual
El modelo es bueno en comprensión visual y puede describir con precisión los elementos en una foto.
Mostró una buena conciencia espacial y la relación entre diferentes objetos.
También es más preciso que LlaVa —el modelo de visión de código abierto más popular— siendo capaz de proporcionar descripciones más precisas de escenas e interactuar con el usuario basándose en prompts visuales.
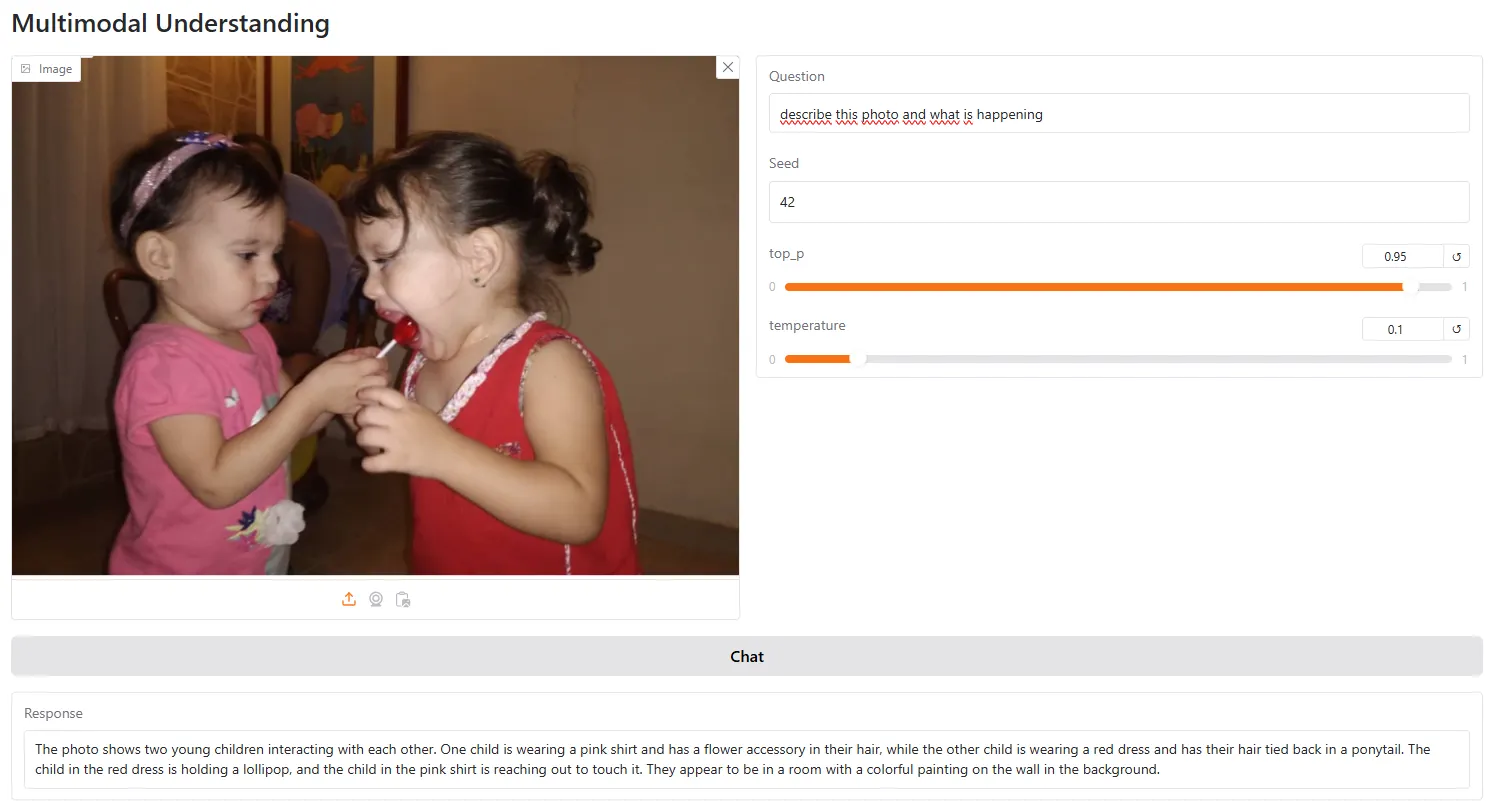
Sin embargo, aún no es mejor que GPT Vision, especialmente para tareas que requieren lógica o algún análisis más allá de lo que obviamente se muestra en la foto. Por ejemplo, le pedimos al modelo que analizara esta foto y explicara su mensaje.

El modelo respondió: "La imagen parece ser una caricatura humorística que representa una escena donde una mujer está lamiendo el extremo de una larga lengua roja que está unida a un niño".
Terminó su análisis diciendo que "el tono general de la imagen parece ser ligero y juguetón, posiblemente sugiriendo un escenario donde la mujer está participando en un acto travieso o burlón".

En estas situaciones donde se requiere algo de razonamiento más allá de una simple descripción, el modelo falla la mayoría de las veces.
Por otro lado, ChatGPT, por ejemplo, entendió realmente el significado detrás de la imagen: "Esta metáfora sugiere que las actitudes, palabras o valores de la madre están influyendo directamente en las acciones del niño, particularmente de manera negativa como el acoso o la discriminación", concluyó, con precisión, debemos agregar.

Una liga aparte
La generación de imágenes parece robusta y relativamente precisa, aunque requiere un prompt cuidadoso para lograr buenos resultados.
DeepSeek afirma que Janus Pro supera a SD 1.5, SDXL y Pixart Alpha, pero es importante enfatizar que esta debe ser una comparación contra los modelos base, no ajustados.
En otras palabras, la comparación justa es entre las peores versiones de los modelos actualmente disponibles, ya que, posiblemente, nadie usa SD 1.5 base para generar arte cuando hay cientos de ajustes finos capaces de lograr resultados que pueden competir incluso contra modelos de última generación como Flux o Stable Diffusion 3.5.
Entonces, las generaciones no son para nada impresionantes en términos de calidad, pero parecen mejores que lo que SD1.5 o SDXL solían producir cuando se lanzaron.
Por ejemplo, aquí hay una comparación cara a cara de las imágenes generadas por Janus y SDXL para el prompt: Un zorro bebé lindo y adorable con grandes ojos marrones, hojas de otoño en el fondo encantador, inmortal, melena esponjosa y brillante, Pétalos, hada, altamente detallado, fotorrealista, cinematográfico, colores naturales.

Janus supera a SDXL en la comprensión del concepto central: pudo generar un zorro bebé en lugar de un zorro maduro, como en el caso de SDXL.
También entendió mejor el estilo fotorrealista, y los otros elementos (esponjoso, cinematográfico) también estaban presentes.
Dicho esto, SDXL generó una imagen más nítida a pesar de no apegarse al prompt. La calidad general es mejor, los ojos son realistas y los detalles son más fáciles de ver.
Este patrón fue consistente en otras generaciones: buena comprensión del prompt, pero pobre ejecución, con imágenes borrosas que se sienten desactualizadas considerando lo buenos que son los generadores de imágenes de última generación actuales.
Sin embargo, es importante notar que Janus es un LLM multimodal capaz de generar conversaciones de texto, analizar imágenes y también generarlas. Flux, SDXL y los otros modelos no están construidos para esas tareas.
Entonces, Janus es mucho más versátil en su núcleo; simplemente no es excelente en nada cuando se compara con modelos especializados que sobresalen en una tarea específica.
Al ser de código abierto, el futuro de Janus como líder entre los entusiastas de la IA generativa dependerá de una serie de actualizaciones que busquen mejorar esos puntos.
Editado por Josh Quittner y Sebastian Sinclair