

En Resumen
- La escena del arte de IA se está calentando con Sana, un nuevo modelo de Nvidia que ejecuta generación de imágenes 4K de alta calidad en hardware de grado consumidor.
- Sana utiliza un "autocodificador de compresión profunda" que comprime los datos de imagen a 1/32 de su tamaño original, manteniendo todos los detalles intactos.
- El modelo combina esto con el LLM Gemma 2 para entender los prompts, creando un sistema que rinde muy por encima de su categoría en hardware modesto.
La escena del arte de IA se está calentando. Sana, un nuevo modelo de IA introducido por Nvidia, ejecuta generación de imágenes 4K de alta calidad en hardware de grado consumidor, gracias a una mezcla inteligente de técnicas que difieren un poco de la forma en que funcionan los generadores de imágenes tradicionales.
La velocidad de Sana proviene de lo que Nvidia llama un "autocodificador de compresión profunda" que comprime los datos de imagen a 1/32 de su tamaño original, mientras mantiene todos los detalles intactos. El modelo combina esto con el LLM Gemma 2 para entender los prompts, creando un sistema que rinde muy por encima de su categoría en hardware modesto.
Si el producto final es tan bueno como la demostración pública, Sana promete ser un generador de imágenes completamente nuevo construido para funcionar en sistemas menos exigentes, lo que será una gran ventaja para Nvidia mientras intenta llegar a más usuarios.
"Sana-0.6B es muy competitivo con el modelo de difusión gigante moderno (por ejemplo, Flux-12B), siendo 20 veces más pequeño y más de 100 veces más rápido en rendimiento medido", escribió el equipo de Nvidia en el documento de investigación de Sana, "Además, Sana-0.6B puede ser implementado en una GPU de laptop de 16GB, tomando menos de 1 segundo para generar una imagen de resolución 1024×1024."
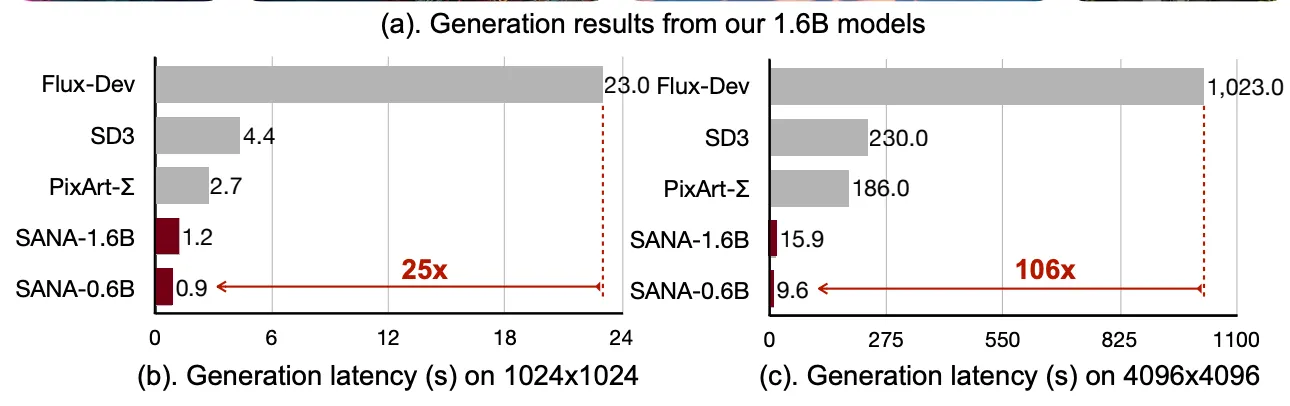
Sí, leíste bien: Sana es un modelo de 0.6 mil millones de parámetros que compite contra modelos 20 veces su tamaño, mientras genera imágenes 4 veces más grandes, en una fracción del tiempo. Si eso suena demasiado bueno para ser verdad, puedes probarlo tú mismo en una interfaz especial configurada por el MIT.
El momento de Nvidia no podría ser más preciso, con modelos como el recientemente introducido Stable Diffusion 3.5, el querido Flux, y el nuevo Auraflow ya compitiendo por la atención. Nvidia planea liberar su código como código abierto pronto, un movimiento que podría solidificar su posición en el mundo del arte de IA, mientras impulsa las ventas de sus GPUs y herramientas de software, debemos añadir.
La Santa Trinidad que hace a Sana tan bueno
Sana es básicamente una reimaginación de la forma en que funcionan los generadores de imágenes tradicionales. Pero hay tres elementos clave que hacen que este modelo sea tan eficiente.
Primero, está el autocodificador de compresión profunda de Sana, que reduce los datos de imagen a apenas un 3% de su tamaño original. Los investigadores dicen que esta compresión usa una técnica especializada que mantiene los detalles intrincados mientras reduce dramáticamente la potencia de procesamiento necesaria.
Puedes pensar en esto como un sustituto optimizado del Codificador Automático Variable que está implementado en Flux o Stable Diffusion. El proceso de codificación/decodificación en Sana está construido para ser más rápido y eficiente.
Estos autocodificadores básicamente traducen las representaciones latentes (lo que la IA entiende y genera) en imágenes.
En segundo lugar, Nvidia renovó la forma en que su modelo maneja los prompts, que es mediante la codificación y decodificación de texto. La mayoría de las herramientas de arte de IA usan codificadores de texto como T5 o CLIP para básicamente traducir el prompt del usuario en algo que una IA puede entender—representaciones latentes del texto. Pero Nvidia eligió usar el LLM Gemma 2 de Google.
Este modelo hace básicamente lo mismo, pero se mantiene ligero mientras aún capta matices en los prompts del usuario. Escribe "atardecer sobre montañas brumosas con ruinas antiguas", y entiende la imagen—literalmente—sin maximizar la memoria de tu computadora.
Pero el Transformador de Difusión Lineal es probablemente la principal desviación de los modelos tradicionales. Mientras otras herramientas de IA usan operaciones matemáticas complejas que ralentizan el procesamiento, el LDT de Sana elimina los cálculos innecesarios. ¿El resultado? Generación de imágenes ultrarrápida sin pérdida de calidad. Piensa en ello como encontrar un atajo a través de un laberinto—mismo destino, pero una ruta mucho más rápida.
Esta podría ser una alternativa a la arquitectura UNet que los artistas de IA conocen de modelos como Flux o Stable Diffusion. El UNet es lo que transforma el ruido (algo que no tiene sentido) en una imagen clara aplicando técnicas de eliminación de ruido, refinando gradualmente la imagen a través de varios pasos—el proceso que más recursos consume en los generadores de imágenes.
Entonces, el LDT en Sana esencialmente realiza las mismas tareas de "des-ruido" y transformación que el UNet en Stable Diffusion pero con un enfoque más optimizado. Esto hace del LDT un factor crucial para lograr alta eficiencia y velocidad en la generación de imágenes de Sana, mientras que UNet sigue siendo central para la funcionalidad de Stable Diffusion, aunque con mayores demandas computacionales.
Pruebas Básicas
Como el modelo no está públicamente liberado, no compartiremos una revisión detallada. Pero algunos de los resultados que obtuvimos del sitio de demostración del modelo fueron bastante buenos.
Sana demostró ser bastante rápido. Como comparación, fue capaz de generar imágenes 4K, renderizando 30 pasos en menos de 10 segundos. Eso es incluso más rápido que el tiempo que toma Flux Schnell para generar una imagen similar en 4 pasos con tamaños de 1080p.
Aquí hay algunos resultados, usando los mismos prompts que usamos para comparar otros generadores de imágenes:
Prompt 1: “Ilustración a mano de una araña gigante persiguiendo a una mujer en la jungla, extremadamente aterradora, angustiosa, escenario oscuro y espeluznante, horror, con influencia de fotografía analógica, boceto.”


Prompt 2: Una foto en blanco y negro de una mujer con cabello largo y liso, vistiendo un atuendo completamente negro que acentúa sus curvas, sentada en el suelo frente a un sofá moderno. Está posando con confianza para la cámara, mostrando sus piernas esbeltas mientras se agacha. El fondo presenta un diseño minimalista, enfatizando su elegante pose contra el fuerte contraste entre las paredes de color gris claro y la vestimenta oscura. Su expresión irradia confianza y sofisticación. Tomada por Peter Lindbergh utilizando la lente Hasselblad X2D 105mm con una configuración de apertura f/4. ISO 63. La gradación de color profesional realza el atractivo visual.


```
Prompt 3: Un lagarto vistiendo un traje


Prompt 4: Una mujer hermosa acostada en el césped


Prompt 5: “Un perro parado en la parte superior de un televisor que muestra la palabra ‘Decrypt’ en la pantalla. A la izquierda hay una mujer en traje de negocios sosteniendo una moneda, a la derecha hay un robot parado en la parte superior de una caja de primeros auxilios. El escenario general es surrealista.”


El modelo también está sin censura, con una comprensión adecuada de la anatomía masculina y femenina. También será más fácil de ajustar una vez que sea liberado. Pero considerando la cantidad importante de cambios arquitectónicos, está por verse qué tan desafiante será para los desarrolladores de modelos entender sus complejidades y liberar versiones personalizadas de Sana.
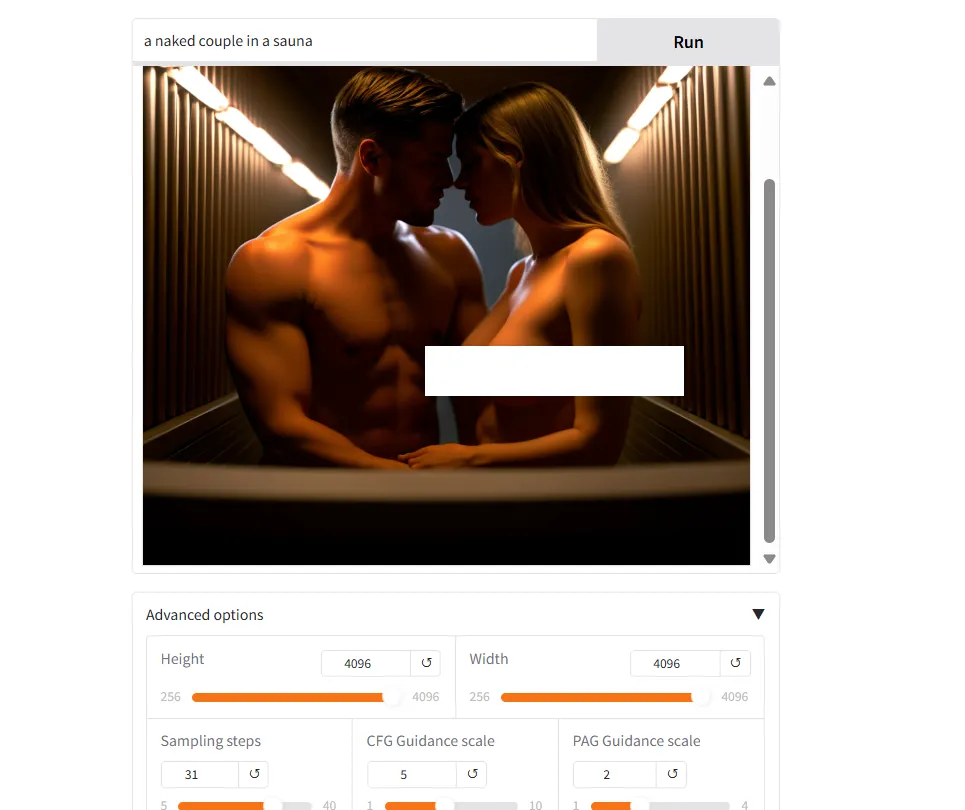
Basado en estos resultados tempranos, el modelo base, aún en vista previa, parece bueno con el realismo mientras es versátil para otros tipos de arte. Es bueno en términos de consciencia espacial pero su principal defecto es su falta de generación de texto adecuada y falta de detalle bajo algunas condiciones.
Las afirmaciones de velocidad son bastante impresionantes, y la capacidad de generar 4096x4096—que es técnicamente más alto que 4k—es algo notable, considerando que tales tamaños solo pueden lograrse apropiadamente hoy con técnicas de upscaling.
El hecho de que será código abierto también es un punto muy positivo, así que pronto podríamos estar revisando modelos y ajustes finos capaces de generar imágenes de ultra alta definición sin poner demasiada presión en el hardware de consumo.
Los pesos de Sana se publicarán en el Github oficial del proyecto.