

En Resumen
- Los investigadores de DeepMind de Google han presentado un nuevo método para acelerar el entrenamiento de la IA, reduciendo significativamente los recursos computacionales y el tiempo necesarios.
- JEST funciona seleccionando lotes complementarios de datos para maximizar la capacidad de aprendizaje del modelo de IA, lo que resulta en una mejora significativa en la velocidad y eficiencia del entrenamiento en comparación con los métodos tradicionales.
- Este enfoque más eficiente podría hacer que el desarrollo de la IA sea más rápido y económico, lo que a su vez podría reducir el consumo de energía y el impacto ambiental de la industria de la inteligencia artificial.
Los investigadores de DeepMind de Google han presentado un nuevo método para acelerar el entrenamiento de la IA, reduciendo significativamente los recursos computacionales y el tiempo necesarios para realizar el trabajo. Este nuevo enfoque del proceso que normalmente es intensivo en energía, podría hacer que el desarrollo de la IA sea más rápido y económico, según un reciente artículo de investigación, y eso podría ser una buena noticia para el medio ambiente.
"Nuestro enfoque—aprendizaje contrastivo multimodal con selección conjunta de ejemplos (JEST)—supera a los modelos de vanguardia con hasta 13 veces menos iteraciones y 10 veces menos computación," dijo el estudio.
"Nuestro enfoque, que consiste en el aprendizaje contrastivo multimodal con selección conjunta de ejemplos (JEST), supera a los modelos de vanguardia utilizando hasta 13 veces menos iteraciones y 10 veces menos recursos computacionales", afirmó el estudio
La industria de la inteligencia artificial es conocida por su alto consumo de energía. Sistemas de IA a gran escala como ChatGPT requieren una gran potencia de procesamiento, lo que a su vez demanda mucha energía y agua para enfriar estos sistemas. Por ejemplo, el consumo de agua de Microsoft, aumentó en un 34% de 2021 a 2022 debido a las mayores demandas de cómputo de IA, y se acusa a ChatGPT de consumir casi medio litro de agua cada 5 a 50 indicaciones.
La Agencia Internacional y (IEA) proyecta que el consumo de electricidad de los centros de datos se duplicará de 2022 a 2026—estableciendo comparaciones entre las demandas de energía de la inteligencia artificial y el perfil energético, a menudo criticado, de la industria minera de criptomonedas.
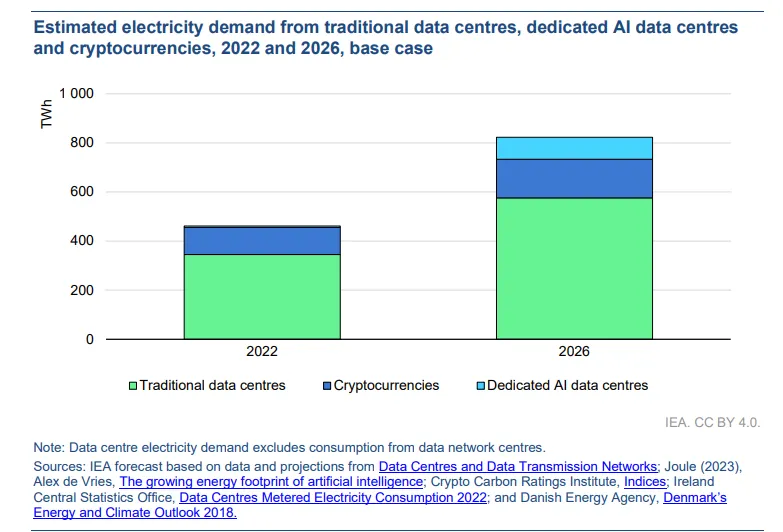
Sin embargo, enfoques como JEST podrían ofrecer una solución. Al optimizar la selección de datos para el entrenamiento de IA, Google dijo que JEST puede reducir significativamente el número de iteraciones y la potencia computacional necesaria, lo que podría disminuir el consumo energético total. Este método se alinea con los esfuerzos para mejorar la eficiencia de las tecnologías de IA y mitigar su impacto ambiental.
Si la técnica resulta efectiva a gran escala, los entrenadores de IA solo necesitarán una fracción de la potencia utilizada para entrenar sus modelos. Esto significa que podrían crear herramientas de IA más potentes con los mismos recursos que utilizan actualmente, o consumir menos recursos para desarrollar modelos más nuevos.
¿Cómo funciona JEST?
JEST opera seleccionando lotes complementarios de datos para maximizar la capacidad de aprendizaje del modelo de IA. A diferencia de los métodos tradicionales que seleccionan ejemplos individuales, este algoritmo considera la composición de todo el conjunto.
Por ejemplo, imagina que estás aprendiendo varios idiomas. En lugar de aprender inglés, alemán y noruego por separado, quizás en orden de dificultad, puede resultar más efectivo estudiarlos juntos, de manera que el conocimiento de uno apoye el aprendizaje de otro.
Google tomó un enfoque similar, y resultó exitoso.
"Demostramos que seleccionar conjuntamente lotes de datos es más efectivo para el aprendizaje que seleccionar ejemplos de forma independiente", afirmaron los investigadores en su artículo.
Para hacerlo, los investigadores de Google utilizaron "aprendizaje contrastivo multimodal", donde el proceso JEST identificó dependencias entre los puntos de datos. Este método mejora la velocidad y eficiencia del entrenamiento de IA, al tiempo que requiere mucha menos potencia de cálculo.
Una clave fundamental para el enfoque fue el uso de modelos de referencia preentrenados para orientar el proceso de selección de datos, según indicó Google. Gracias a esta técnica, el modelo pudo concentrarse en conjuntos de datos de alta calidad y cuidadosamente seleccionados, lo que permitió optimizar aún más la eficiencia del entrenamiento.
"La calidad de un lote también es una función de su composición, además de la calidad sumada de sus puntos de datos considerados de forma independiente", explicó el documento.
Los experimentos del estudio mostraron sólidas mejoras de rendimiento en varios puntos de referencia. Por ejemplo, el entrenamiento en el conjunto de datos WebLI común utilizando JEST mostró mejoras notables en la velocidad de aprendizaje y la eficiencia de recursos.
Los investigadores también descubrieron que el algoritmo encontró rápidamente sublotes altamente aprendibles, acelerando el proceso de entrenamiento al centrarse en piezas específicas de datos que "coinciden" entre sí. Esta técnica, conocida como "arranque de calidad de datos", valora la calidad sobre la cantidad y ha demostrado ser mejor para el entrenamiento de IA.
"Un modelo de referencia entrenado en un pequeño conjunto de datos curados puede guiar efectivamente la curación de un conjunto de datos mucho más grande, permitiendo el entrenamiento de un modelo que supera ampliamente la calidad del modelo de referencia en muchas tareas posteriores", cita el documento.
Editado por Ryan Ozawa.