

The rampant spread of deepfakes brings significant risks—from creating nude images of minors to scamming individuals with fraudulent promotions using deepfakes of celebrities—the ability to distinguish AI-generated content (AIGC) from human-created ones has never been more crucial.
Watermarking, a common anti-counterfeiting measure seen in documents and currency, is one method to identify such content, with the addition of information that helps differentiate an AI-generated image from a non-AI-generated one. But a recent research paper concluded that simple or even advanced watermarking methods may not be really enough to prevent the risks associated with releasing AI material as human-made.
The research was conducted by a team of scientists at Nanyang Technological University, S-Lab, NTU, the Chongqing University, Shannon.AI, and the Zhejiang University.
One of the authors, Li Guanlin, told Decrypt that "the watermark can help people know if the content is generated by AI or humans.” But, he added, “If the watermark on AIGC is easy to remove or forge, we can freely make others believe an artwork is generated by AI by adding a watermark, or an AIGC is created by humans by removing the watermark."
The paper explored various vulnerabilities in current watermarking methods.
"The watermarking schemes for AIGC are vulnerable to adversarial attacks, which can remove the watermark without knowing the secret key," it reads. This vulnerability poses real-world implications, especially concerning misinformation or malicious use of AI-generated content.
“If some malicious users spread AI-generated fake images of some celebrities after removing the watermarks, it is impossible to prove the images are generated by AI, as we do not have enough evidence," Li told Decrypt.
Li and his team conducted a series of experiments testing the resilience and integrity of current watermarking methods on AI-generated content. They applied various techniques to remove or forge the watermarks, assessing the ease and effectiveness of each method. The results consistently showed that the watermarks could be compromised with relative ease.
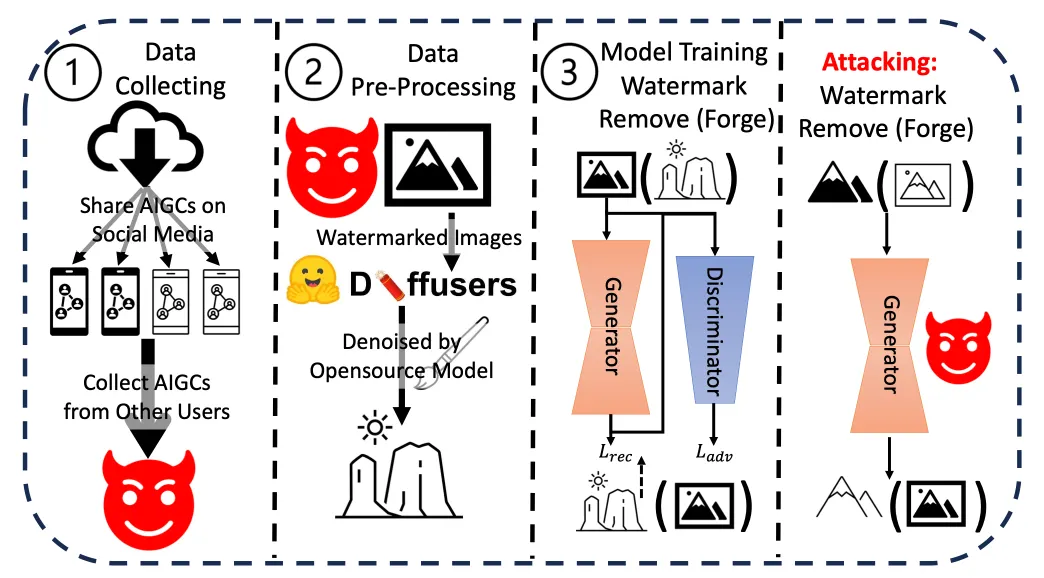
Additionally, they evaluated the potential real-world implications of these vulnerabilities, especially in scenarios involving misinformation or malicious use of AI-generated content. The cumulative findings from these experiments and analyses led them to conclude that there is a pressing need for more robust watermarking mechanisms.
While companies like OpenAI have announced that they have developed methods to detect AI-generated content with 99% accuracy, the overall challenge remains. Current identification methods, such as metadata and invisible watermarking, have their limitations.
Li suggests that "it is better to combine some cryptography methods like digital signature with the existing watermarking schemes to protect AIGC," though the exact implementation remains unclear.
Other researchers have come up with a more extreme approach. As recently reported by Decrypt, a MIT team has proposed turning images into “poison” for AI models. If a “poisoned” image is used as input in a training dataset, the final model would produce bad results because it would pick up details that are not visible by the human eye but are highly influential in the training process. It would be like a deadly watermark that kills the model it trains.
The rapid advancements in AI, as highlighted by OpenAI CEO Sam Altman, suggest a future where AI's inherent thought processes could mirror human logic and intuition. With such advancements, the need for robust security measures like watermarking becomes even more paramount.
Li believes that "watermarking and content government are essential because they actually will not influence normal users," but the conflict between creators and adversaries persists. "It will always be a cat-and-mouse game... That is why we need to keep updating our watermarking schemes."