

In the rapidly evolving landscape of AI art creation tools, Nvidia researchers have introduced an innovative new text-to-image personalization method called Perfusion. But it’s not a million-dollar super heavyweight model like its competitors. With a size of just 100KB and a 4-minute training time, Perfusion allows significant creative flexibility in portraying personalized concepts while maintaining their identity.
Perfusion was presented in a research paper created by Nvidia and the Tel-Aviv University in Israel. Despite its small size, it’s able to outperform tweaking methods used by leading AI art generators like Stability AI's Stable Diffusion v1.5, the newly released Stable Diffusion XL (SDXL), and MidJourney in terms of efficiency of specific editions.

The main new idea in Perfusion is called "Key-Locking." This works by connecting new concepts that a user wants to add, like a specific cat or chair, to a more general category during image generation. For example, the cat would be linked to the broader idea of a "feline."
This helps avoid overfitting, which is when the model gets too narrowly tuned to the exact training examples. Overfitting makes it hard for the AI to generate new creative versions of the concept.
By tying the new cat to the general notion of a feline, the model can portray the cat in many different poses, appearances, and surroundings. But it still retains the essential "catness" that makes it look like the intended cat, not just any random feline.
So in simple terms, Key-Locking lets the AI flexibly portray personalized concepts while keeping their core identity. It's like giving an artist the following directions: "Draw my cat Tom, while sleeping, playing with yarn, and sniffing flowers."
Why Nvidia Thinks Less Is More
Perfusion also enables multiple personalized concepts to be combined in a single image with natural interactions, unlike existing tools that learn concepts in isolation. Users can guide the image creation process through text prompts, merging concepts like a specific cat and chair.
Perfusion offers a remarkable feature that lets users control the balance between visual fidelity (the image) and textual alignment (the prompt) during inference by adjusting a single 100KB model. This capability allows users to easily explore the Pareto front (text similarity vs image similarity) and select the optimal trade-off that suits their specific needs, all without the necessity of retraining. It’s important to note that training a model requires some finesse. Focusing on reproducing the model too much leads to the model producing the same output over and over again and making it follow the prompt too closely with no freedom usually produces a bad result. The flexibility to tune how close the generator gets to the prompt is an important piece of customization
Other AI image generators have ways for users to fine tune output, but they’re bulky. As reference, a LoRA is a popular fine tuning method used in Stable Diffusion. It can add anywhere from dozens of megabytes to more than one gigabyte (GB) to the app. Another method, textual inversion embeddings, are lighter but less accurate. A model trained using Dreambooth, the most accurate technique right now, weighs more than 2GB.
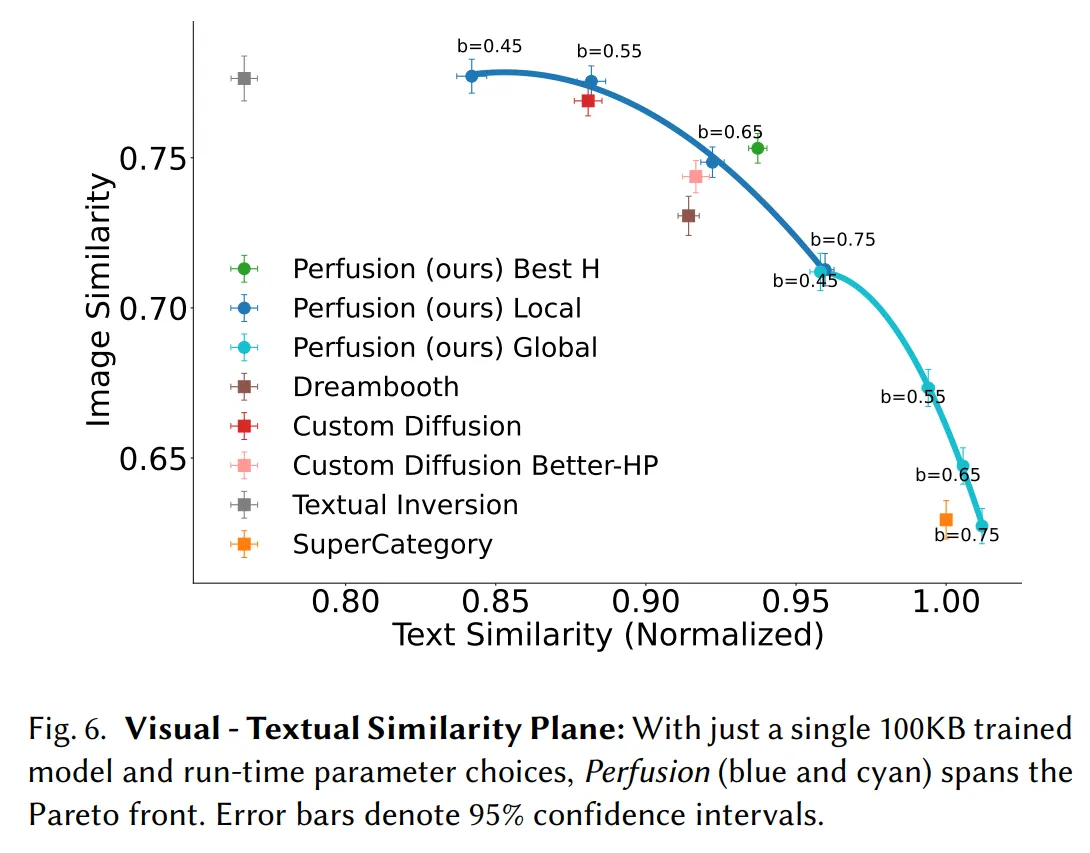
In comparison, Nvidia says Perfusion produces superior visual quality and alignment to prompts over the leading AI techniques mentioned before. The ultra-efficient size makes it possible to just update the parts that it needs to when it fine tunes how it's producing an image, compared to the multi-GB footprint of methods that fine-tune the entire model.
This research aligns with Nvidia's growing focus on AI. The company's stock has surged over 230% in 2023, as its GPUs continue to dominate training AI models. With entities like Anthropic, Google, Microsoft and Baidu pouring billions into generative AI, Nvidia's innovative Perfusion model could give it an edge.
Nvidia has only presented the research paper for now, promising to release the code soon.