

OpenAI a publié un nouveau robot d'exploration web, GPTBot, pour étendre son ensemble de données afin de former sa prochaine génération de systèmes d'IA - et la prochaine itération a apparemment un nom officiel. La société a déposé la marque «GPT-5», laissant entendre une prochaine sortie, tout en informant les éditeurs web sur la façon de garder leur contenu hors de son vaste corpus.
Le robot d'exploration web collectera des données disponibles publiquement sur les sites web, tout en évitant les contenus payants, sensibles et interdits, selon OpenAI. Toutefois, comme d'autres moteurs de recherche tels que Google, Bing et Yandex, le système est basé sur le consentement tacite - par défaut, GPTBot considérera que les informations accessibles sont utilisables. Afin d'empêcher le robot d'exploration web d'OpenAI d'ingérer un site web, son propriétaire doit ajouter une règle «disallow» à un fichier standard sur le serveur.
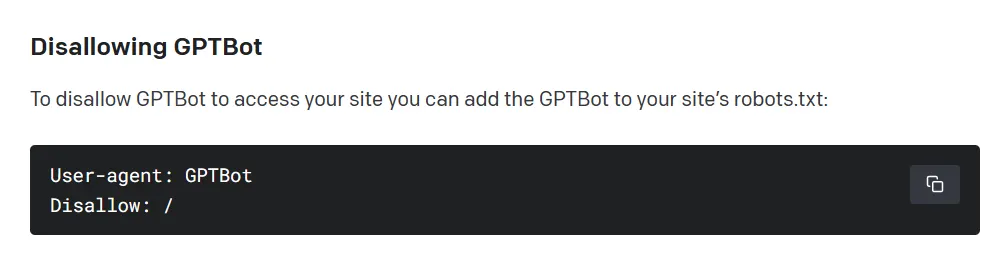
OpenAI affirme également que GPTBot analysera préventivement les données collectées pour supprimer les informations personnellement identifiables (PII) et le texte qui viole ses politiques.
Selon certains éthiciens de la technologie, cependant, l'approche de désinscription soulève encore des problèmes de consentement.
Sur Hacker News, certains utilisateurs ont justifié la décision d'OpenAI en disant qu'il doit rassembler tout ce qu'il peut si les gens veulent avoir un outil d'IA génératif performant à l'avenir. «Ils ont encore besoin de données actuelles sinon leurs modèles GPT seront bloqués à septembre 2021 pour toujours», a déclaré un utilisateur. Un autre utilisateur plus soucieux de la vie privée a argumenté que «OpenAI ne cite même pas en modération. Il crée une œuvre dérivée sans citer, ce qui l'obscurcit».
Le lancement de GPTBot fait suite à des critiques récentes à l'encontre d'OpenAI qui collectait précédemment des données sans autorisation pour entraîner des modèles de langage avancés (LLM) comme ChatGPT. Pour répondre à de telles préoccupations, l'entreprise a mis à jour ses politiques de confidentialité en avril.
Pendant ce temps, une récente demande de marque pour GPT-5 semble confirmer qu'OpenAI forme son prochain modèle pour un futur lancement. Le nouveau système impliquerait très probablement le scraping à grande échelle du web pour mettre à jour et étendre ses données d'entraînement.
Cela pourrait représenter un changement par rapport à l'accent initial d'OpenAI sur la transparence et la sécurité de l'IA, mais cela n'est pas surprenant étant donné que ChatGPT est le LLM le plus utilisé au monde, malgré un marché de plus en plus encombré et puissant. Le produit phare d'OpenAI - et de tout LLM - n'est aussi bon que la qualité des données utilisées pour le former.
OpenAI a besoin de plus de données nouvelles et récentes, et il en a besoin en grande quantité.
D'autre part, il existe un LLM open source, assemblé par le géant des médias sociaux Meta. Le géant de la technologie a mis son modèle à disposition gratuitement, tant que vous n'êtes pas un concurrent ni une entreprise trop importante. Meta n'a pas divulgué les ensembles de données qu'il a utilisés pour former son modèle, ni les informations qu'il a collectées. Cependant, cette approche permet aux utilisateurs d'affiner le modèle en utilisant leurs propres ensembles de données.
Alors qu'OpenAI s'appuie sur toutes ses données collectées pour former ses modèles et construire un écosystème rentable autour de ses outils d'IA, Meta cherche à construire une entreprise rentable autour de ses données. Ainsi, Meta l'utilise non seulement pour créer de meilleurs modèles, mais aussi le partage avec des tiers afin qu'ils puissent l'utiliser.
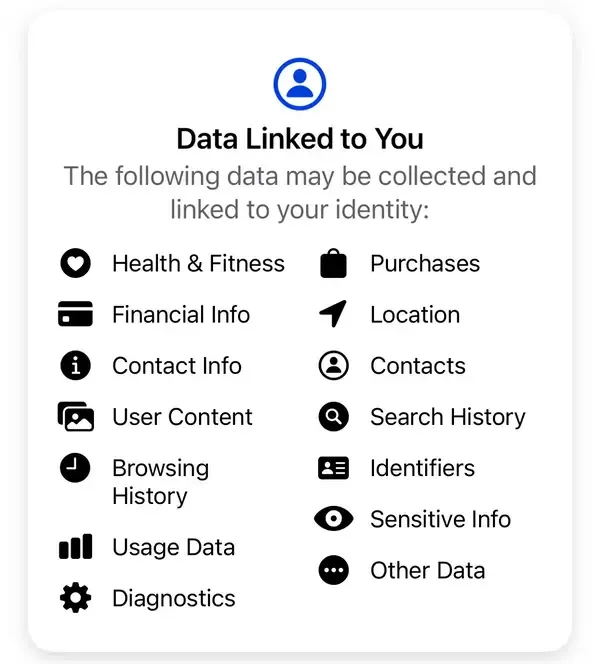
«Nous ne vendons pas vos informations. Au lieu de cela, en fonction des informations que nous avons, les annonceurs et autres partenaires nous paient pour vous montrer des publicités personnalisées», explique Meta. Selon les divulgations standard de confidentialité de Meta, certaines des données collectées par l'entreprise comprennent les achats, l'historique du navigateur, les identifiants, les informations financières, les contacts et des informations sensibles non divulguées, entre autres.
ChatGPT compte désormais plus de 1,5 milliard d'utilisateurs actifs mensuels. Et l'investissement de 10 milliards de dollars de Microsoft dans OpenAI semble judicieux, car l'intégration de ChatGPT a renforcé les capacités de Bing.
Pour l'instant, OpenAI domine le secteur de l'IA en plein essor, avec les géants de la technologie qui se précipitent pour rattraper leur retard. Le nouveau robot d'indexation web de l'entreprise pourrait encore améliorer les capacités de ses modèles. Cependant, l'extension de la collecte de données sur Internet soulève également des questions éthiques concernant les droits d'auteur et le consentement.
À mesure que les systèmes d'IA deviennent plus sophistiqués, équilibrer la transparence, l'éthique et les capacités restera un exercice d'équilibre complexe.