





Google stunned the tech world on Wednesday with the debut of Gemini, its consumer- and business-facing suite of multimodal artificial intelligence tools.
Among the tech giants pushing aggressively into AI, search titan Google seemed to be swimming in the middle space, as Microsoft-backed OpenAI pushed ChatGPT to Turbo and Vision and Anthropic upgraded Claude. As of today, Google bolts out of the gate with three versions of Gemini—Nano, Pro, and Ultra—which seamlessly understand and integrate text, images, audio and video.
Gemini appears poised to outperform top-of-the line AI models from OpenAI, which just released a laundry list of new capabilities but soon after got buried in corporate intrigue.
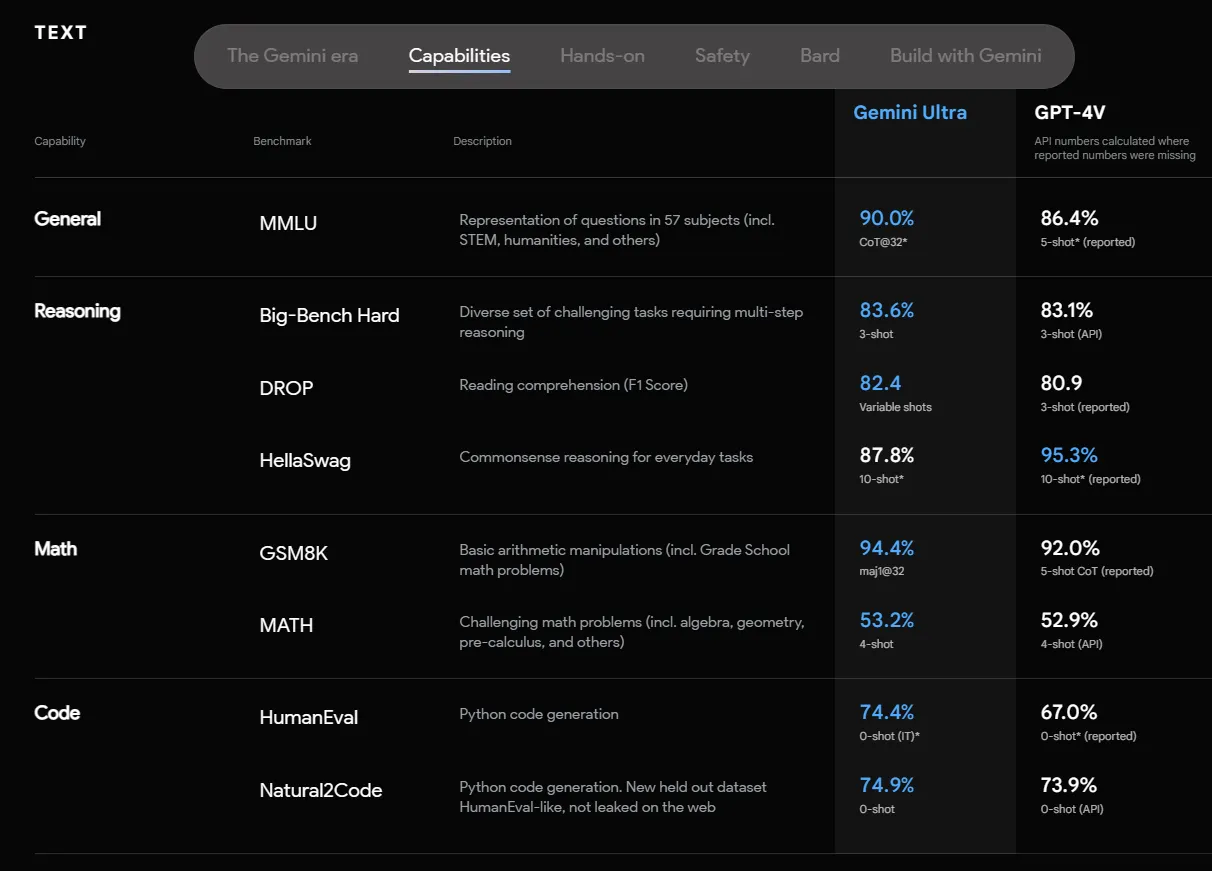
The most advanced version, Gemini Ultra, delivered strong results across several popular benchmarks, matching or exceeding human performance in some cases. For example, it set new records on 30 out of 32 benchmarks in the MMLU exam, which spans a variety of academic subjects.
A key feature of Gemini is its "natively multimodal" training, allowing it to process multiple data types like text, images, and audio as inputs and outputs. This approach means that the model was built and trained from scratch to understand different inputs, rather than the result of bringing discrete modes and modules together later.
The most popular multimodal AIs of today follow the latter roadmap. For example, ChatGPT combines GPT-4 Turbo with Dall-E 3 to process text to generate images, GPT-4 Vision to process images, and a special coding module for calculations. As a result, the LLM is relegated to the role of coordinator between different AI models that cannot independently understand the full nature of a specific problem.
This limitation can also lead to vulnerabilities like prompt injection. For example, techniques to circumvent safety controls in place for text prompts by writing or printing it on a piece of paper, taking a photo, and asking the visual module to process it.
In contrast, early qualitative evaluations of Gemini reveal its remarkable ability to perform crossmodal reasoning. For instance, in educational settings, Gemini can understand complex problems in physics, converting them into mathematical formulas, and providing correct solutions. This ability opens up transformative pathways in education as well as other fields.
Traditional LLMs are typically not very good at math, so the reasoning capabilities of the Gemini family of multimodal LLMs deserve some attention.
In another benchmark test focused on multimodal language understanding, Gemini Ultra achieved over 90% accuracy, surpassing other existing models. Google claims that human preference tests also showed a clear preference for Gemini over models like PaLM 2 in areas like creative writing.
The smaller service, Gemini Nano, is engineered for on-device efficiency, excelling in summarization, reading comprehension, and various reasoning tasks. Despite its smaller size, Gemini Nano shows remarkable performance in comparison to the larger Gemini Pro model. This means Gemini might become the preferred AI to power mobile assistants that can or must work offline.
Gemini looks like a very strong debut, by any measure. And as Google’s AI capabilities are improved, their versatility could enable new applications across many domains. For now, however, further real-world testing is required to determine its realistic performance levels.
Users can test a fine-tuned version of Gemini Pro today with Bard. Gemini Ultra will be released next year in a new version of Google’s chatbot called Bard Advanced. Google ultimately expects to launch Gemini in over 170 different languages and use the technology to power its Pixel Lineup and the Search Generative Experience.