

In the race to develop advanced artificial intelligence, not all large language models are created equal. Two new studies reveal striking differences in the capabilities of popular systems like ChatGPT when put to the test on complex real-world tasks.
According to researchers at Purdue University, ChatGPT struggles with even basic coding challenges. The team evaluated ChatGPT's responses to over 500 questions on Stack Overflow, an online community for developers and programmers, on topics like debugging and API usage.
"Our analysis shows that 52% of ChatGPT-generated answers are incorrect and 77% are verbose," the researchers wrote. "However, ChatGPT answers are still preferred 39.34% of the time due to their comprehensiveness and well-articulated language style."
In contrast, a study from UCLA and the Pepperdine University of Malibu demonstrates ChatGPT's prowess at answering difficult medical exam questions. When quizzed on over 850 multiple-choice questions in nephrology, an advanced specialty within internal medicine, ChatGPT scored 73% —similar to the passing rate for human medical residents.
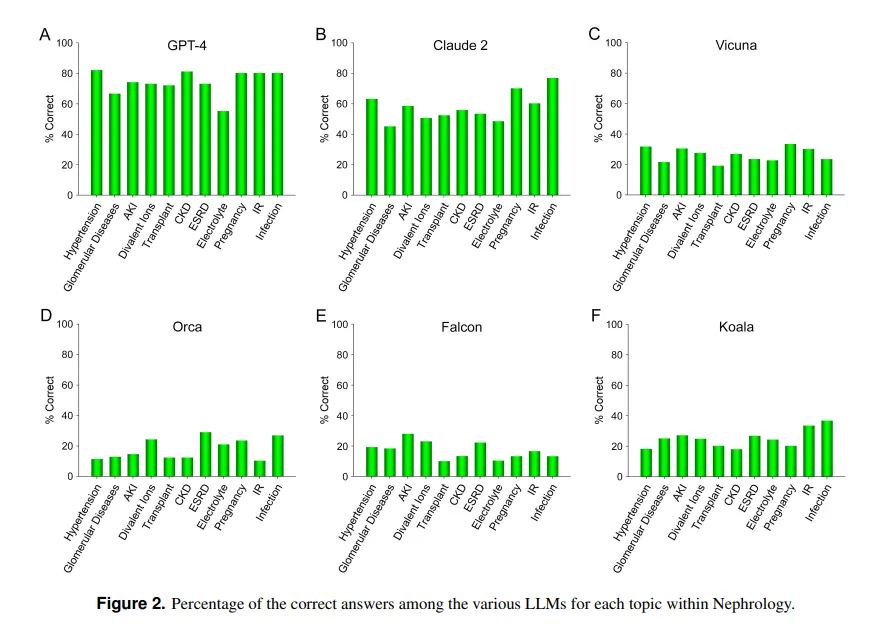
"The demonstrated current superior capability of GPT-4 in accurately answering multiple-choice questions in Nephrology points to the utility of similar and more capable AI models in future medical applications," the UCLA team concluded.
Anthropic’s Claude AI was the second best LLM with 54.4% correct answers. The team evaluated other open-source LLMs but they were far from acceptable, with the best score being 25.5% achieved by Vicuna.
So why does ChatGPT excel at medicine but flounder at coding? The machine learning models have different strengths, notes MIT computer scientist Lex Fridman. Claude, the model behind ChatGPT’s medical knowledge, received additional proprietary training data from its maker Anthropic. OpenAI’s ChatGPT relied only on publicly available data. AI models do great things if properly traiend with huge amounts of data, even better than most other models.
However, an AI won’t be able to act properly outside the parameters it was trained on, so it will try to create content with no prior knowledge of it, which results in what's known as hallucinations. If the dataset of an AI model does not include a specific content, it will not be able to yield good results in that area.
As the UCLA researchers explained, "Without negating the importance of the computational power of specific LLMs, the lack of free access to training data material that is currently not in public domain will likely remain one of the obstacles to achieving further improved performance for the foreseeable future."
ChatGPT clunking at coding aligns with other assessments. As Decrypt previously reported, researchers at Stanford and UC Berkeley found ChatGPT’s math and visual reasoning skills declined sharply between March and June 2022. Though initially adept at primes and puzzles, by summer it scored only 2% on key benchmarks.
So while ChatGPT can play doctor, it still has much to learn before becoming an ace programmer. But it’s not far from reality, after all, how many doctors do you know that are also proficient hackers?