

En Resumen
- Xiaomi lanzó MiMo-V2.5-Pro-UltraSpeed, alcanzando más de 1.000 tokens por segundo en un nodo de 8 GPUs estándar.
- El sistema combina cuantificación FP4, decodificación especulativa DFlash y el motor TileRT para lograr la velocidad.
- El modelo iguala a Claude Opus en benchmarks de codificación pero cuesta $0.43 por millón de tokens frente a $5 de Opus.
La mayoría de las personas conocen a Xiaomi como la marca china de teléfonos. Aquella que fabrica scooters eléctricos baratos y purificadores de aire. No es precisamente la empresa de la que esperarías que rompiera un importante récord de velocidad de inferencia de IA en una mañana de lunes.
Y sin embargo. Xiaomi acaba de lanzar MiMo-V2.5-Pro-UltraSpeed, un modo de servicio para su buque insignia de un billón de parámetros que alcanza más de 1,000 tokens por segundo, llegando a cerca de 1,200 en demostraciones.
Los parámetros son los pesos numéricos internos que definen cómo piensa un modelo, cuantos más tengas, más complejos serán los patrones que puede reconocer. Los tokens son los fragmentos de texto que el modelo lee y escribe, aproximadamente tres cuartos de palabra en promedio.
Xiaomi lo logró en un único nodo de hardware estándar con 8 GPU. Hardware convencional, sin chips personalizados. Esto cambia el cálculo sobre quién puede realmente implementar este tipo de velocidad en producción.
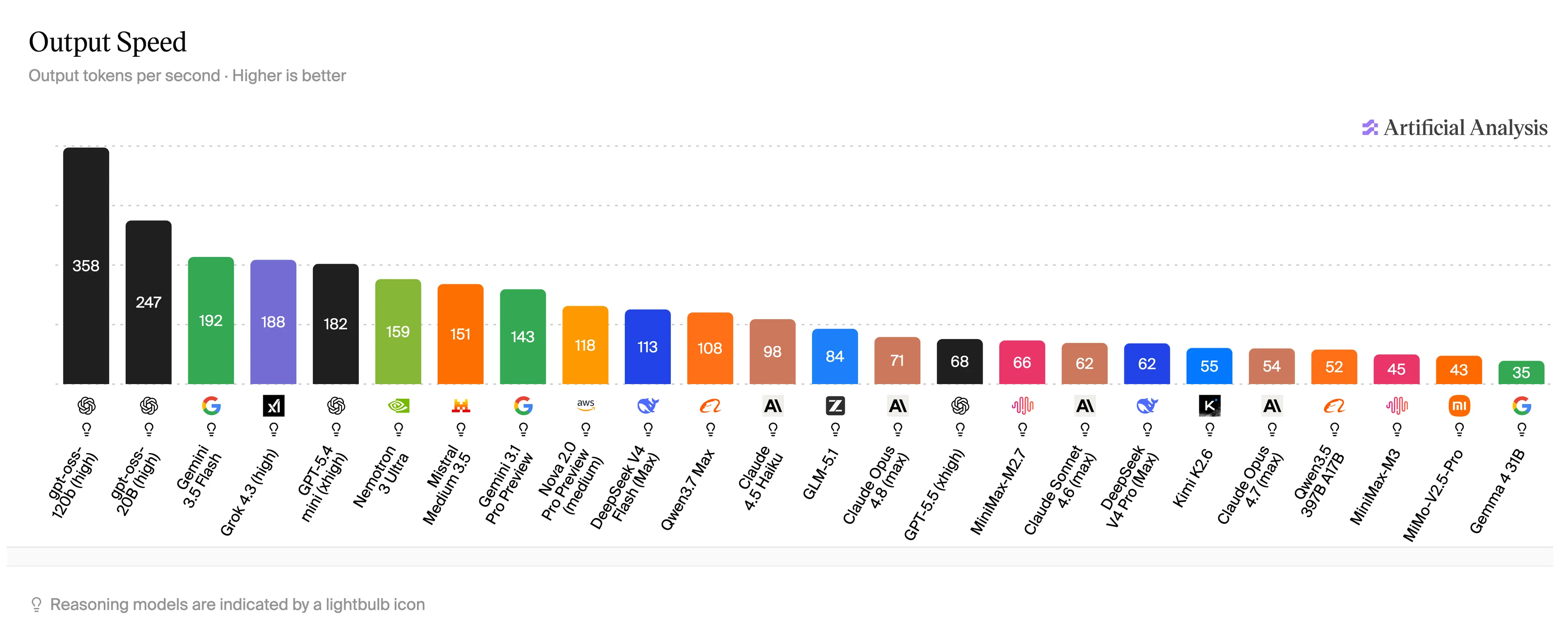
Para poner ese número en términos humanos: según Artificial Analysis, GPT-5.5—con el que la mayoría de los usuarios de ChatGPT están interactuando en realidad—se sitúa en 68. Claude Opus 4.6 alcanza alrededor de 71 con el modelo de gama baja, Haiku, llegando a 98 tokens por segundo. Gemini Flash alcanza los 192 tokens por segundo. MiMo-V2.5-Pro-UltraSpeed alcanza los 1,000, en un modelo que coincide con Opus en pruebas de codificación.
Cerebras y Groq construyeron negocios enteros en torno a este problema. Cerebras diseñó un chip a escala de oblea del tamaño de un plato de cena, con 44GB de memoria en el chip para eliminar el cuello de botella de ancho de banda que ralentiza la inferencia de GPU. Alcanzó 969 tokens por segundo en el Llama 3.1 405B de Meta—impresionante, pero se trata de un modelo de 405 mil millones de parámetros, menos de la mitad del tamaño de MiMo-V2.5-Pro. La arquitectura de la Unidad de Procesamiento de Lenguaje personalizada de Groq alcanza entre 300 y 750 tokens por segundo dependiendo del modelo.
Ni se ejecuta en hardware que puedas alquilar de AWS esta noche.
Xiaomi lo hizo en GPUs de mercancía a través de software solamente, una combinación de trucos a nivel de modelo y un motor de inferencia construido a propósito llamado TileRT.
¿Qué está sucediendo realmente bajo el capó?
Dos técnicas impulsan la velocidad. La primera técnica se llama Cuantificación FP4: en lugar de ejecutar el modelo con precisión numérica completa de 8 bits o 16 bits, Xiaomi reduce las capas expertas, que conforman la mayor parte de los 1 billón de parámetros, a 4 bits. La huella de memoria disminuye, la presión sobre el ancho de banda disminuye, la velocidad aumenta. La única pega suele ser una pequeña degradación de calidad. La solución de Xiaomi es quirúrgica: solo las capas expertas se comprimen, todo lo demás se mantiene a plena precisión. Con este enfoque, la pérdida de calidad se describe como cercana a cero.
El segundo es la decodificación especulativa DFlash. La decodificación especulativa normal tiene un pequeño modelo de borrador que adivina los próximos tokens, luego el gran modelo los verifica en paralelo. DFlash salta por completo el borrador secuencial: llena todo un bloque de posiciones enmascaradas en un solo pase hacia adelante. En tareas de codificación, el gran modelo acepta un promedio de 6.3 de 8 tokens propuestos por ronda de verificación. Eso son seis tokens confirmados en un solo paso en lugar de uno.
TileRT lo une todo. Mantiene todo el pipeline de cálculo continuamente residente dentro de la GPU, sin sobrecarga de lanzamiento por operador, ni brechas de ejecución.
Xiaomi llama a este enfoque "diseño de códigos de sistema de modelo extremo", y la frase es precisa: Ninguna técnica por sí sola llega a 1,000 tokens por segundo, pero la sinergia entre todos los enfoques lo logra.
MiMo-V2.5-Pro es un modelo de nivel fronterizo. Cubrimos el lanzamiento del V2.5 Pro en abril: coincide con Claude Opus en la mayoría de los benchmarks de codificación y funciona aproximadamente a $0.43 de entrada / $0.87 de salida por millón de tokens. Opus cuesta $5 de entrada / $25 de salida por millón de tokens.
UltraSpeed acelera ese mismo modelo exacto de MiMo V2.5 Pro, no una versión simplificada.
La inferencia lo suficientemente rápida cambia la forma en que puedes usar un modelo. Puedes ejecutar docenas de caminos de razonamiento en paralelo en lugar de esperar una respuesta. La detección de fraudes, la generación de señales de trading, los bucles de agentes en tiempo real, todos estos tienen restricciones de latencia estrictas que 60 tokens por segundo no pueden cumplir. A 1,000 tokens por segundo, sí pueden.
Xiaomi está fijando el precio de la velocidad a 3 veces la tarifa estándar de MiMo-V2.5-Pro para aproximadamente 10 veces la salida. La prueba de API se ejecuta del 9 al 23 de junio, basada en aplicaciones, con prioridad dada a desarrolladores empresariales y profesionales. El punto de control FP4-DFlash ya está disponible en código abierto en Hugging Face para pruebas comunitarias.